LangSmith 提供了一系列工具来管理和操作您的数据集。本页介绍数据集操作,包括:
您还将学习如何将实验中的筛选后的轨迹导出回数据集,以便进行进一步分析和迭代。
版本化数据集
在 LangSmith 中,数据集是版本化的。这意味着每次在数据集中添加、更新或删除示例时,都会创建数据集的新版本。
创建数据集的新版本
每当您在数据集中添加、更新或删除示例时,都会创建数据集的一个新版本。这使您可以跟踪数据集随时间的变化,并了解数据集的演变过程。
默认情况下,版本由更改的时间戳定义。当您在示例选项卡中点击数据集的特定版本(按时间戳)时,您将看到该时间点数据集的状态。
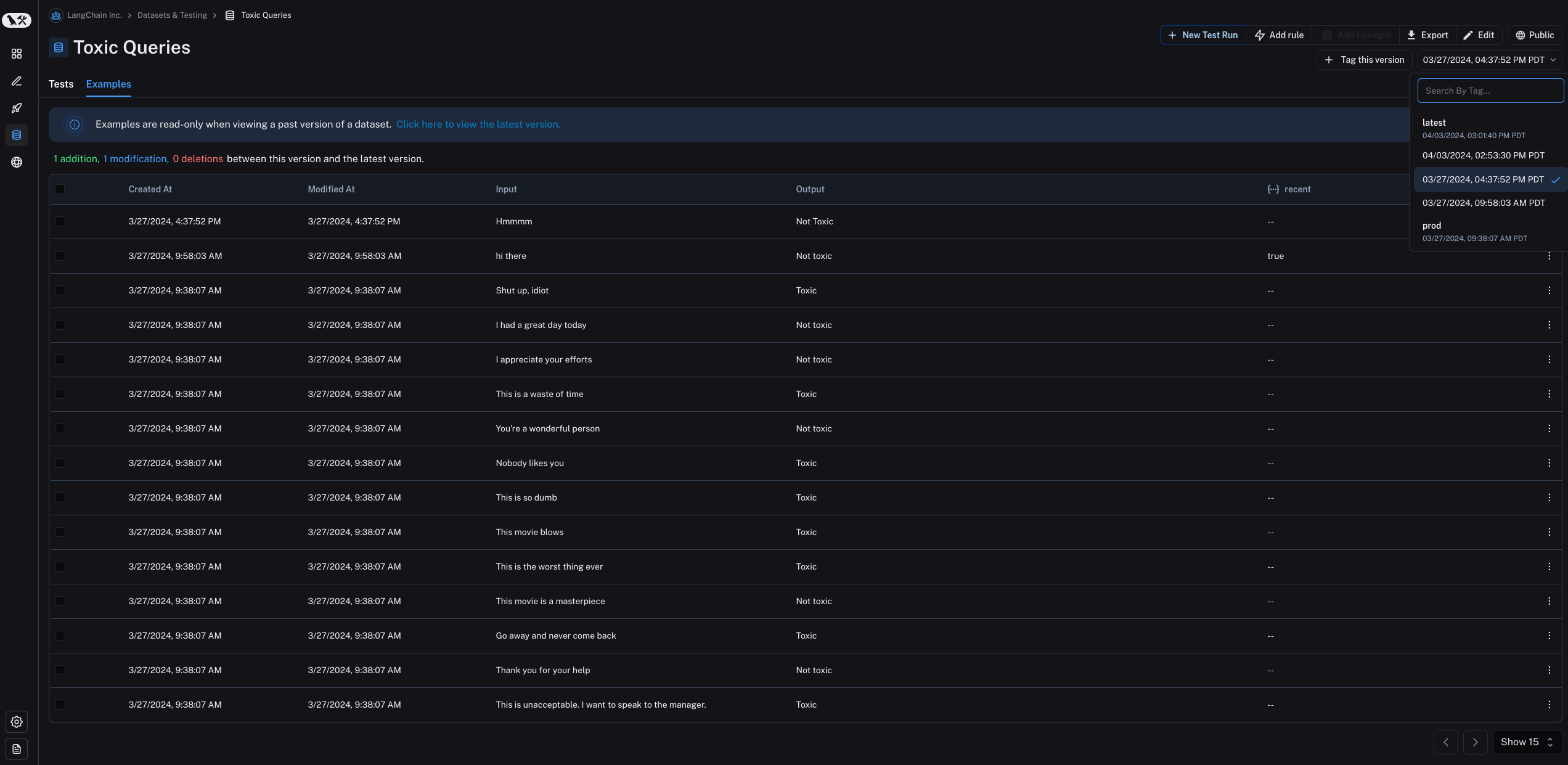 请注意,在查看数据集的过去版本时,示例是只读的。您还将看到此版本数据集与最新版本数据集之间的操作。
请注意,在查看数据集的过去版本时,示例是只读的。您还将看到此版本数据集与最新版本数据集之间的操作。
默认情况下,示例选项卡中显示的是数据集的最新版本,而测试选项卡中显示的是所有版本的实验。
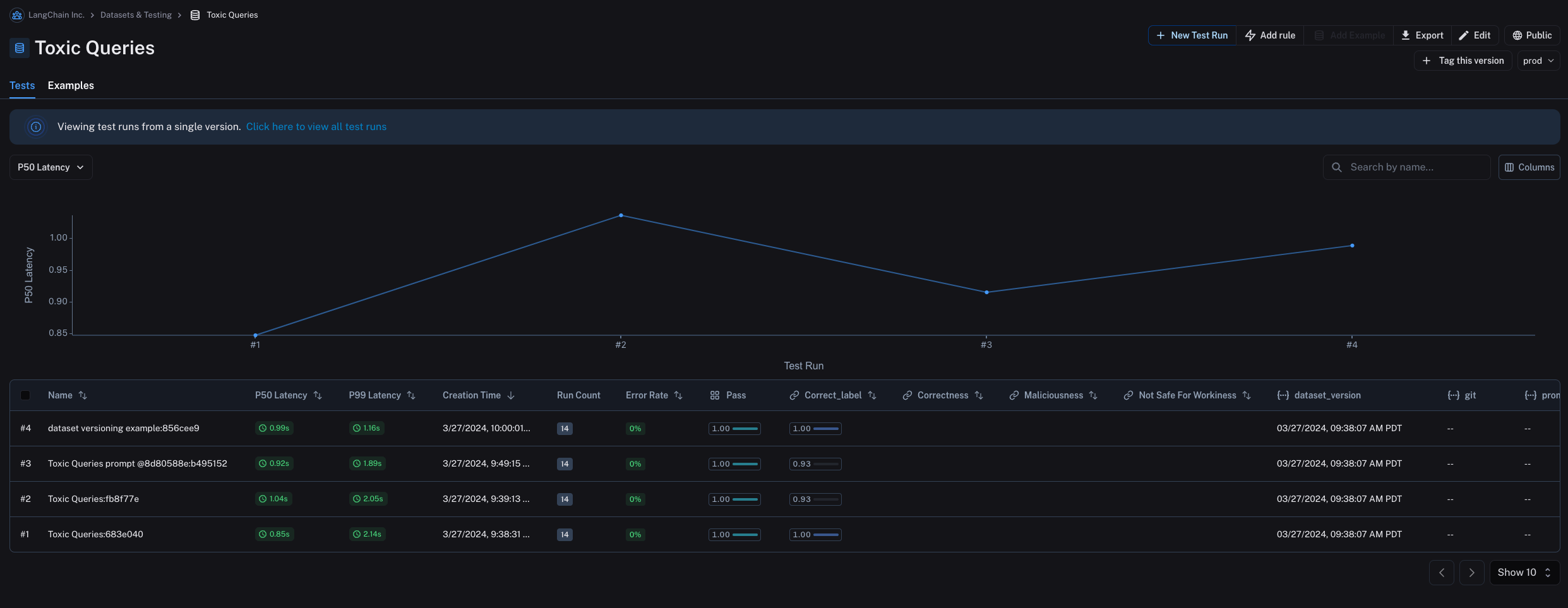
标记版本
您还可以标记数据集的版本,为其提供更易于人类阅读的名称,这对于标记数据集历史中的重要里程碑非常有用。
例如,您可以将数据集的某个版本标记为“prod”,并用它来针对您的 LLM 流水线运行测试。
您可以在 UI 中通过点击示例选项卡中的 + 标记此版本 来标记数据集的版本。
