

概述
由大语言模型(LLM)支持的最强大的应用之一是复杂的问答(Q&A)聊天机器人。这些应用程序可以回答关于特定源信息的问题。这些应用程序使用一种称为检索增强生成(Retrieval Augmented Generation,或 RAG)的技术。 本教程将展示如何针对非结构化文本数据源构建一个简单的问答应用程序。我们将演示:概念
我们将涵盖以下概念:- 索引:从源摄取数据并对其进行索引的管道。这通常发生在单独的过程中。
- 检索和生成:实际的 RAG 过程,它在运行时获取用户查询并从索引中检索相关数据,然后将其传递给模型。
预览
在本指南中,我们将构建一个回答网站内容问题的应用程序。我们将使用的特定网站是 Lilian Weng 的 LLM Powered Autonomous Agents 博客文章,它允许我们询问有关帖子内容的各种问题。 我们可以创建一个简单的索引管道和 RAG 链来在 ~40 行代码内完成此操作。完整代码片段如下所示:设置
安装
本教程需要以下 langchain 依赖项:LangSmith
使用 LangChain 构建的许多应用程序都将包含多个步骤和多次 LLM 调用。随着这些应用程序变得越来越复杂,能够检查您的链或代理内部究竟发生了什么变得至关重要。最好的方法是使用 LangSmith。 在上述链接注册后,请确保设置环境变量以开始记录跟踪:组件
我们需要从 LangChain 的集成套件中选择三个组件。 选择聊天模型:- OpenAI
- Anthropic
- Azure
- Google Gemini
- Bedrock Converse
- OpenAI
- Azure
- AWS
- VertexAI
- MistralAI
- Cohere
- 内存
- Chroma
- FAISS
- MongoDB
- PGVector
- Pinecone
- Qdrant
- Redis
1. 索引
索引通常按以下方式工作:- 加载:首先我们需要加载数据。这是通过 文档加载器 完成的。
- 拆分:文本拆分器 将大型
