多智能体系统通过协调多个专用组件来处理复杂的工作流。然而,并非所有复杂任务都需要这种方法——一个配备了合适(有时是动态的)工具和提示的单智能体通常也能达到类似的效果。
为什么需要多智能体?
当开发者说他们需要“多智能体”时,他们通常是在寻求以下一种或多种能力:
- 上下文管理:提供专业知识,同时避免超出模型的上下文窗口限制。如果上下文是无限的且延迟为零,你可以将所有知识都塞进一个提示中——但现实并非如此,因此你需要模式来有选择地呈现相关信息。
- 分布式开发:允许不同团队独立开发和维护功能,并将它们组合成一个具有清晰边界的大型系统。
- 并行化:为子任务生成专门的执行者,并让它们并发执行以获得更快的结果。
当单个智能体拥有过多工具且在选择使用哪个工具时决策不佳时,当任务需要具有大量上下文(长提示和特定领域工具)的专业知识时,或者当你需要强制执行顺序约束(即某些能力只有在满足特定条件后才能解锁)时,多智能体模式尤其有价值。
多智能体设计的核心是**上下文工程**——决定每个智能体能看到什么信息。系统的质量取决于能否确保每个智能体都能访问其任务所需的正确数据。 | 模式 | 工作原理 |
|---|
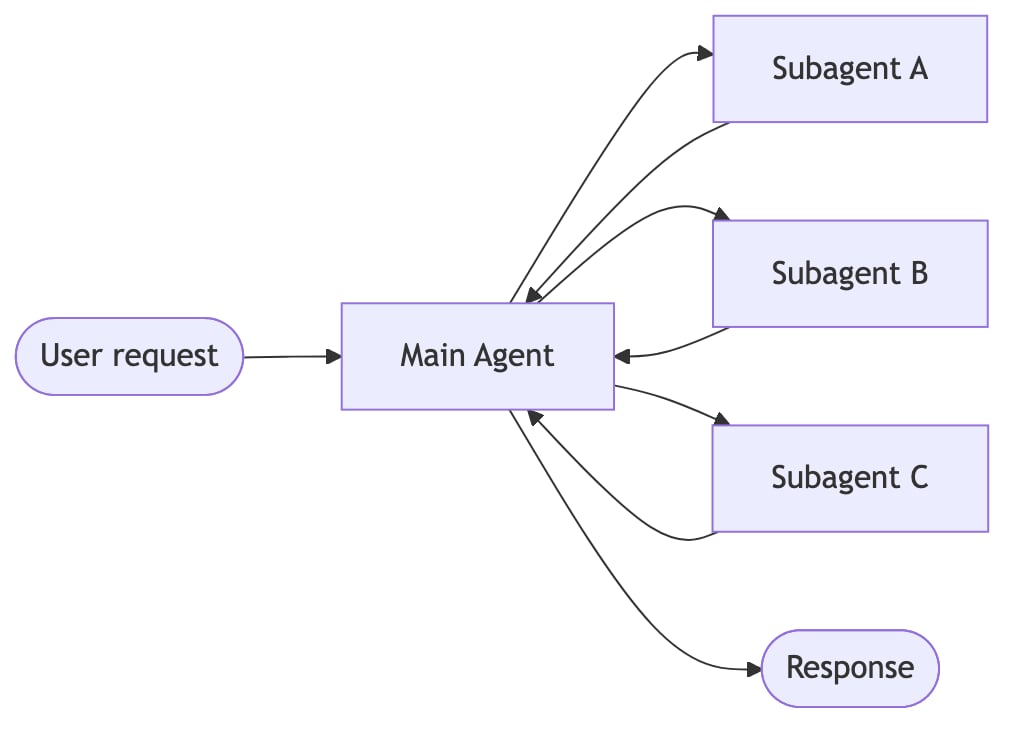
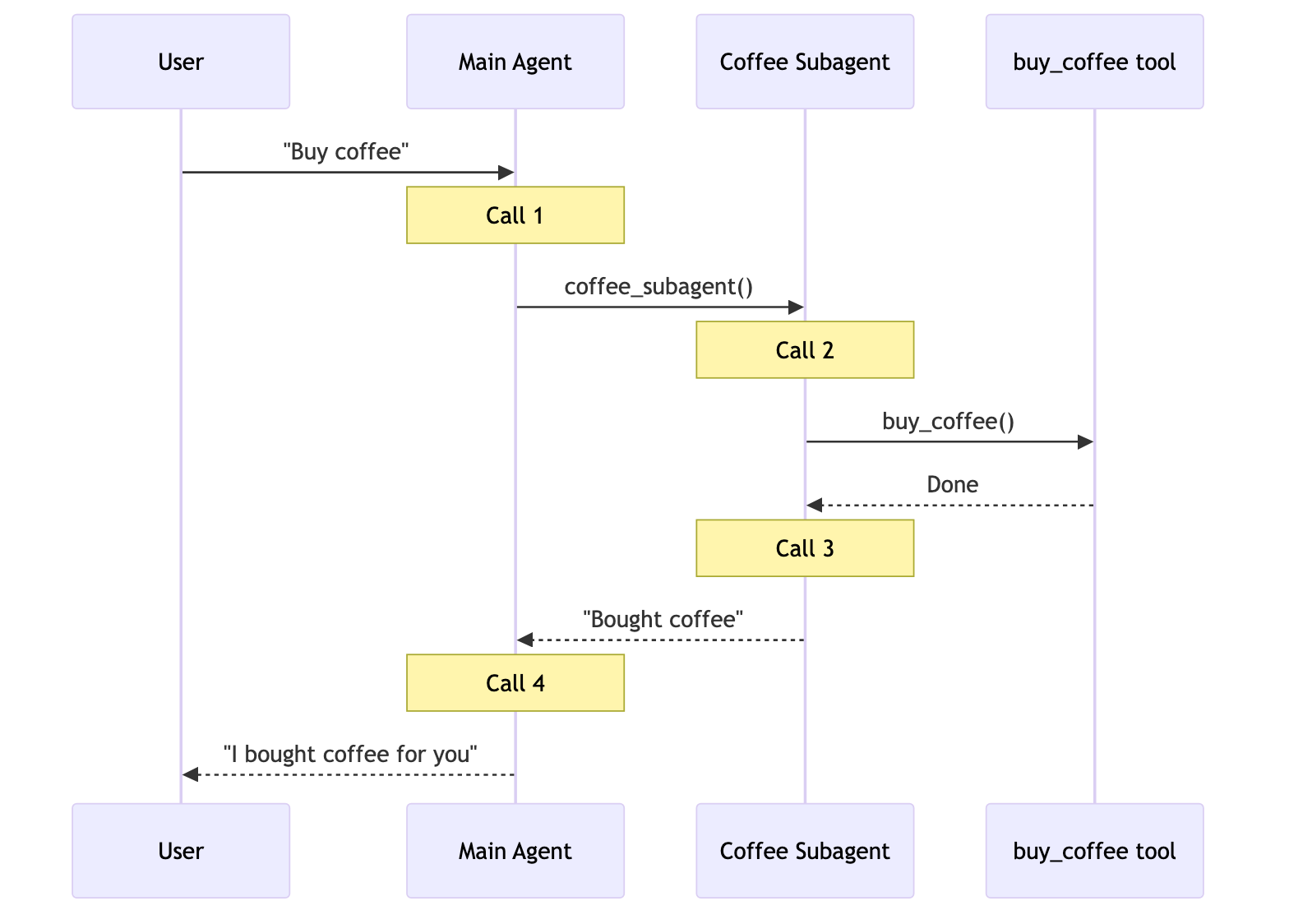
| 子智能体 | 一个主智能体将子智能体作为工具进行协调。所有路由都通过主智能体,由它决定何时以及如何调用每个子智能体。 |