 您也可以使用 SDK 标记数据集的版本。以下是如何使用 Python SDK 标记数据集版本的示例:
您也可以使用 SDK 标记数据集的版本。以下是如何使用 Python SDK 标记数据集版本的示例:
from langsmith import Client
from datetime import datetime
client = Client()
initial_time = datetime(2024, 1, 1, 0, 0, 0) # 您想要标记的版本的时间戳
# 您可以用语义名称(如 "prod")标记特定的数据集版本
client.update_dataset_tag(
dataset_name=toxic_dataset_name, as_of=initial_time, tag="prod"
)
在特定数据集版本上评估
在阅读本节之前,您可能会发现参考以下内容会有所帮助: 使用 list_examples
您可以使用 evaluate / aevaluate 传入一个可迭代的示例,以在数据集的特定版本上进行评估。使用 list_examples / listExamples 通过 as_of / asOf 从特定版本标签获取示例,并将其传入 data 参数。
from langsmith import Client
ls_client = Client()
# 假设实际输出有一个 'class' 键。
# 假设示例输出有一个 'label' 键。
def correct(outputs: dict, reference_outputs: dict) -> bool:
return outputs["class"] == reference_outputs["label"]
results = ls_client.evaluate(
lambda inputs: {"class": "Not toxic"},
# 在此传入筛选后的数据:
data=ls_client.list_examples(
dataset_name="Toxic Queries",
as_of="latest", # 在此指定版本
),
evaluators=[correct],
)
import { evaluate } from "langsmith/evaluation";
await evaluate((inputs) => labelText(inputs["input"]), {
data: langsmith.listExamples({
datasetName: datasetName,
asOf: "latest",
}),
evaluators: [correctLabel],
});
import com.langchain.smith.models.examples.ExampleListParams;