Documents拆分为较小的块。这对于索引数据和将其传递给模型都有用,因为大块更难搜索且无法适应模型的有限上下文窗口。 - 存储:我们需要一个地方来存储和索引我们的拆分,以便以后可以搜索它们。这通常使用 向量存储 和 嵌入 模型来完成。
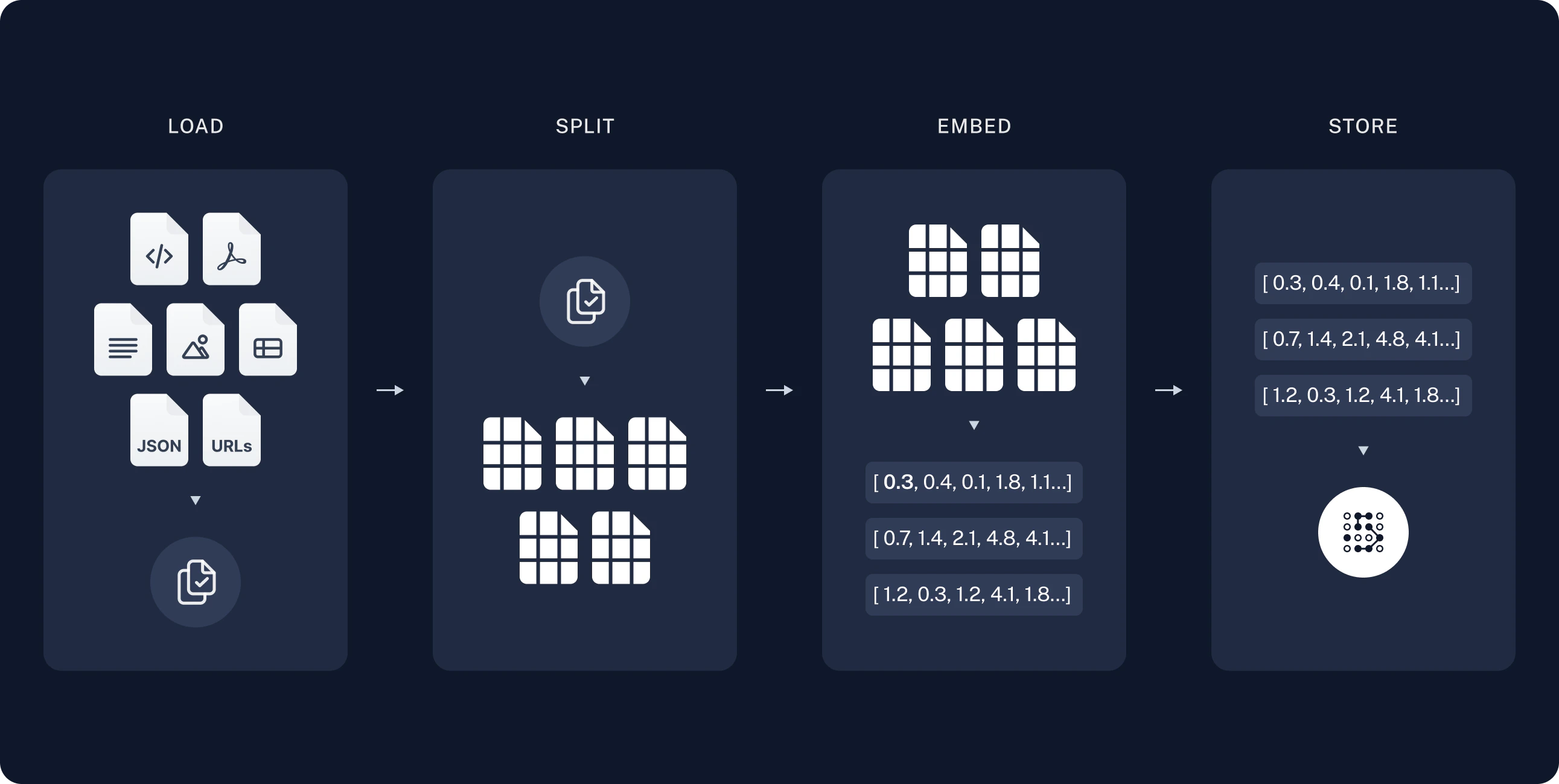
加载文档
我们首先需要加载博客文章内容。我们可以为此使用 DocumentLoaders,它们是加载源数据并返回 Document 对象列表的对象。DocumentLoader:从源加载数据作为 Documents 列表的对象。
- 集成:160+ 种集成可供选择。
BaseLoader:基础接口的 API 参考。
拆分文档
我们加载的文档超过 42k 个字符,这对于许多模型的上下文窗口来说太长了。即使对于那些可以将整篇文章放入其上下文窗口的模型,模型也可能难以在非常长的输入中找到信息。 为了处理这个问题,我们将把Document 拆分为用于嵌入和向量存储的块。这将有助于我们在运行时仅检索博客文章中最相关的部分。
与 语义搜索教程 一样,我们使用 RecursiveCharacterTextSplitter,它将使用常见的分隔符(如新行)递归地拆分文档,直到每个块大小合适。这是用于通用文本用例的推荐文本拆分器。
存储文档
现在我们需要索引我们的 66 个文本块,以便在运行时搜索它们。遵循 语义搜索教程,我们的方法是将每个文档拆分的内容 嵌入 并将这些嵌入插入到 向量存储 中。给定输入查询,我们可以随后使用向量搜索检索相关文档。 我们可以使用在 教程开始时 选择的向量存储和嵌入模型,在一个命令中嵌入并存储所有文档拆分。Embeddings:围绕文本嵌入模型的包装器,用于将文本转换为嵌入。
VectorStore:围绕向量数据库的包装器,用于存储和查询嵌入。
至此完成了管道的 索引 部分。此时,我们拥有一个可查询的向量存储,其中包含我们博客文章的分块内容。给定用户问题,我们应该能够返回回答该问题的博客文章片段。
2. 检索和生成
RAG 应用程序通常按以下方式工作: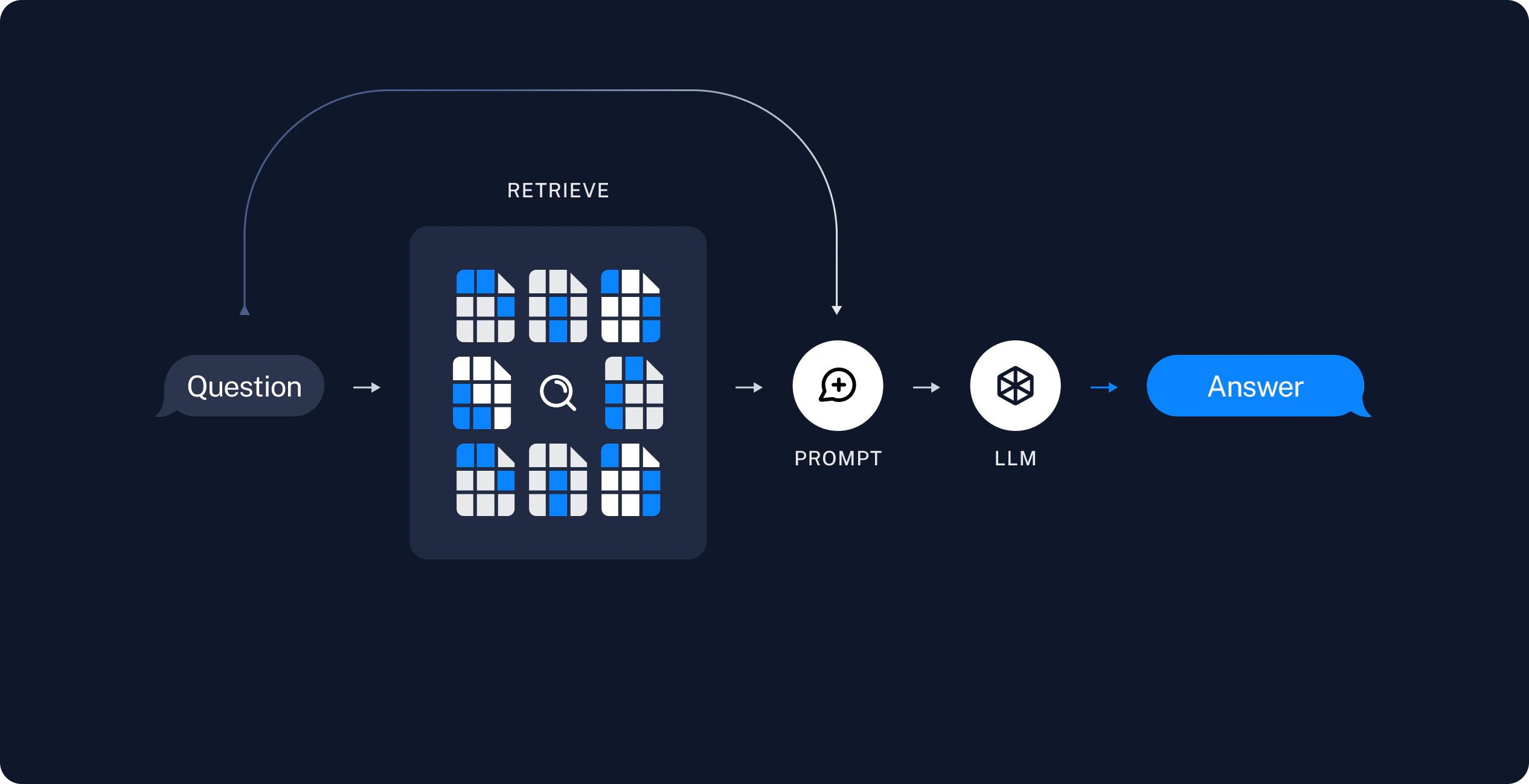