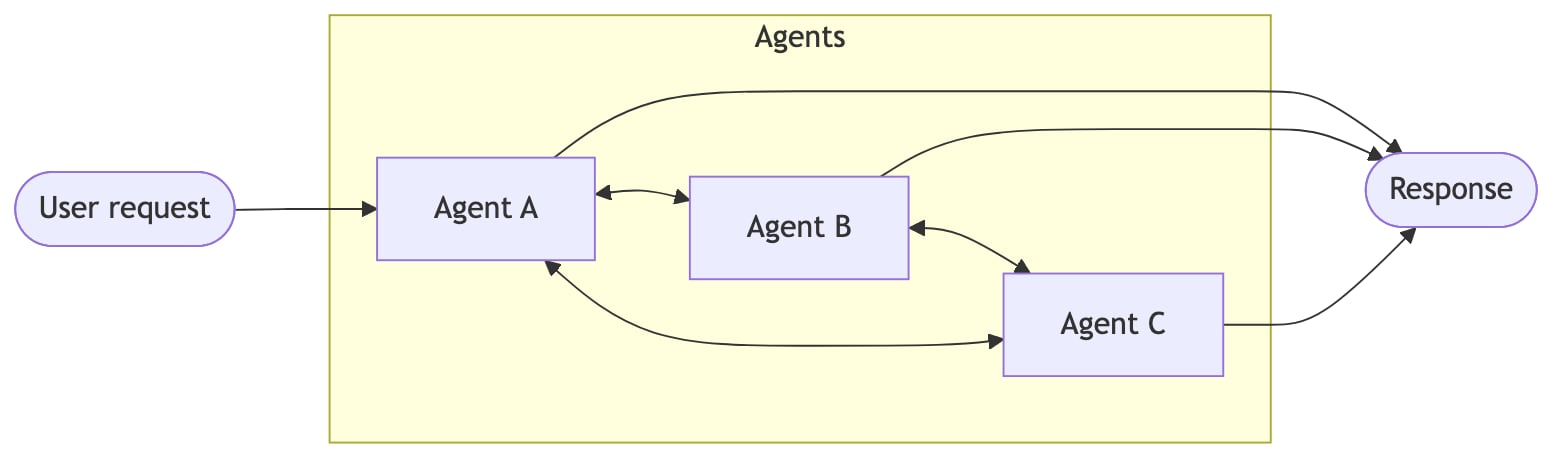
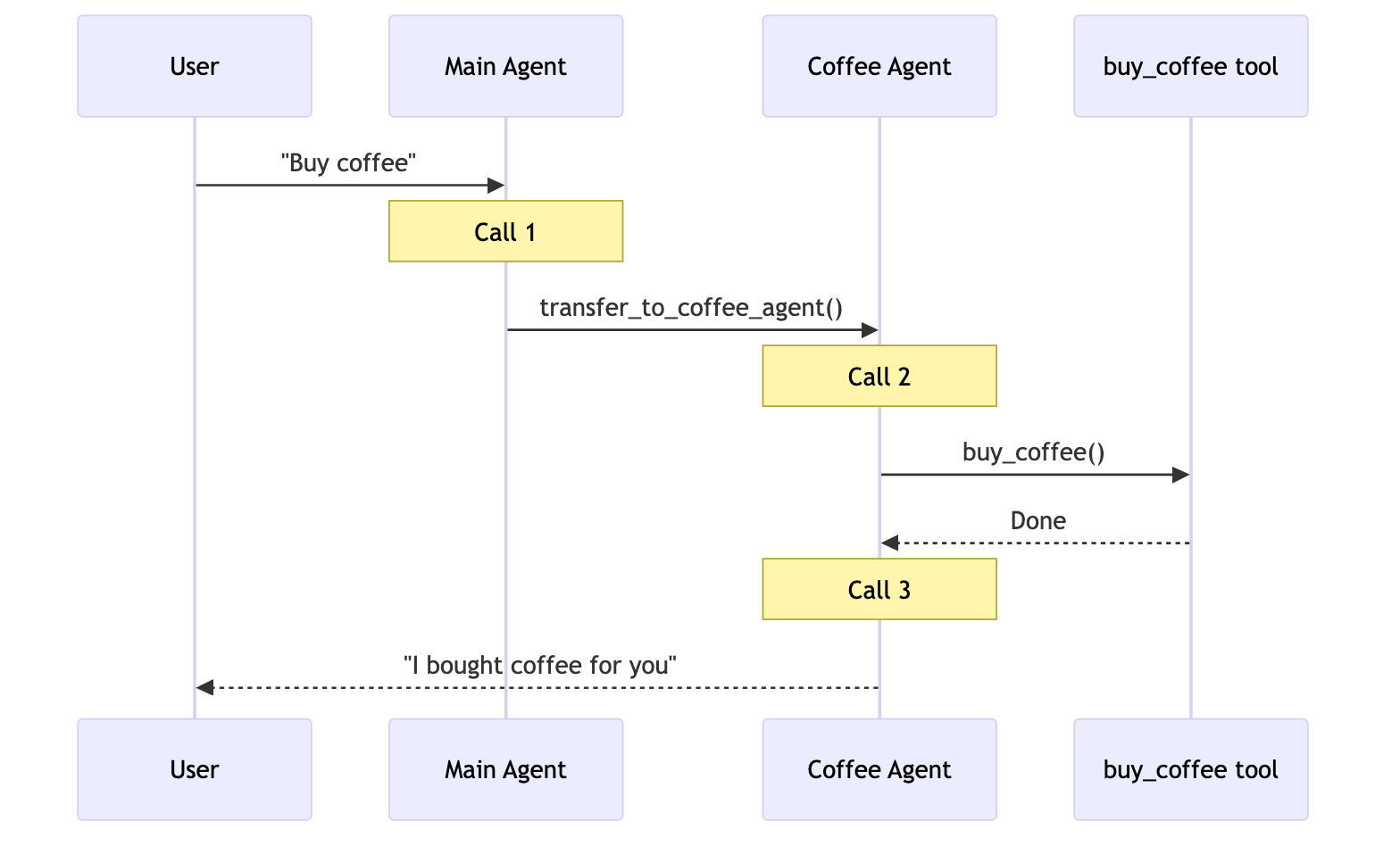
| 交接 | 行为根据状态动态变化。工具调用会更新状态变量,从而触发路由或配置更改,切换智能体或调整当前智能体的工具和提示。 |
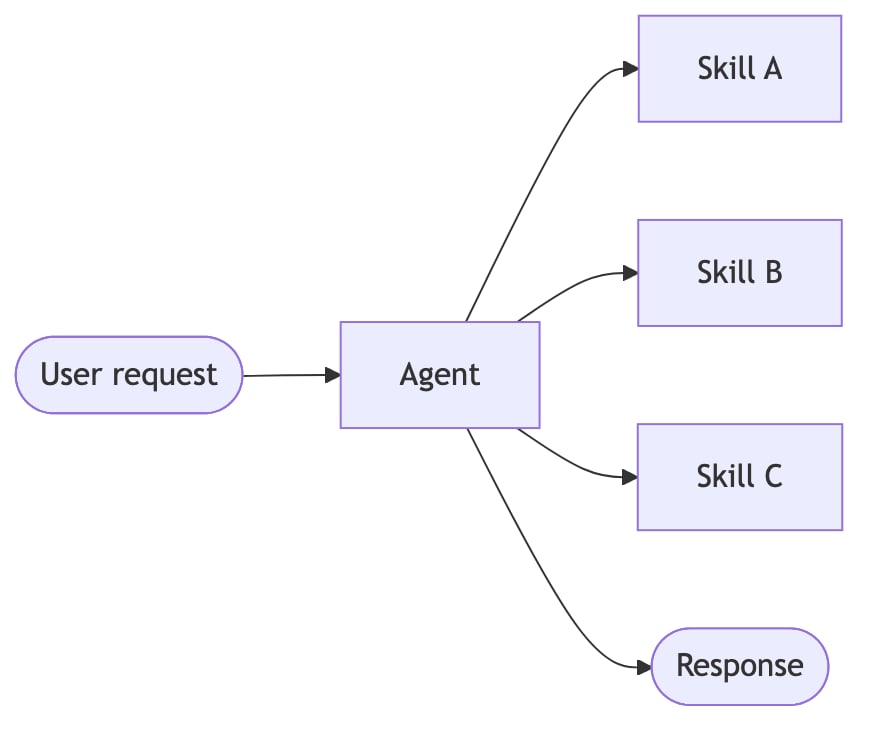
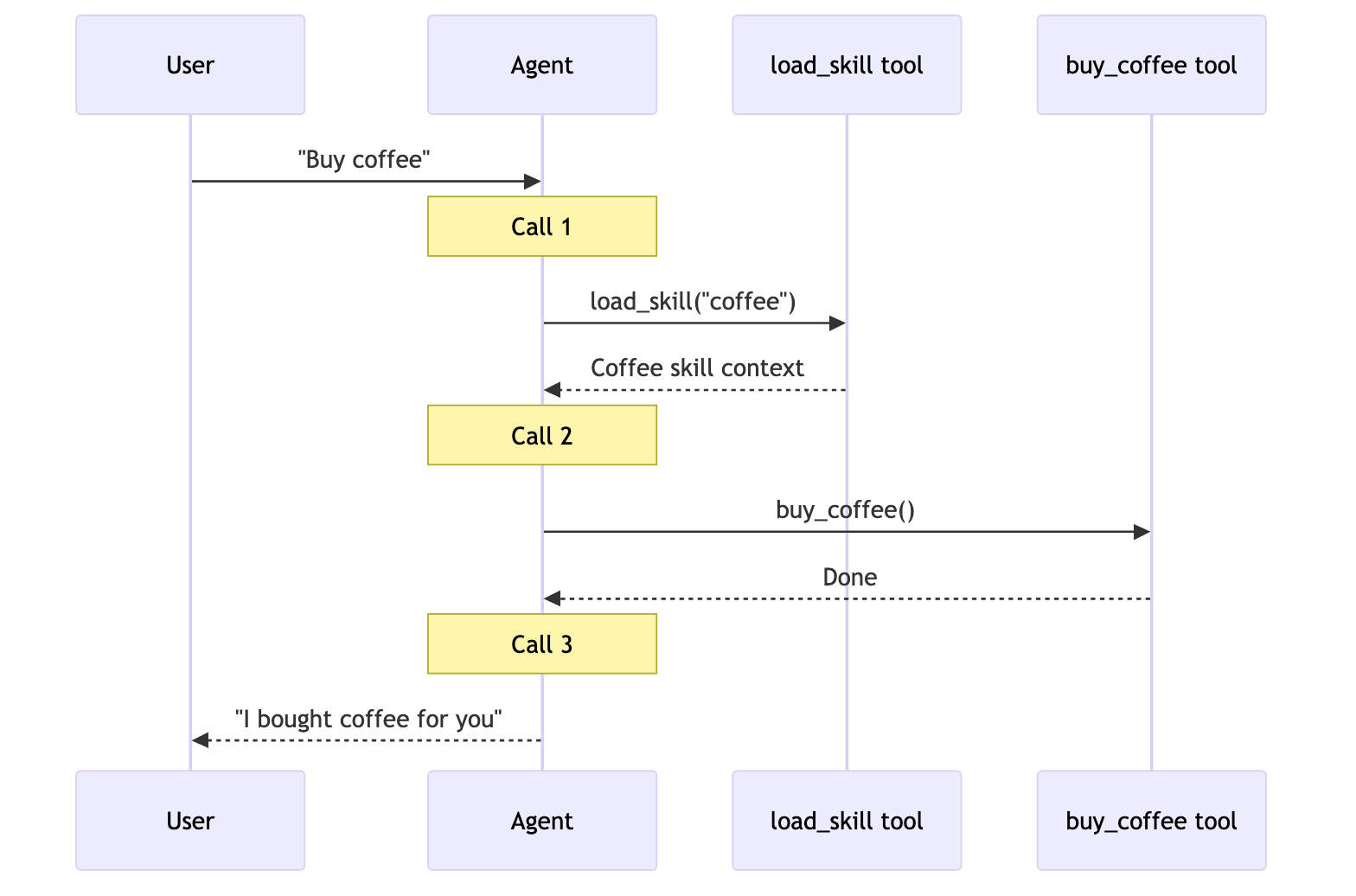
| 技能 | 按需加载的专用提示和知识。单个智能体保持控制,同时根据需要从技能加载上下文。 |
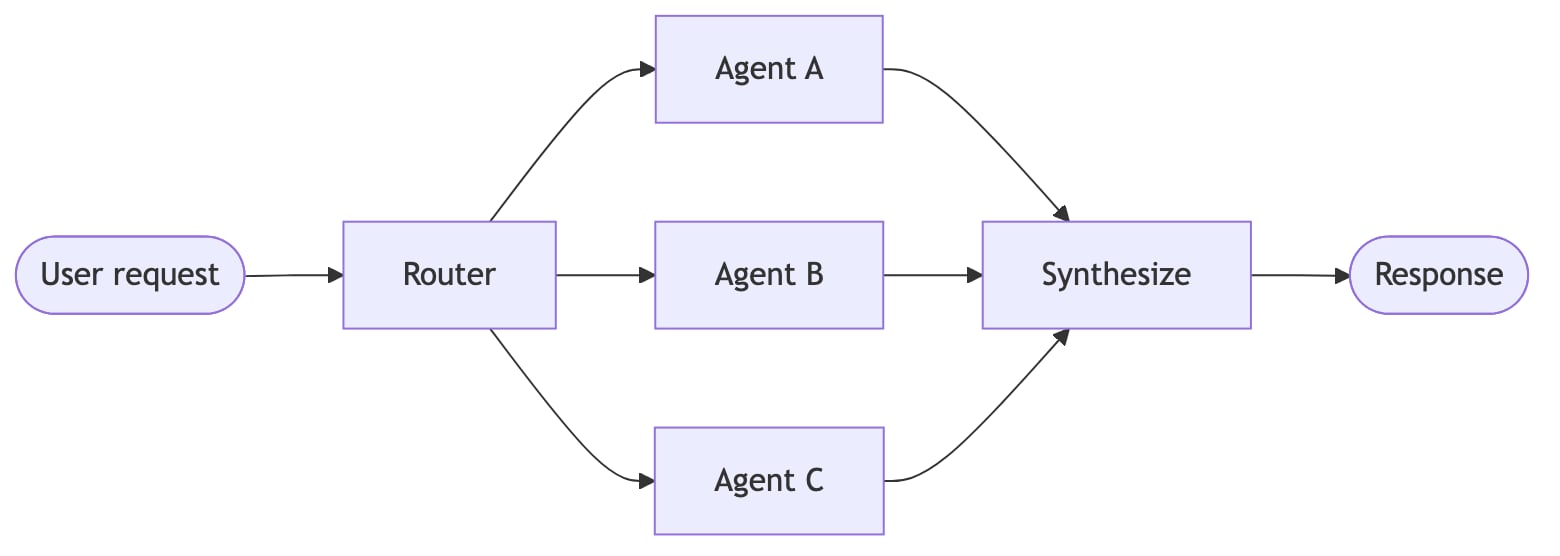