ExampleListParams listParams = ExampleListParams.builder()
.datasetId(datasetId)
.asOf("latest")
var examples = client.examples().list(listParams);
在数据集的拆分/筛选视图上评估
在阅读本节之前,您可能会发现参考以下内容会有所帮助: 在数据集的筛选视图上评估
您可以使用 list_examples / listExamples 方法获取数据集的子集示例以进行评估。
一个常见的工作流程是获取具有特定元数据键值对的示例。
from langsmith import evaluate
results = evaluate(
lambda inputs: label_text(inputs["text"]),
data=client.list_examples(dataset_name=dataset_name, metadata={"desired_key": "desired_value"}),
evaluators=[correct_label],
experiment_prefix="Toxic Queries",
)
import { evaluate } from "langsmith/evaluation";
await evaluate((inputs) => labelText(inputs["input"]), {
data: langsmith.listExamples({
datasetName: datasetName,
metadata: {"desired_key": "desired_value"},
}),
evaluators: [correctLabel],
experimentPrefix: "Toxic Queries",
});
import com.langchain.smith.models.examples.ExampleListParams;
ExampleListParams listParams = ExampleListParams.builder()
.datasetId(datasetId)
.metadata("{\"desired_key\":\"desired_value\"}")
.build();
var examples = client.examples().list(listParams);
在数据集拆分上评估
您可以使用 list_examples / listExamples 方法在数据集的一个或多个拆分上进行评估。splits 参数接受您想要评估的拆分列表。
from langsmith import evaluate
results = evaluate(
lambda inputs: label_text(inputs["text"]),