RAG 代理
RAG 应用程序的一种形式是一个带有检索信息工具的简单 代理。我们可以通过实现一个包装我们的向量存储的 工具 来组装一个最小的 RAG 代理:- 生成查询以搜索任务分解的标准方法;
- 收到答案后,生成第二个查询以搜索其常见扩展;
- 收到所有必要上下文后,回答问题。
RAG 链
在上述 代理式 RAG 公式中,我们允许 LLM 自行决定生成 工具调用 以帮助回答用户查询。这是一个良好的通用解决方案,但也带来了一些权衡:| ✅ 优势 | ⚠️ 缺点 |
|---|---|
| 仅在需要时搜索——LLM 可以处理问候语、后续问题和简单查询,而无需触发不必要的搜索。 | 两次推理调用——执行搜索时,需要一次调用来生成查询,另一次调用来生成最终响应。 |
上下文搜索查询——通过将搜索视为具有 query 输入的工具,LLM 会创建自己的查询,其中包含对话上下文。 | 控制减少——LLM 可能会跳过实际上需要的搜索,或者在不必要时发出额外搜索。 |
| 允许多次搜索——LLM 可以执行多次搜索以支持单个用户查询。 |
返回源文档
返回源文档
安全性:间接提示注入
为了缓解这种情况:- 使用防御性提示:明确指示模型将检索到的上下文仅视为数据,并忽略其中的任何指令。本教程中的提示包括此类指令。
- 用定界符包装上下文:使用清晰的结构标记(例如,XML 标签
<context>...</context>)将检索到的数据与指令分开,使模型更容易区分它们。 - 验证响应:检查模型的输出是否符合预期格式(例如,纯文本),并以优雅的方式处理意外格式。
下一步
既然我们已经通过createAgent 实现了简单的 RAG 应用程序,我们可以轻松添加新功能并深入探索:
- 流式传输 token 和其他信息以实现响应的用户体验
- 添加 对话记忆 以支持多轮交互
- 添加 长期记忆 以支持跨对话线程的记忆
- 添加 结构化响应
- 使用 LangSmith Deployment 部署您的应用程序
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.