

在 LangSmith UI 中查看成本
在 LangSmith UI 中,您可以通过三种主要方式探索使用量和支出:首先了解令牌和成本是如何分解的,然后在单个追踪记录中查看这些详细信息,最后在项目统计和仪表板中检查聚合指标。令牌和成本分解
令牌使用量和成本被分解为三个类别:- 输入:发送给模型的提示中的令牌。子类型包括:缓存读取、文本令牌、图像令牌等。
- 输出:模型响应中生成的令牌。子类型包括:推理令牌、文本令牌、图像令牌等。
- 其他:来自工具调用、检索步骤或任何自定义运行的成本。
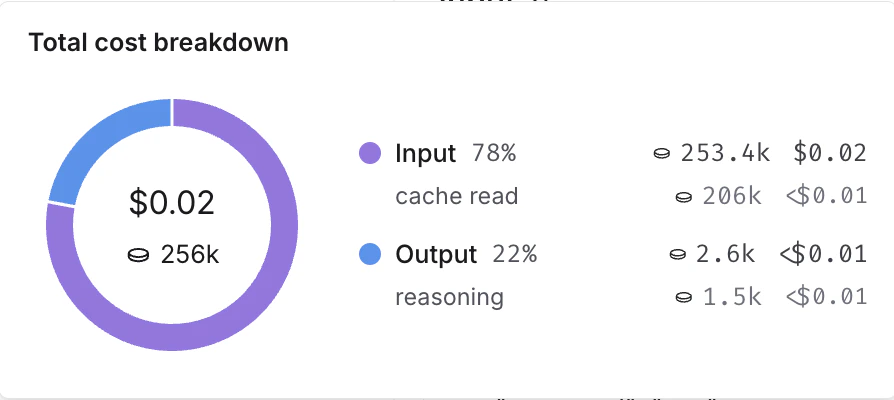
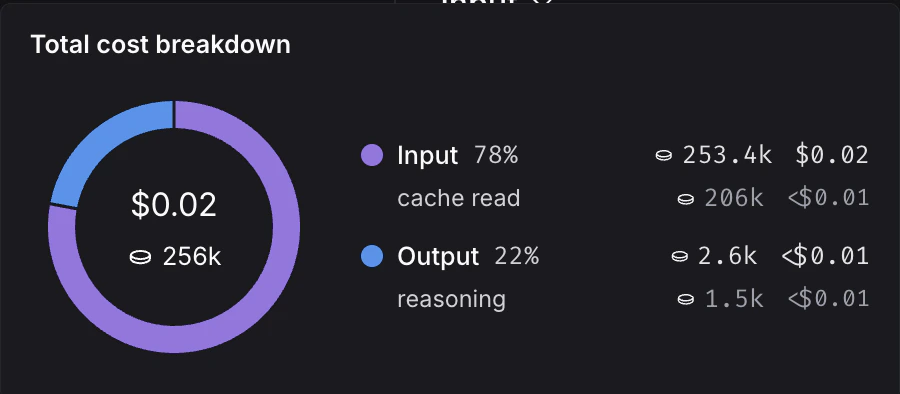
查看令牌和成本分解的位置
在追踪树中
在追踪树中
追踪树显示了令牌使用量和成本的最详细视图(针对单个追踪)。它显示整个追踪的总使用量、每个父级运行的聚合值以及每个子级运行的令牌和成本分解。打开追踪项目中的任何运行以查看其追踪树。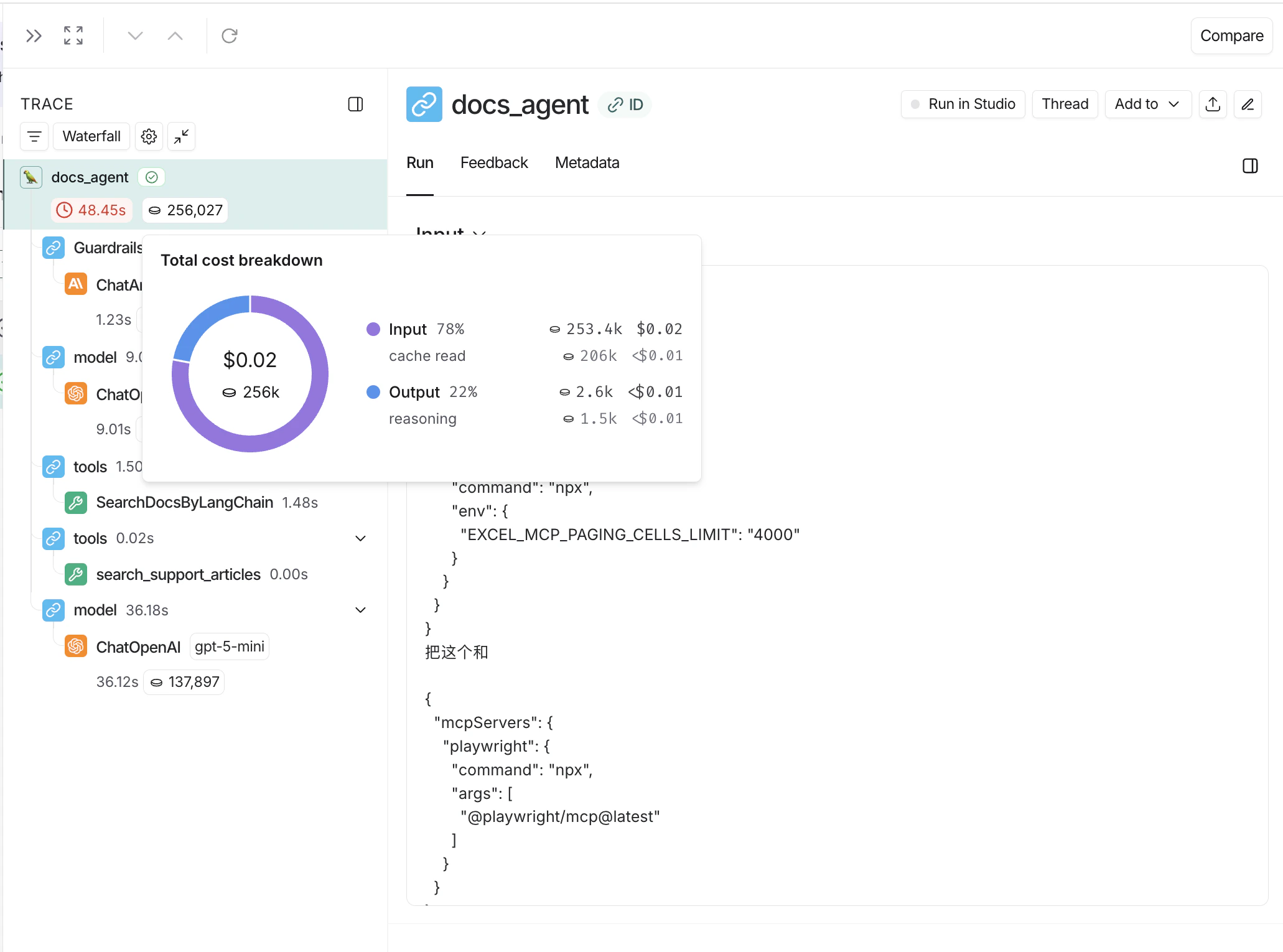