data=client.list_examples(dataset_name=dataset_name, splits=["test", "training"]),
evaluators=[correct_label],
experiment_prefix="Toxic Queries",
)
import { evaluate } from "langsmith/evaluation";
await evaluate((inputs) => labelText(inputs["input"]), {
data: langsmith.listExamples({
datasetName: datasetName,
splits: ["test", "training"],
}),
evaluators: [correctLabel],
experimentPrefix: "Toxic Queries",
});
import com.langchain.smith.models.examples.ExampleListParams;
import java.util.Arrays;
import java.util.List;
List<String> splits = Arrays.asList("test", "training");
ExampleListParams listParams = ExampleListParams.builder()
.datasetId(datasetId)
.splits(splits)
.build();
var examples = client.examples().list(listParams);
共享数据集
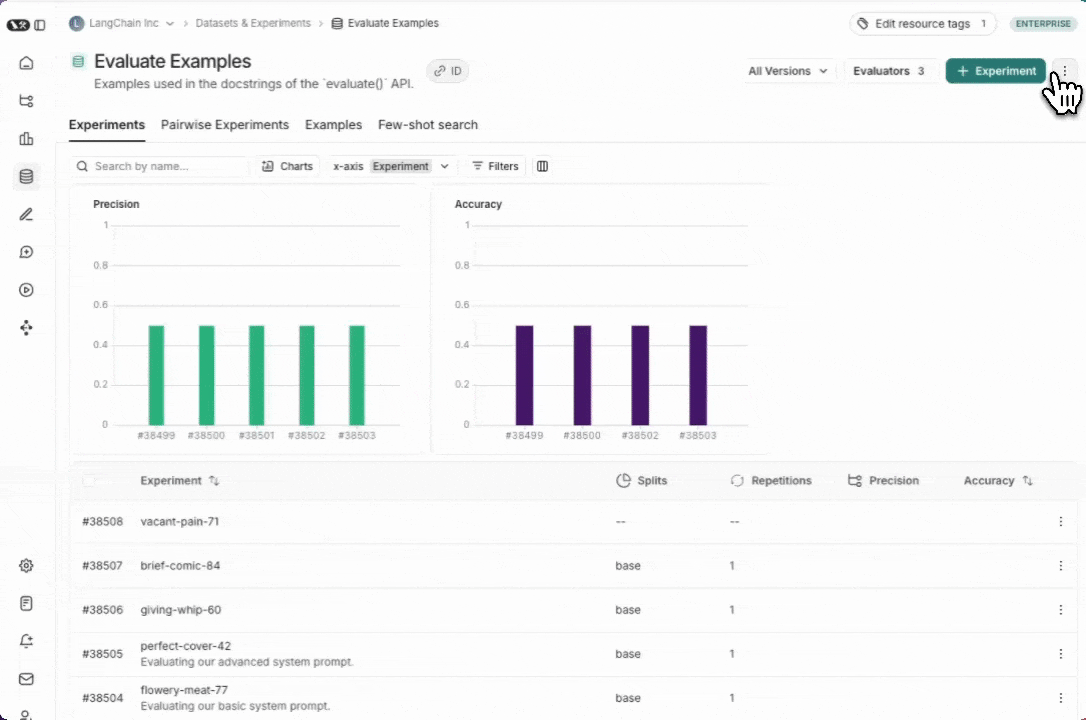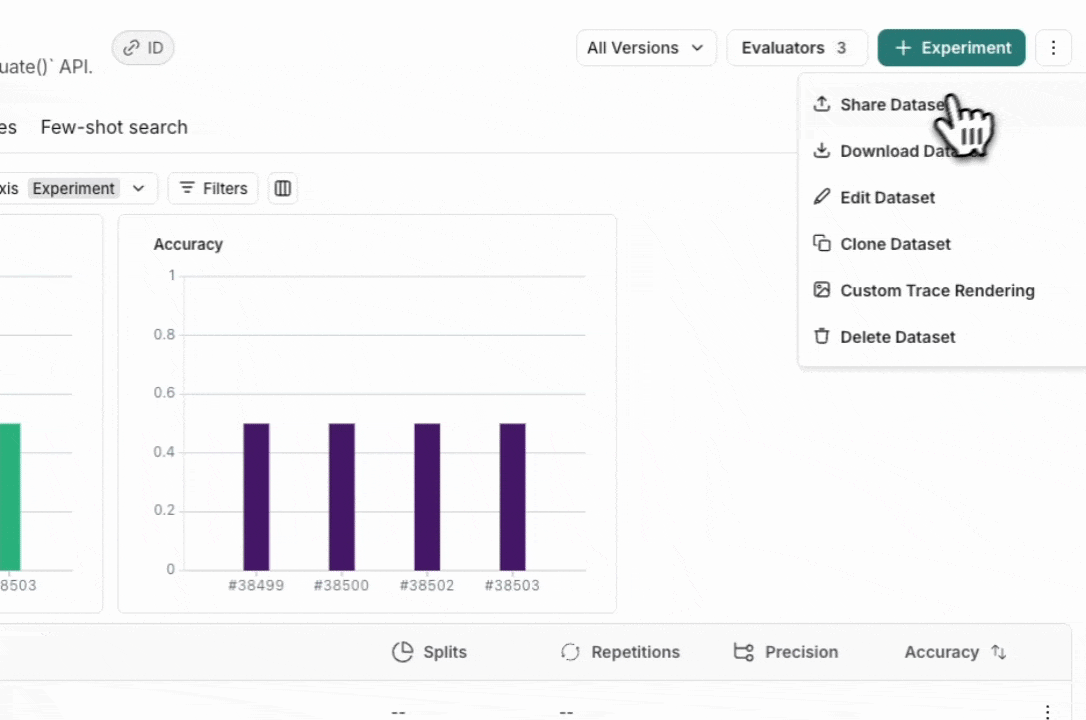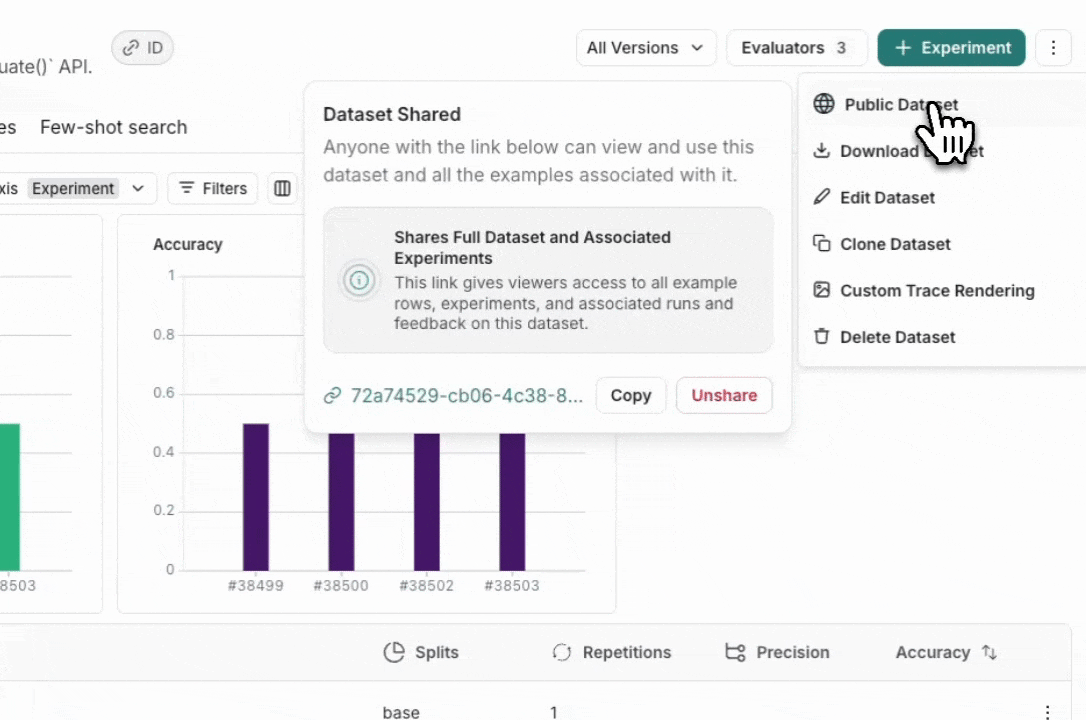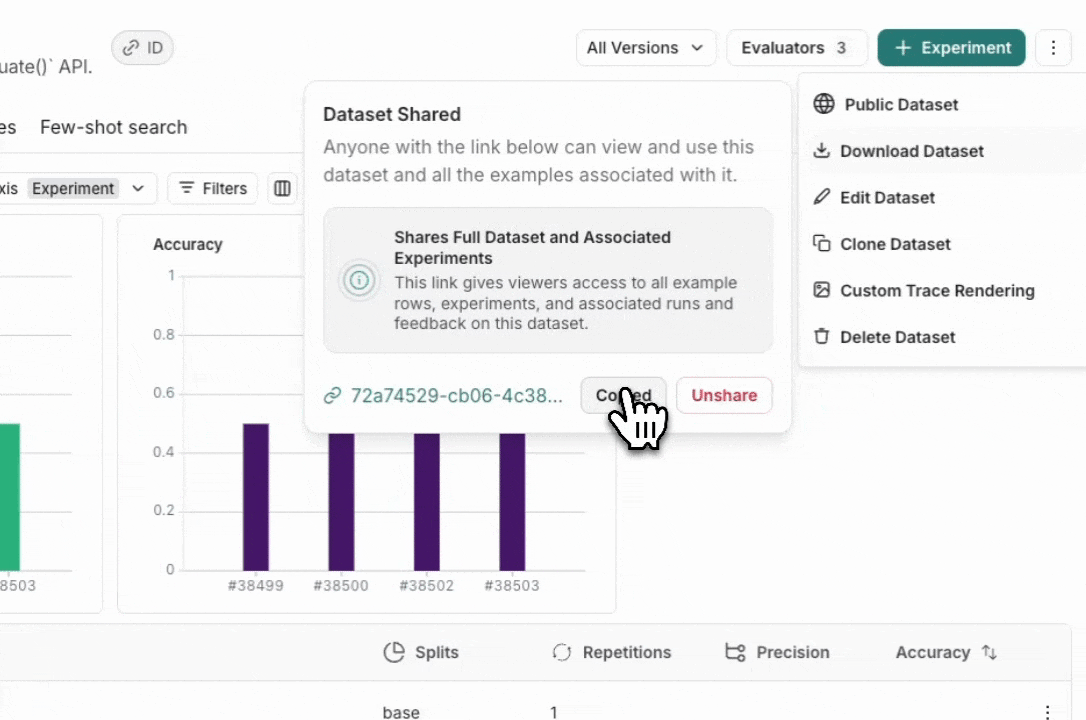
公开共享数据集
公开共享数据集将使数据集示例、实验及相关运行、以及此数据集上的反馈对任何拥有链接的人可访问,即使他们没有 LangSmith 账户。请确保您没有共享敏感信息。此功能仅在云托管版本的 LangSmith 中可用。
取消共享数据集
-
在任何公开共享的数据集的右上角点击公开,然后在对话框中点击取消共享,即可取消共享。

-
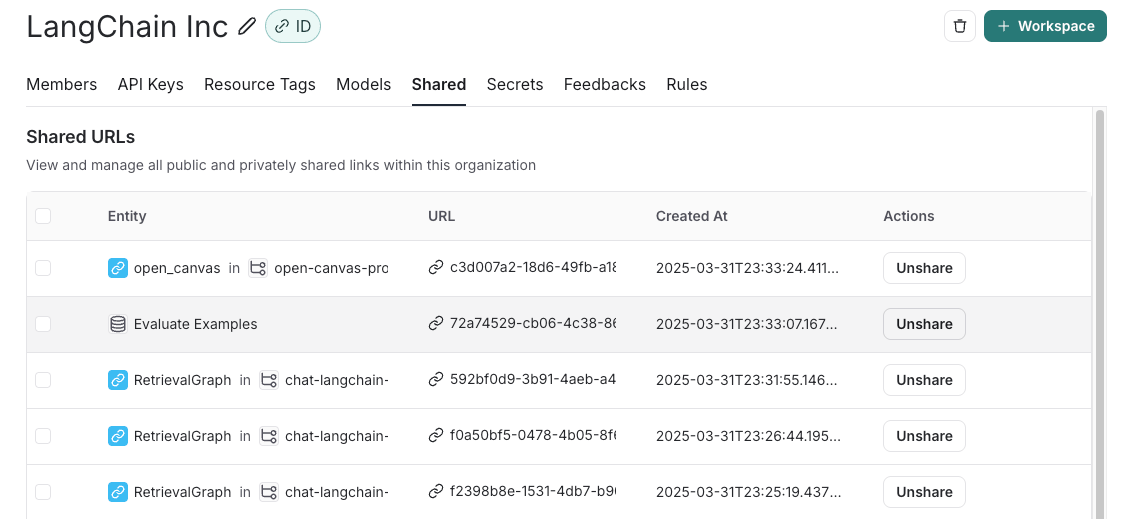
导航到您组织的公开共享数据集列表,通过点击设置 -> 共享的 URL 或此链接,然后点击您想要取消共享的数据集旁边的取消共享。
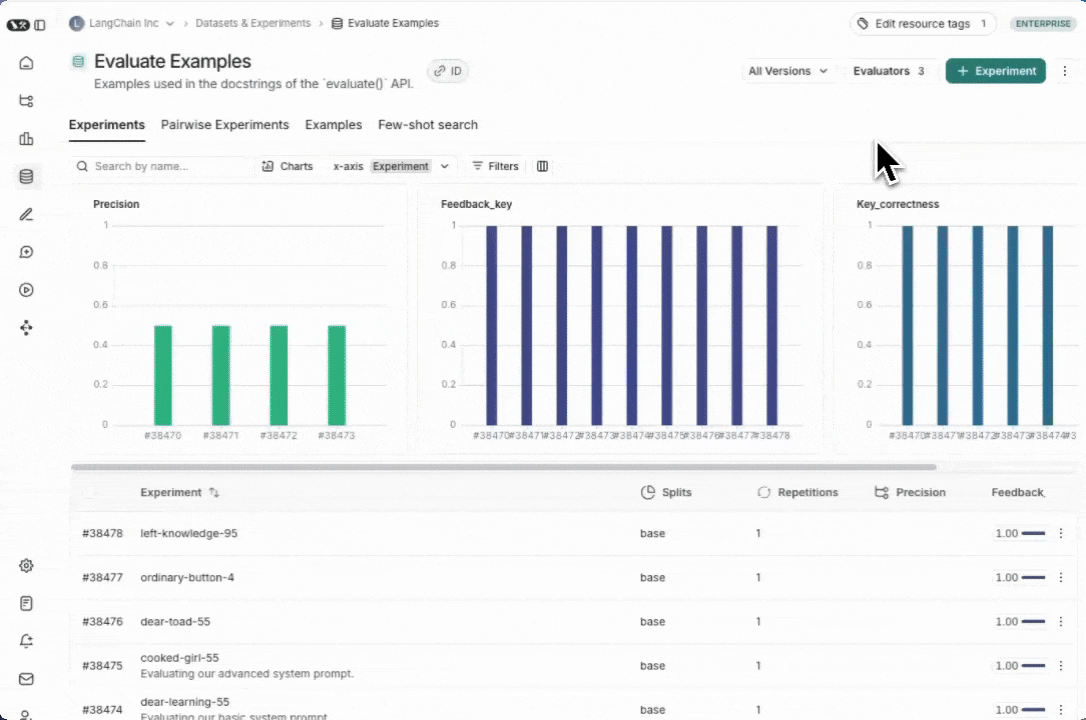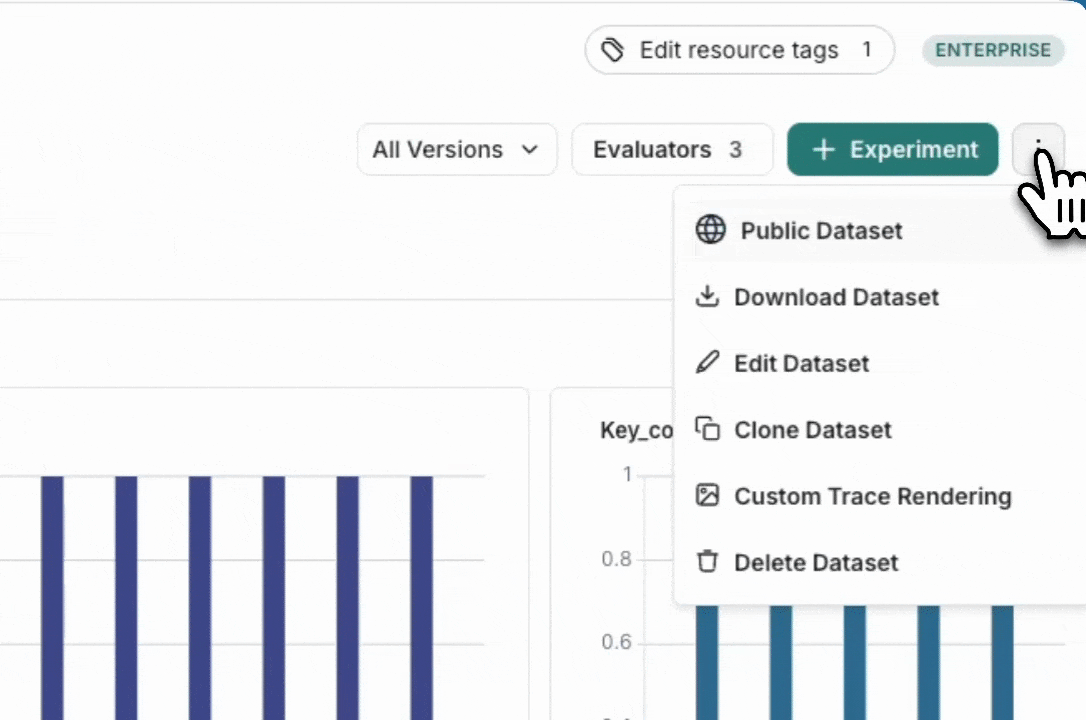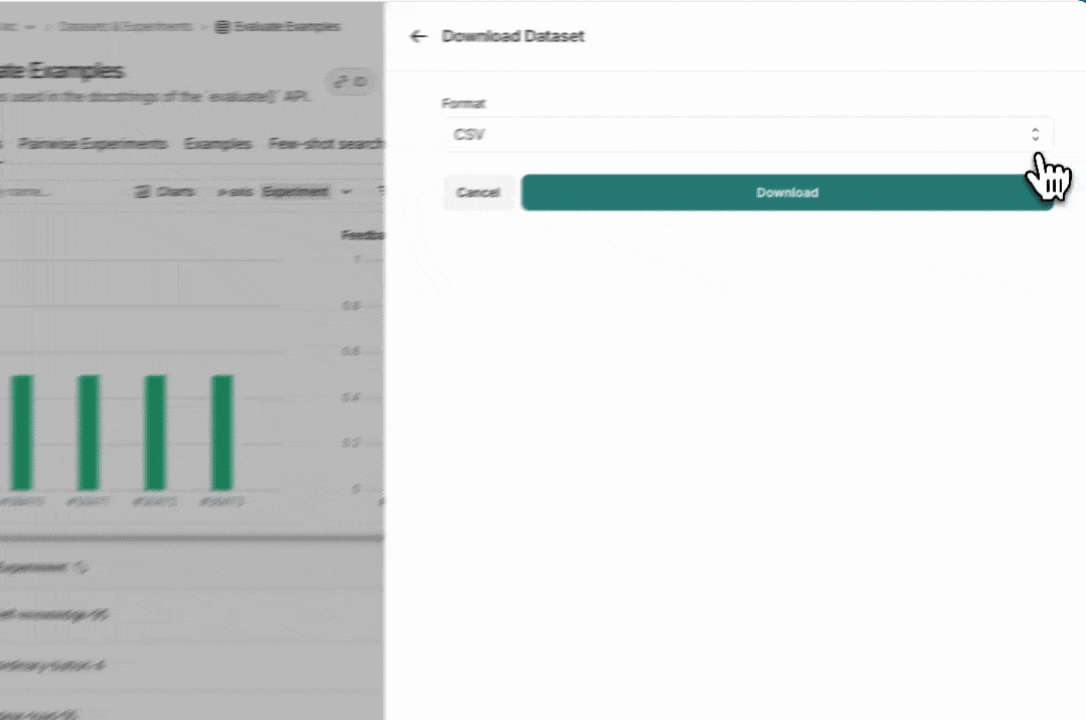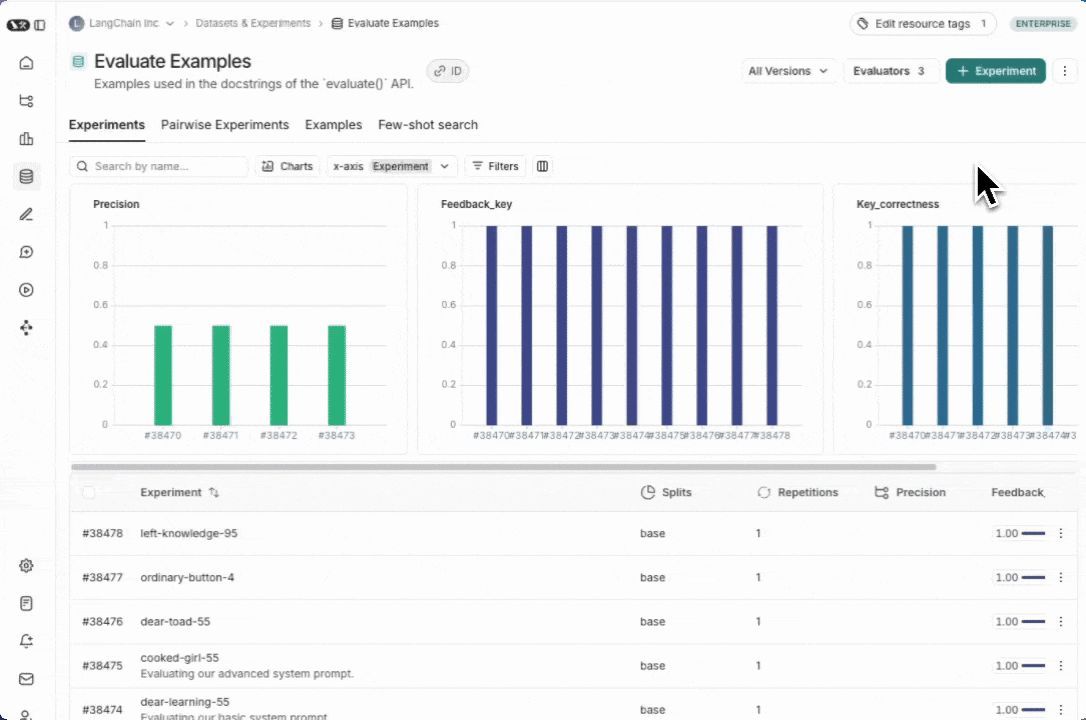