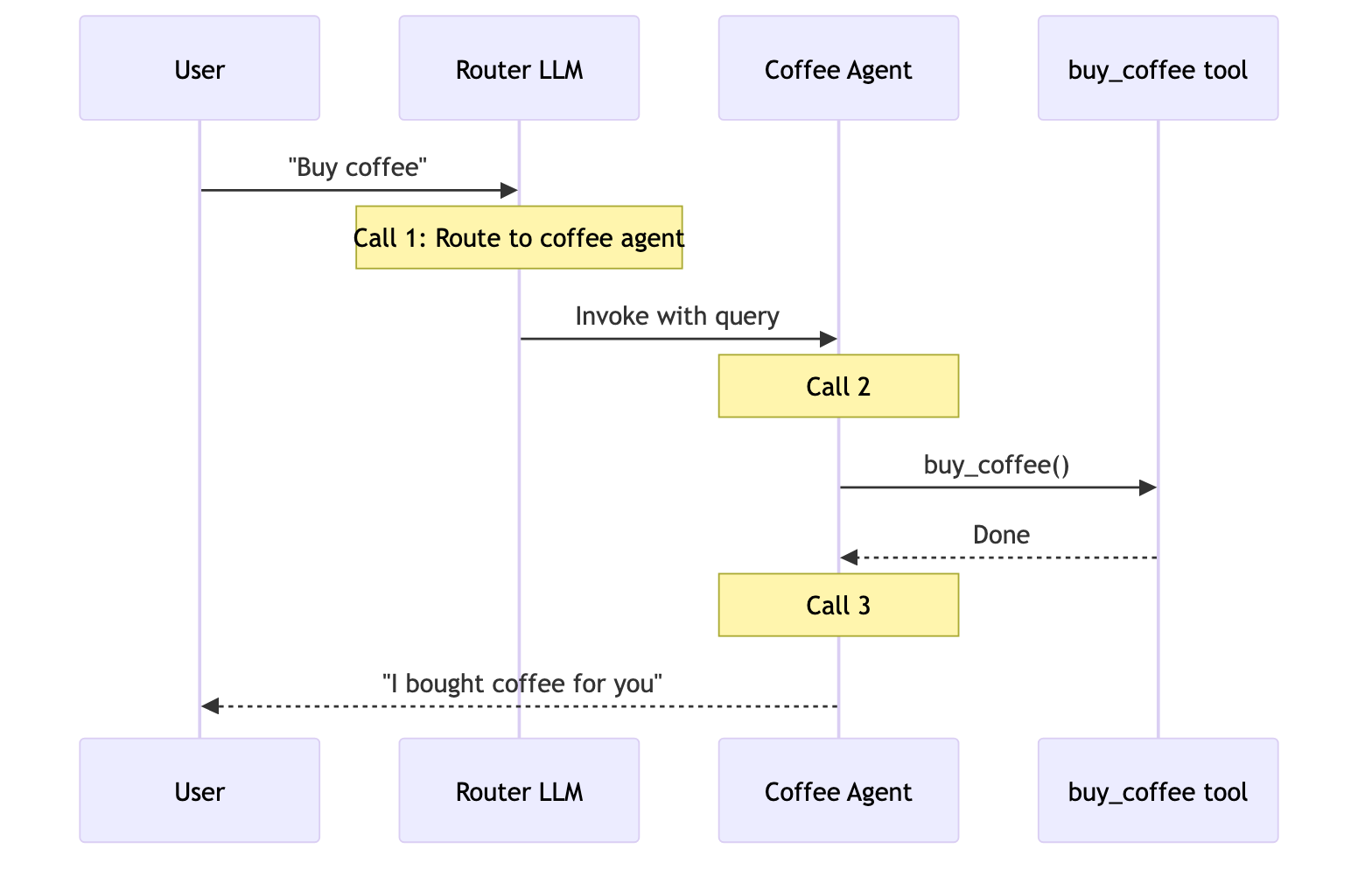
| 路由器 | 路由步骤对输入进行分类,并将其定向到一个或多个专用智能体。结果被合成为一个统一的响应。 |
| 自定义工作流 | 使用 LangGraph 构建定制的执行流程,混合确定性逻辑和智能体行为。将其他模式作为节点嵌入到你的工作流中。 |
选择模式
使用此表将你的需求与正确的模式匹配:
| 模式 | 分布式开发 | 并行化 | 多跳 | 直接用户交互 |
|---|
| 子智能体 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| 交接 | - | - | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 技能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 路由器 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | - | ⭐⭐⭐ |
- 分布式开发:不同团队能否独立维护组件?
- 并行化:多个智能体能否并发执行?
- 多跳:该模式是否支持连续调用多个子智能体?
- 直接用户交互:子智能体能否直接与用户对话?
你可以混合使用模式!例如,一个子智能体架构可以调用那些调用自定义工作流或路由器智能体的工具。子智能体甚至可以使用技能模式来按需加载上下文。可能性是无限的!