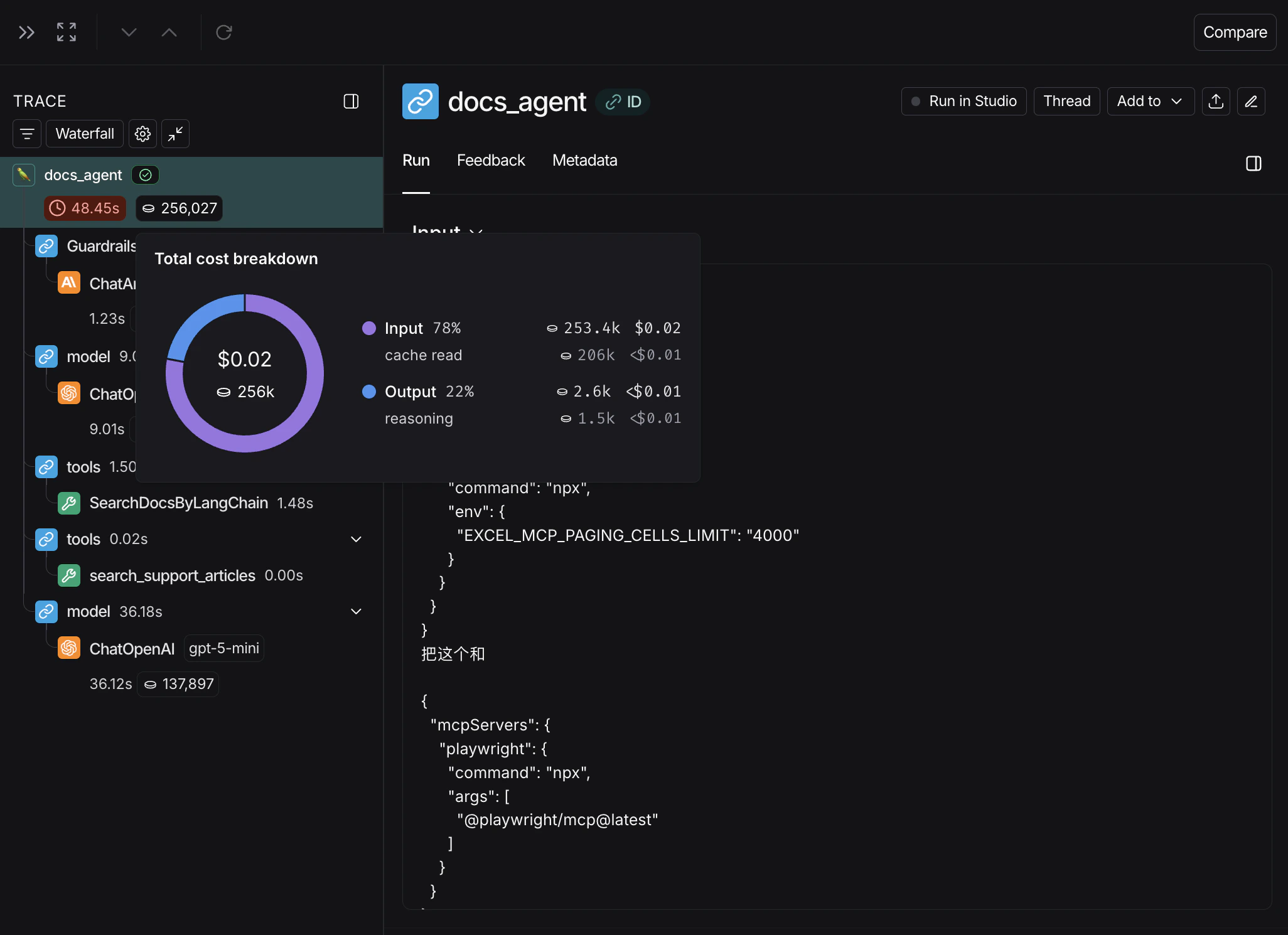
在跨线程追踪成本时,请确保所有子级运行都包含线程元数据(
session_id、thread_id 或 conversation_id)。如果子级运行没有线程元数据,这些运行的令牌计数和成本将不会包含在线程级别的聚合中。有关设置线程元数据的详细信息,请参阅配置线程。在项目统计中
在项目统计中
项目统计面板显示项目中所有追踪的总令牌使用量和成本。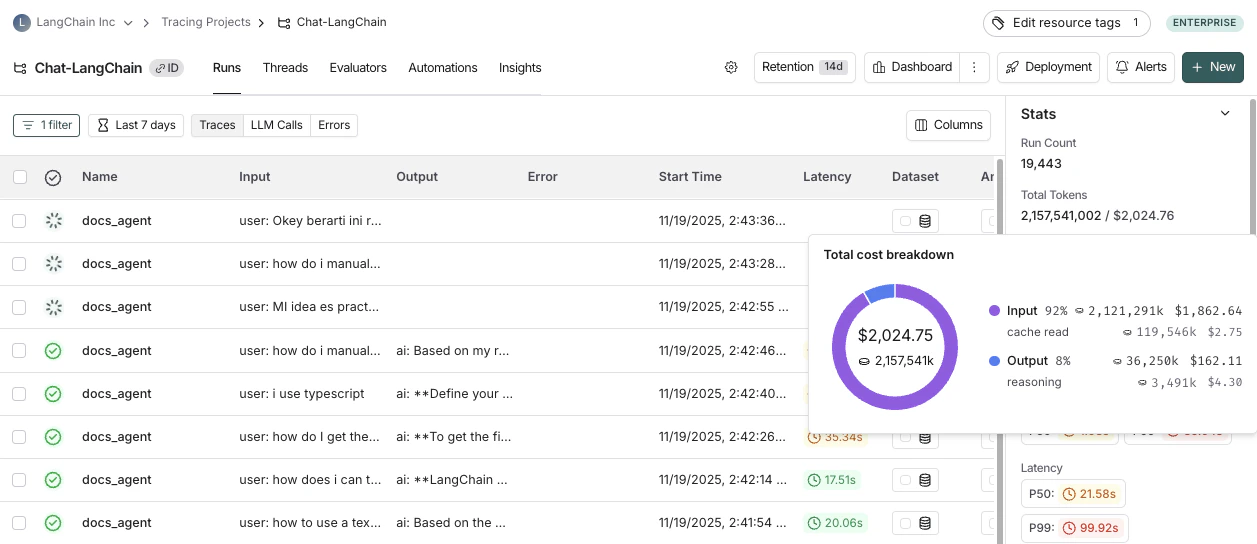
成本追踪
您可以通过两种方式追踪成本:- LLM 调用的成本可以根据令牌计数和模型价格自动推导
- LLM 调用或任何其他运行类型的成本可以作为运行数据的一部分手动指定
LLM 调用:基于令牌计数自动追踪成本
要根据令牌使用量自动计算成本,您需要提供令牌计数、模型和提供商以及模型价格。
1. 发送令牌计数
许多模型在响应中包含令牌计数。您必须提取此信息并使用以下方法之一将其包含在您的运行中:
A. 在运行的元数据上设置 `usage_metadata` 字段