导出数据集
您可以从 LangSmith UI 将 LangSmith 数据集导出为 CSV、JSONL 或 OpenAI 的微调格式。
在数据集与实验选项卡中,选择一个数据集,点击 ⋮(页面右上角),然后点击下载数据集。
从实验导出筛选后的轨迹到数据集
在 LangSmith 中运行离线评估后,您可能希望将满足某些评估条件的轨迹导出到数据集。
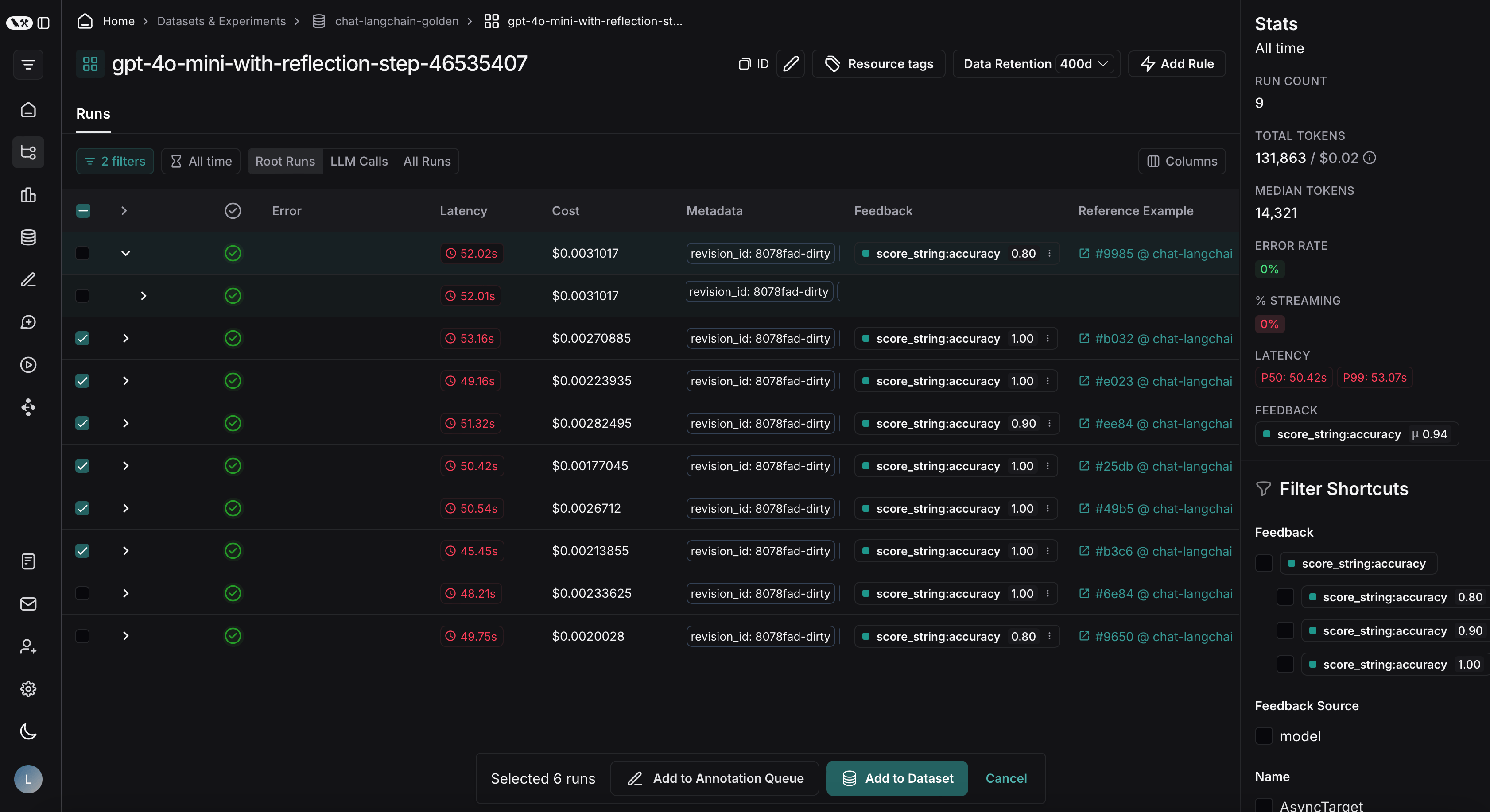
查看实验轨迹
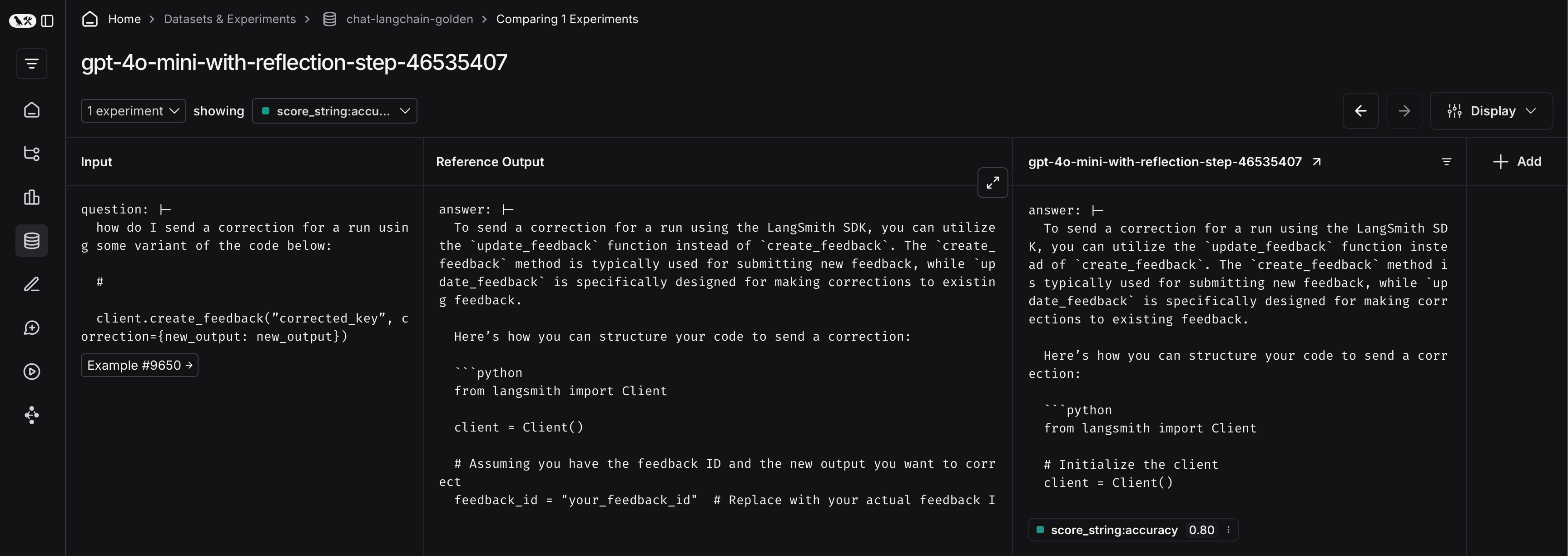 为此,首先点击实验名称旁边的箭头。这将引导您到一个包含实验生成的轨迹的项目。
为此,首先点击实验名称旁边的箭头。这将引导您到一个包含实验生成的轨迹的项目。
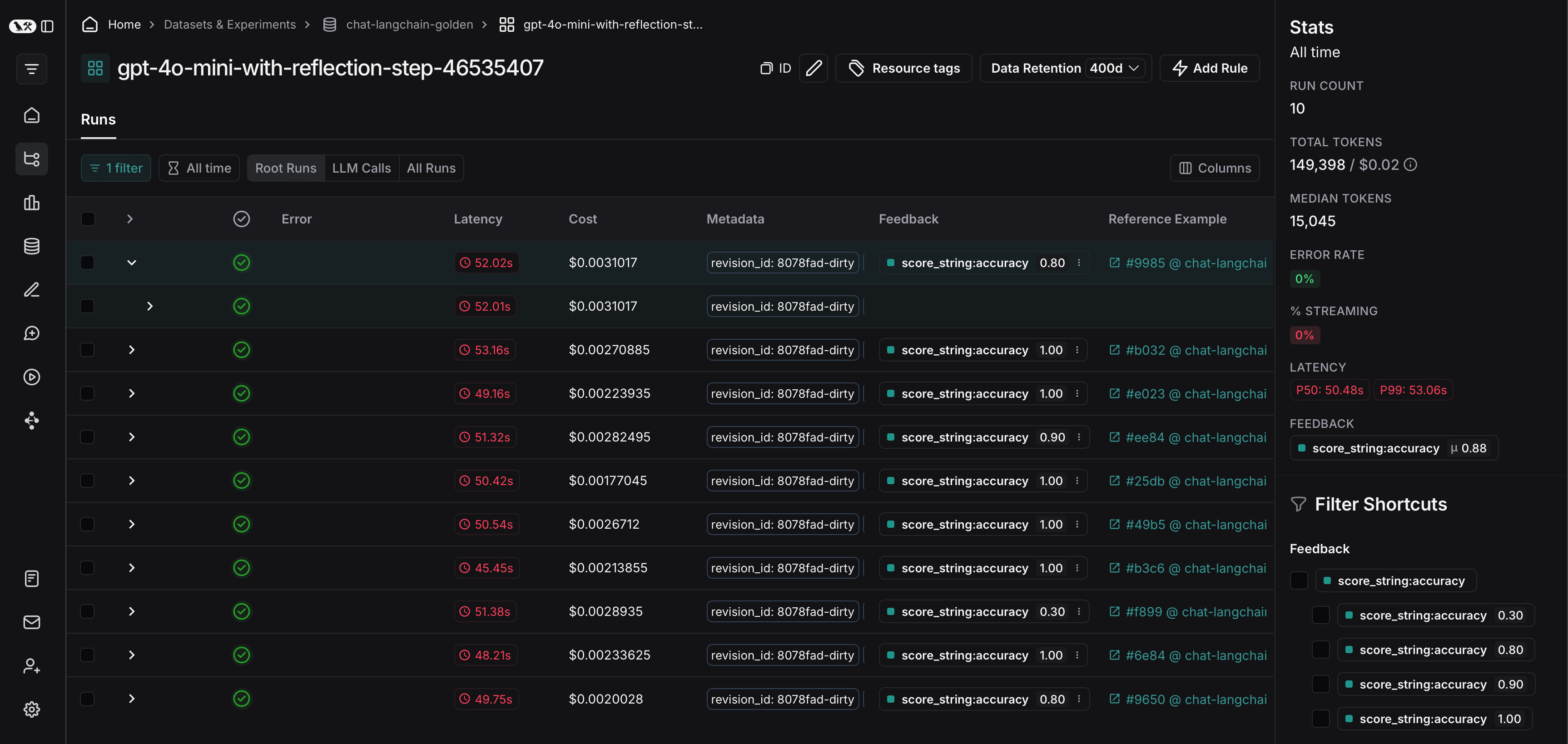 从那里,您可以根据评估条件筛选轨迹。在此示例中,我们筛选所有准确率得分大于 0.5 的轨迹。
从那里,您可以根据评估条件筛选轨迹。在此示例中,我们筛选所有准确率得分大于 0.5 的轨迹。
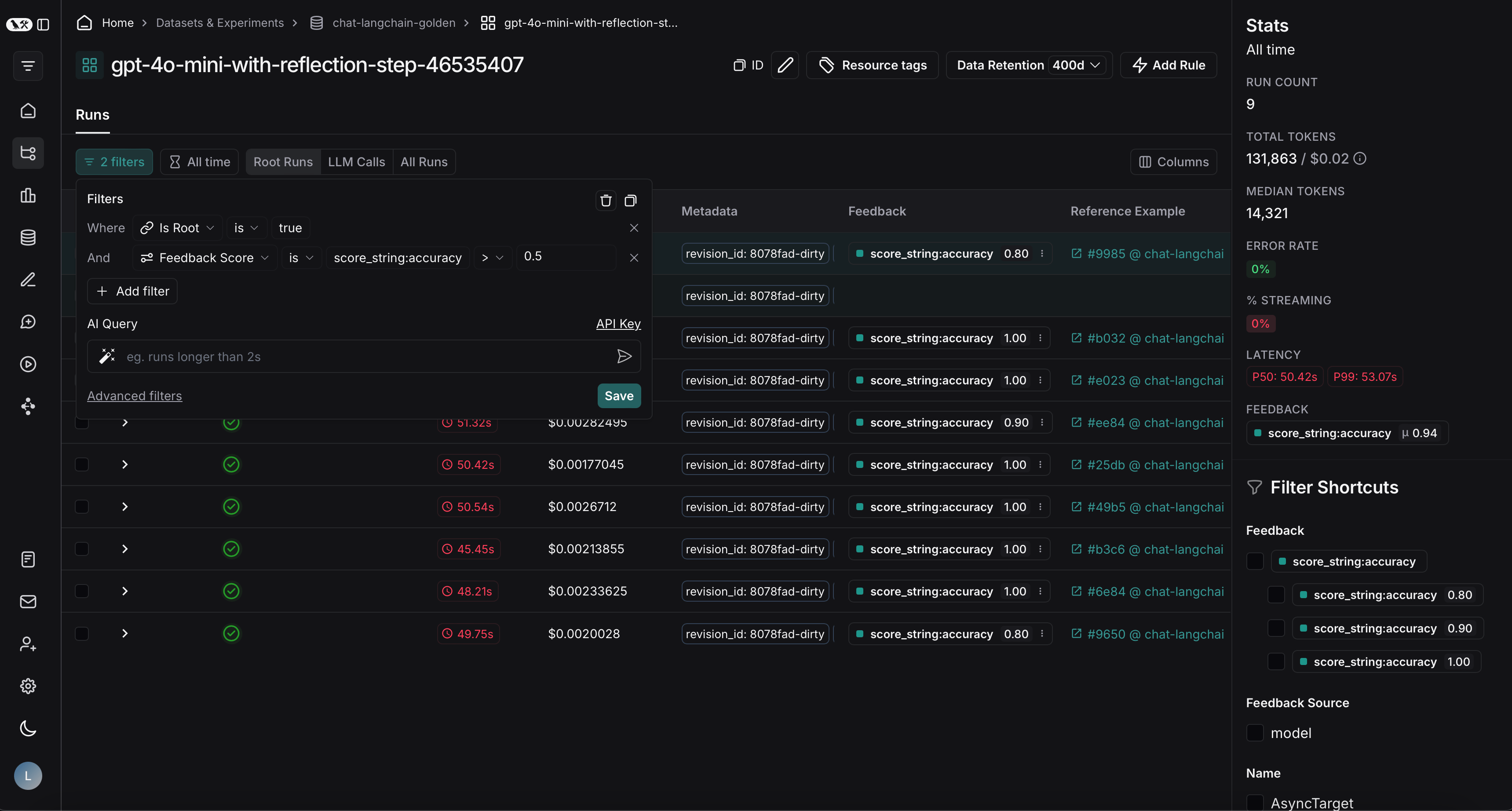 在项目上应用筛选器后,我们可以多选要添加到数据集的运行,然后点击添加到数据集。
在项目上应用筛选器后,我们可以多选要添加到数据集的运行,然后点击添加到数据集。