可视化概览
一个主智能体将子智能体作为工具进行协调。所有路由都通过主智能体。 智能体通过工具调用将控制权转移给彼此。每个智能体可以交接给其他智能体,也可以直接响应用户。 单个智能体在保持控制的同时,按需加载专用提示和知识。 路由步骤对输入进行分类,并将其定向到专用智能体。结果被合成。 性能比较
不同的模式具有不同的性能特征。了解这些权衡有助于你根据延迟和成本要求选择正确的模式。
关键指标:
- 模型调用次数:LLM 调用的次数。调用越多 = 延迟越高(尤其是顺序调用时)和每次请求的 API 成本越高。
- 处理的令牌数:所有调用中上下文窗口的总使用量。令牌越多 = 处理成本越高,并可能触及上下文限制。
单次请求
用户: “买咖啡”
一个专门的咖啡智能体/技能可以调用 buy_coffee 工具。
| 模式 | 模型调用次数 | 最佳适用场景 |
|---|
| 子智能体 | 4 | |
| 交接 | 3 | ✅ |
| 技能 | 3 | ✅ |
| 路由器 | 3 | ✅ |
重复请求
第 1 轮: “买咖啡”
第 2 轮: “再买一次咖啡”
用户在同一对话中重复相同的请求。
再次 4 次调用 → 总计 8 次
- 子智能体设计上是无状态的——每次调用都遵循相同的流程
- 主智能体维护对话上下文,但子智能体每次都是全新的
- 这提供了强大的上下文隔离,但重复了整个流程
2 次调用 → 总计 5 次