A. 在运行的元数据上设置 `usage_metadata` 字段
在运行的元数据上设置
usage_metadata 字段。这种方法的优点是您不需要更改被追踪函数的运行时输出。B. 在您的追踪函数输出中返回 `usage_metadata` 字段。
B. 在您的追踪函数输出中返回 `usage_metadata` 字段。
在您的追踪函数返回的对象中直接包含
usage_metadata 键。LangSmith 将从输出中提取它。使用量元数据模式和成本计算
使用量元数据模式和成本计算
LangSmith 识别 成本计算运行的成本是从最具体到最不具体的令牌类型贪婪计算的。假设您设置了每 100 万输入令牌 2 美元的价格,其中 那么,令牌成本将按如下方式计算:
usage_metadata 字典中的以下字段。您可以直接查看完整的 Python 类型 或 TypeScript 接口。模型中使用的输入令牌数。所有输入令牌类型的总和。
模型响应中使用的输出令牌数。所有输出令牌类型的总和。
输入和输出中使用的令牌总数。可选,可以推断。input_tokens + output_tokens 的总和。
输入令牌类型的细分。键是令牌类型字符串,值是计数。示例
{"cache_read": 5}。已知字段包括:audio、text、image、cache_read、cache_creation。根据模型或提供商的不同,可能存在其他字段。输出令牌类型的细分。键是令牌类型字符串,值是计数。示例
{"reasoning": 5}。已知字段包括:audio、text、image、reasoning。根据模型或提供商的不同,可能存在其他字段。输入令牌的成本。
输出令牌的成本。
令牌的总成本。可选,可以推断。input_cost + output_cost 的总和。
输入成本的详细信息。键是令牌类型字符串,值是成本金额。
输出成本的详细信息。键是令牌类型字符串,值是成本金额。
cache_read 输入令牌的详细价格为每 100 万 1 美元,输出令牌为每 100 万 3 美元。如果您上传了以下使用量元数据:ls_provider:模型的提供商,例如 “openai”、“anthropic”ls_model_name:模型的名称,例如 “gpt-4.1-mini”、“claude-3-opus-20240229”