- 咖啡智能体在第 1 轮后仍然处于活动状态(状态持续)
- 无需交接——智能体直接调用
buy_coffee 工具(调用 1)
- 智能体响应用户(调用 2)
- 通过跳过交接节省了 1 次调用
2 次调用 → 总计 5 次
- 技能上下文已经加载在对话历史中
- 无需重新加载——智能体直接调用
buy_coffee 工具(调用 1)
- 智能体响应用户(调用 2)
- 通过重用已加载的技能节省了 1 次调用
再次 3 次调用 → 总计 6 次
- 路由器是无状态的——每个请求都需要一次 LLM 路由调用
- 第 2 轮:路由器 LLM 调用(1)→ 牛奶智能体调用 buy_coffee(2)→ 牛奶智能体响应(3)
- 可以通过将其包装为有状态智能体中的工具来优化
多领域
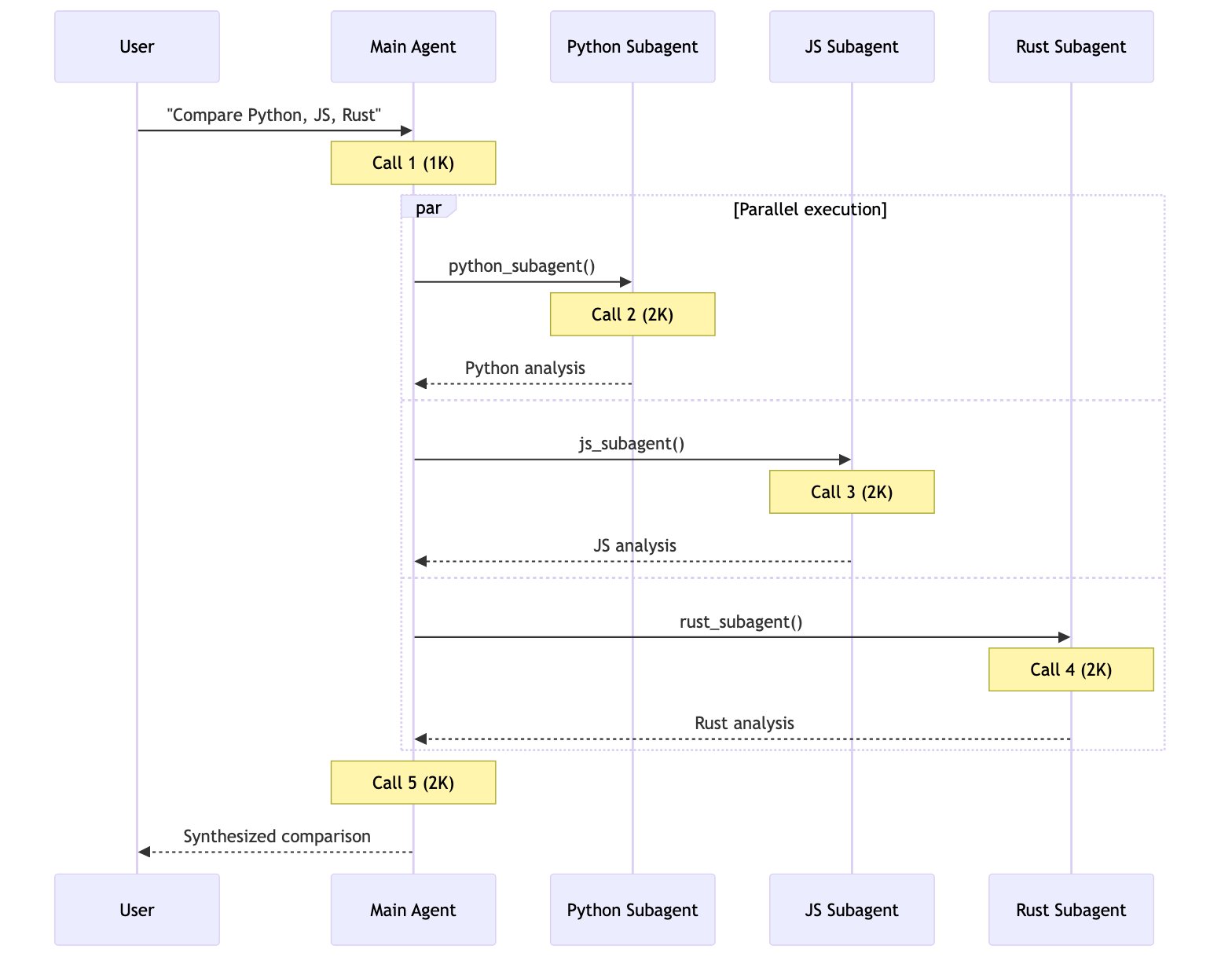
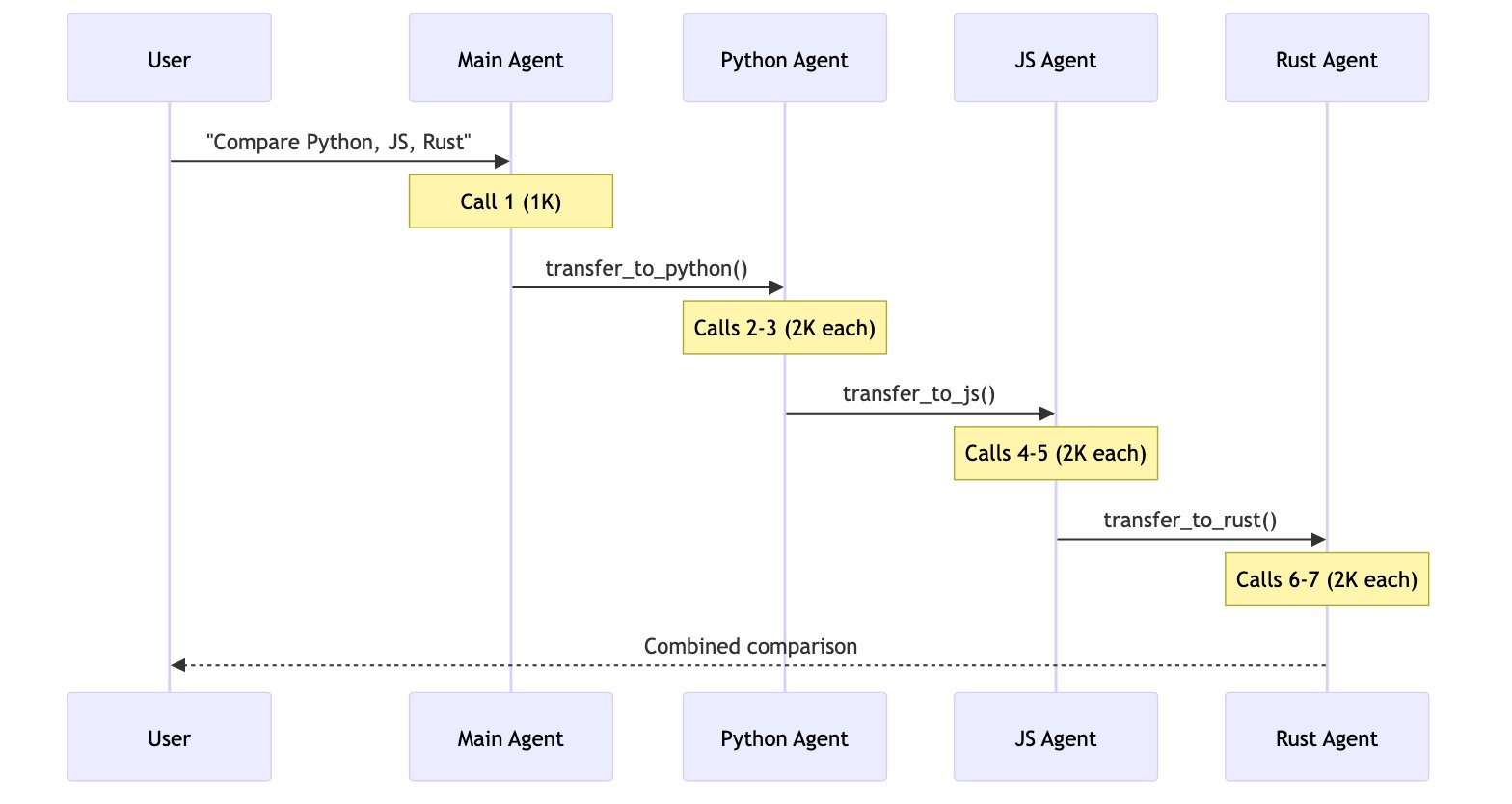
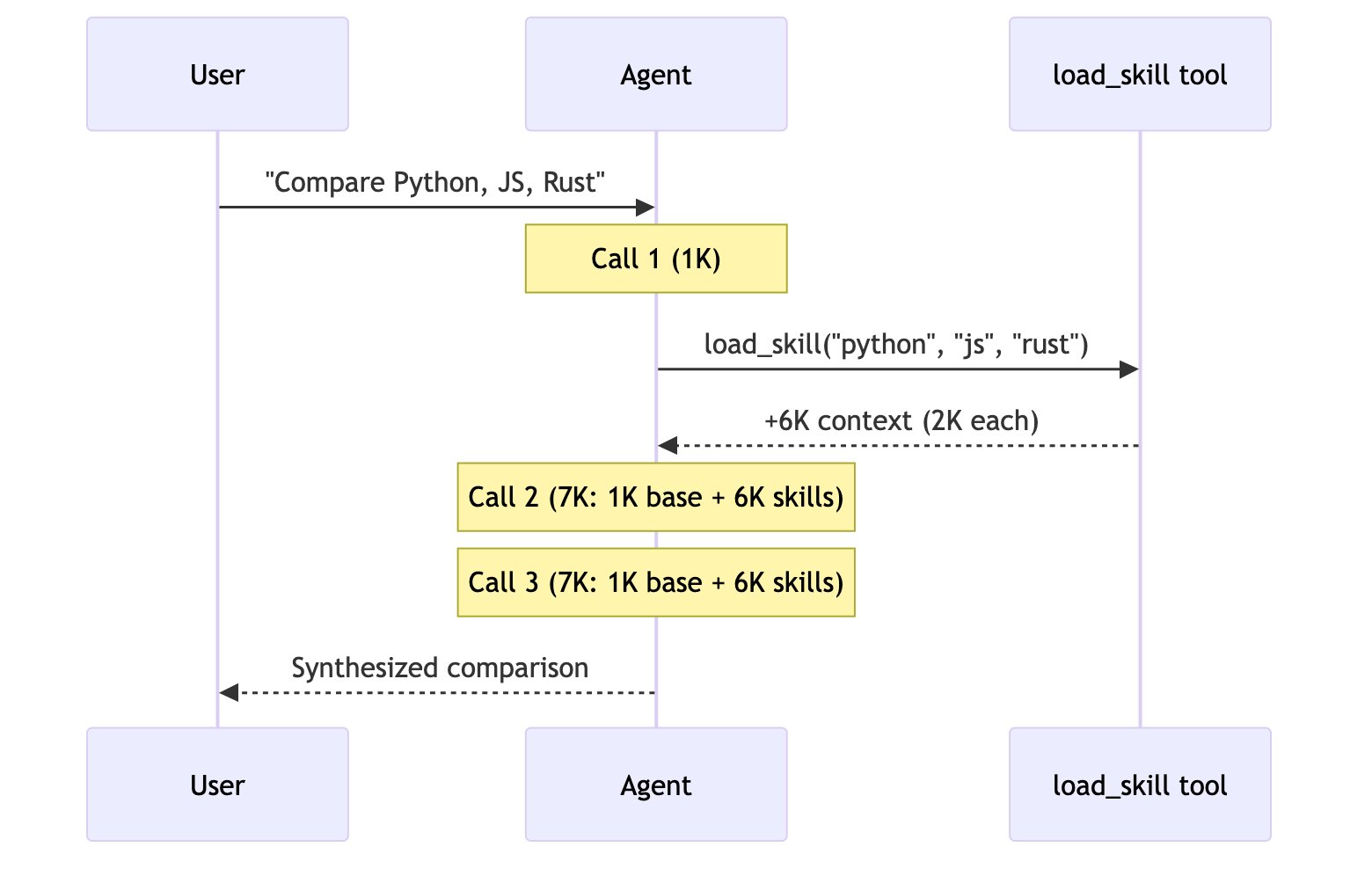
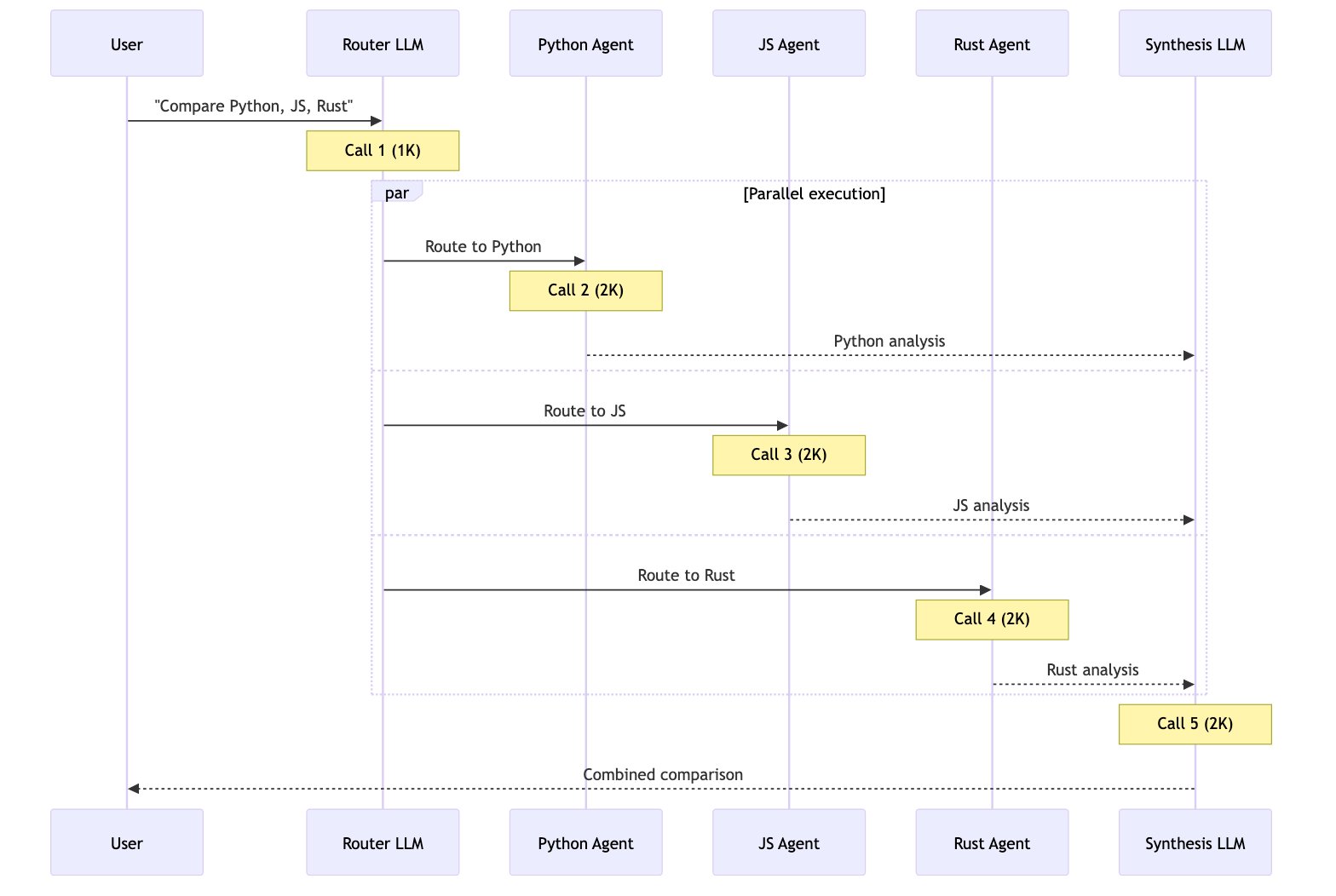
用户: “比较 Python、JavaScript 和 Rust 在 Web 开发方面的表现”
每个语言智能体/技能包含约 2000 个令牌的文档。所有模式都可以进行并行工具调用。