该表包含大多数 OpenAI、Anthropic 和 Gemini 模型的价格信息。如果您有自定义定价,可以创建新的模型价格条目或覆盖默认模型的价格。
... 上,可以显示按令牌类型细分的价格。
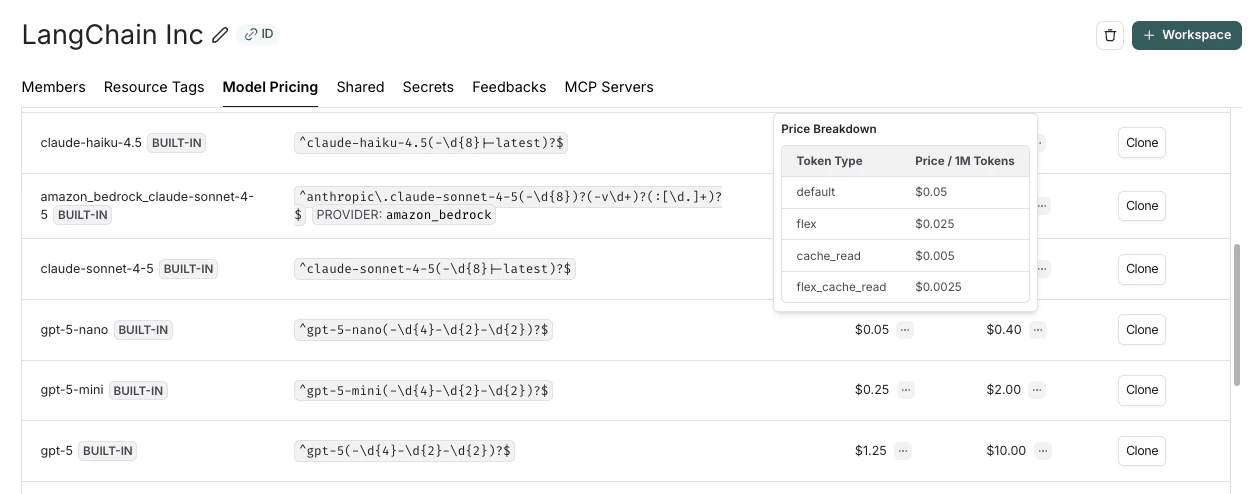
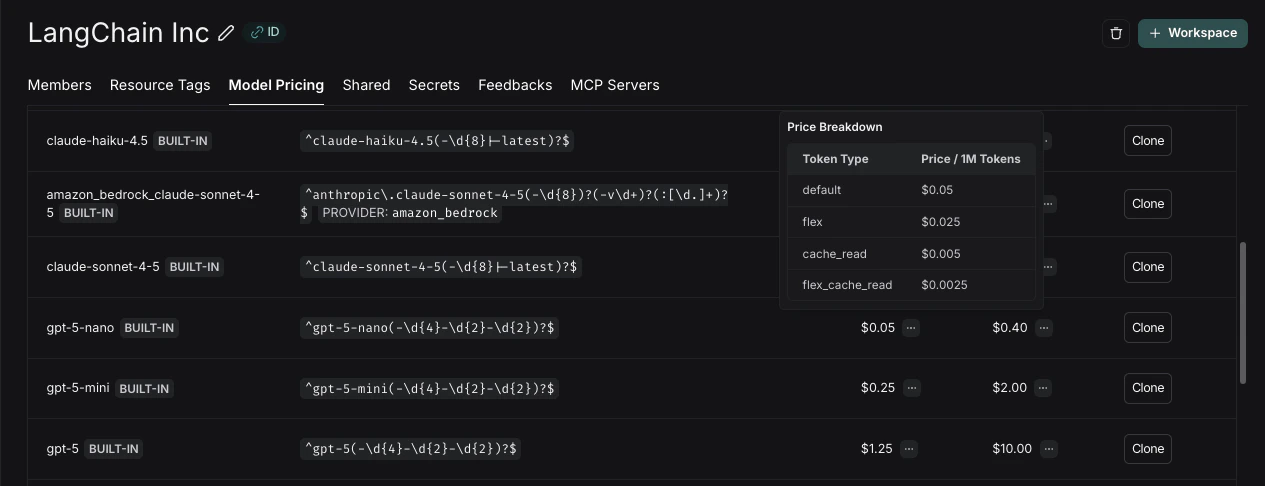
对模型价格映射的更新不会反映在已记录的追踪成本中。我们目前不支持回填模型价格更改。
创建新的或修改现有的模型价格条目
创建新的或修改现有的模型价格条目
要修改默认模型价格,请创建一个与默认条目具有相同模型、提供商和匹配模式的新条目。要在模型价格映射中创建新条目,请点击右上角的 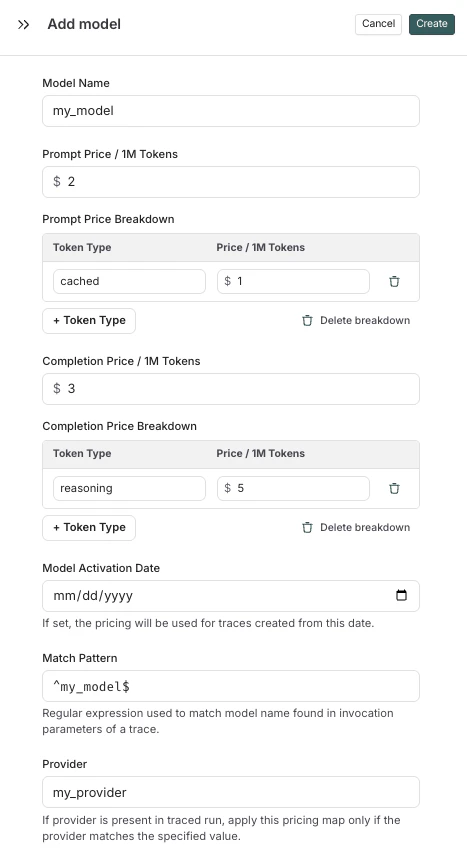
+ Model 按钮。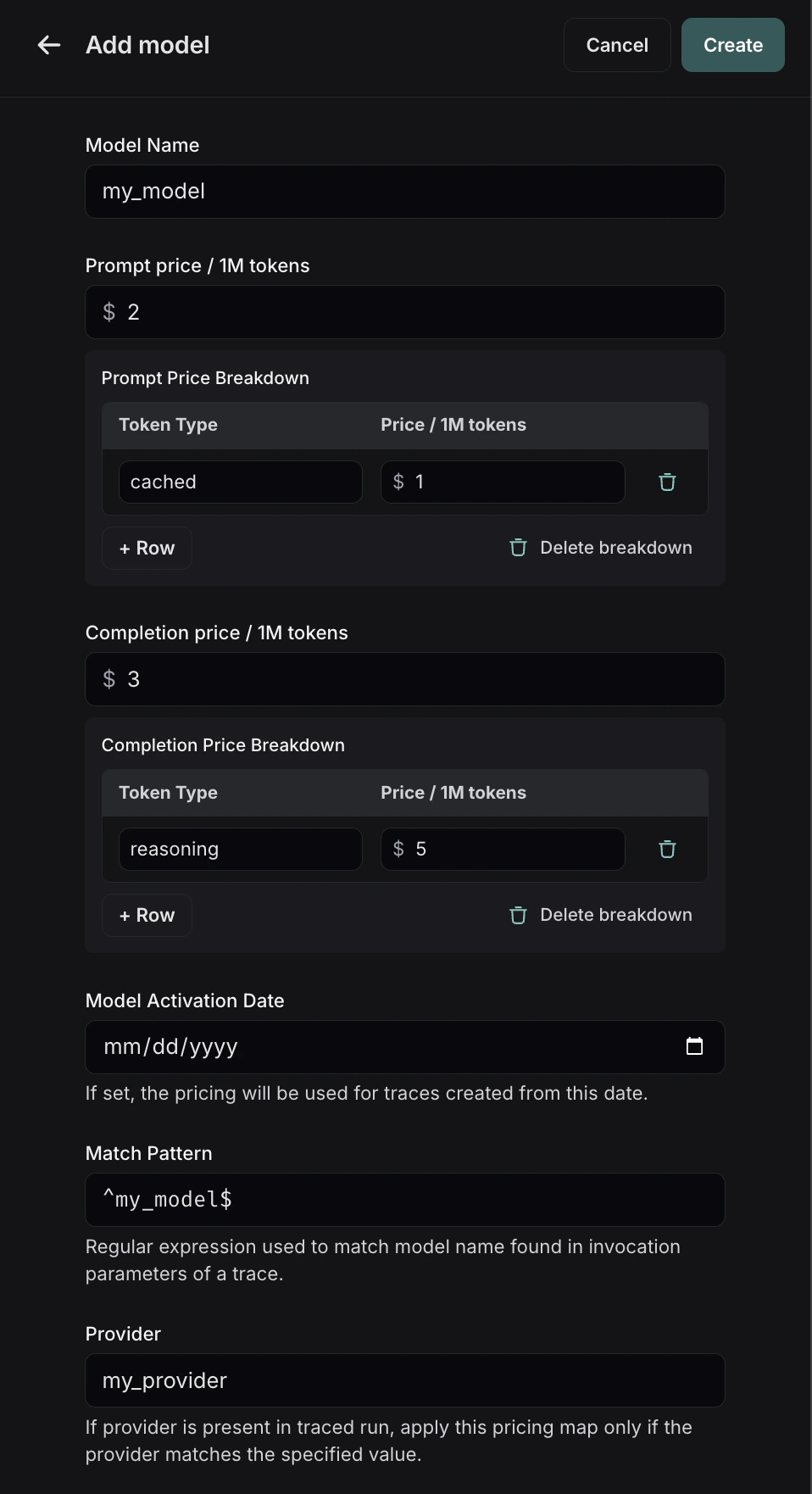
- 模型名称:模型的人类可读名称。
- 输入价格:模型每 100 万输入令牌的成本。此数字乘以提示中的令牌数以计算提示成本。
- 输入价格细分(可选):每种不同类型输入令牌的价格细分,例如
cache_read、video、audio - 输出价格:模型每 100 万输出令牌的成本。此数字乘以完成中的令牌数以计算完成成本。
- 输出价格细分(可选):每种不同类型输出令牌的价格细分,例如
reasoning、image等。 - 模型激活日期(可选):价格适用的起始日期。只有在此日期之后的运行才会应用此模型价格。
- 匹配模式:用于匹配模型名称的正则表达式模式。这用于匹配运行元数据中
ls_model_name的值。 - 提供商(可选):模型的提供商。如果指定,将与运行元数据中的
ls_provider进行匹配。
LLM 调用:直接发送成本
如果您的模型遵循非线性定价方案,我们建议在客户端计算成本,并将其作为usage_metadata 发送给 LangSmith。
Gemini 3.1 Pro Preview 和 Gemini 2.5 Pro 遵循具有阶梯成本函数的定价方案。我们默认支持 Gemini 的这种定价方案。对于任何其他具有非线性定价的模型,您需要遵循这些说明来计算成本。
其他运行:发送成本
您还可以为任何非 LLM 运行(例如工具调用)发送成本信息。成本必须在运行的usage_metadata 下的 total_cost 字段中指定。
A. 在运行的 usage_metadata 上设置 `total_cost` 字段
A. 在运行的 usage_metadata 上设置 `total_cost` 字段
在运行的
usage_metadata 上设置 total_cost 字段。这种方法的优点是您不需要更改被追踪函数的运行时输出。B. 在您的追踪函数输出中返回 `total_cost` 字段。
B. 在您的追踪函数输出中返回 `total_cost` 字段。
在您的追踪函数返回的对象中直接包含
usage_metadata 键。LangSmith 将从输出中提取它。Connect these docs to Claude, VSCode, and more via MCP for real-time answers.