| 模式 | 模型调用次数 | 总令牌数 | 最佳适用场景 |
|---|
| 子智能体 | 5 | ~9K | ✅ |
| 交接 | 7+ | ~14K+ | |
| 技能 | 3 | ~15K | |
| 路由器 | 5 | ~9K | ✅ |
5 次调用,~9K 令牌每个子智能体在隔离状态下工作,只处理其相关上下文。总计:9K 令牌。 7+ 次调用,~14K+ 令牌交接模式顺序执行——无法并行研究所有三种语言。不断增长的对话历史增加了开销。总计:~14K+ 令牌。 3 次调用,~15K 令牌加载后,每次后续调用都需要处理所有 6K 令牌的技能文档。由于上下文隔离,子智能体模式总体上处理的令牌数减少了 67%。总计:15K 令牌。 5 次调用,~9K 令牌路由器使用 LLM 进行路由,然后并行调用智能体。与子智能体模式类似,但多了一个明确的路由步骤。总计:9K 令牌。 | 模式 | 单次请求 | 重复请求 | 多领域 |
|---|
| 子智能体 | 4 次调用 | 8 次调用 (4+4) | 5 次调用,9K 令牌 |
| 交接 | 3 次调用 | 5 次调用 (3+2) | 7+ 次调用,14K+ 令牌 |
| 技能 | 3 次调用 | 5 次调用 (3+2) | 3 次调用,15K 令牌 |
| 路由器 | 3 次调用 | 6 次调用 (3+3) | 5 次调用,9K 令牌 |