

Insights 功能适用于 LangSmith Plus 和企业版套餐。
前提条件
- 在您的工作空间中为 Insights 设置好模型配置。
- 在 LangSmith 中创建规则的权限(生成新的 Insights 报告所需)。
- 在 LangSmith 中查看追踪项目的权限(查看现有 Insights 报告所需)。
生成您的第一份 Insights 报告
- 用户界面
- SDK
- 在左侧菜单中导航至 追踪项目,并选择一个追踪项目。
- 点击右上角的 +新建,然后选择 新建 Insights 报告,以基于该项目生成新的洞察。
- 为您的任务输入一个名称。
- 如果尚未配置,请在您的工作空间设置中为 Insights 配置一个模型。
- 回答引导性问题,将您的 Insights 报告聚焦于您想了解的代理相关信息,然后点击 运行任务。
使用 OpenAI 模型分析 1,000 条对话线程通常花费 $1.00-$2.00,使用当前的 Anthropic 模型通常花费 $3.00-$4.00。成本随采样的线程数量和每个线程的大小而增加。
理解结果
任务完成后,您可以导航到 Insights 选项卡,在那里您将看到一个 Insights 报告表格。每个报告都包含基于追踪项目中特定样本追踪数据生成的洞察。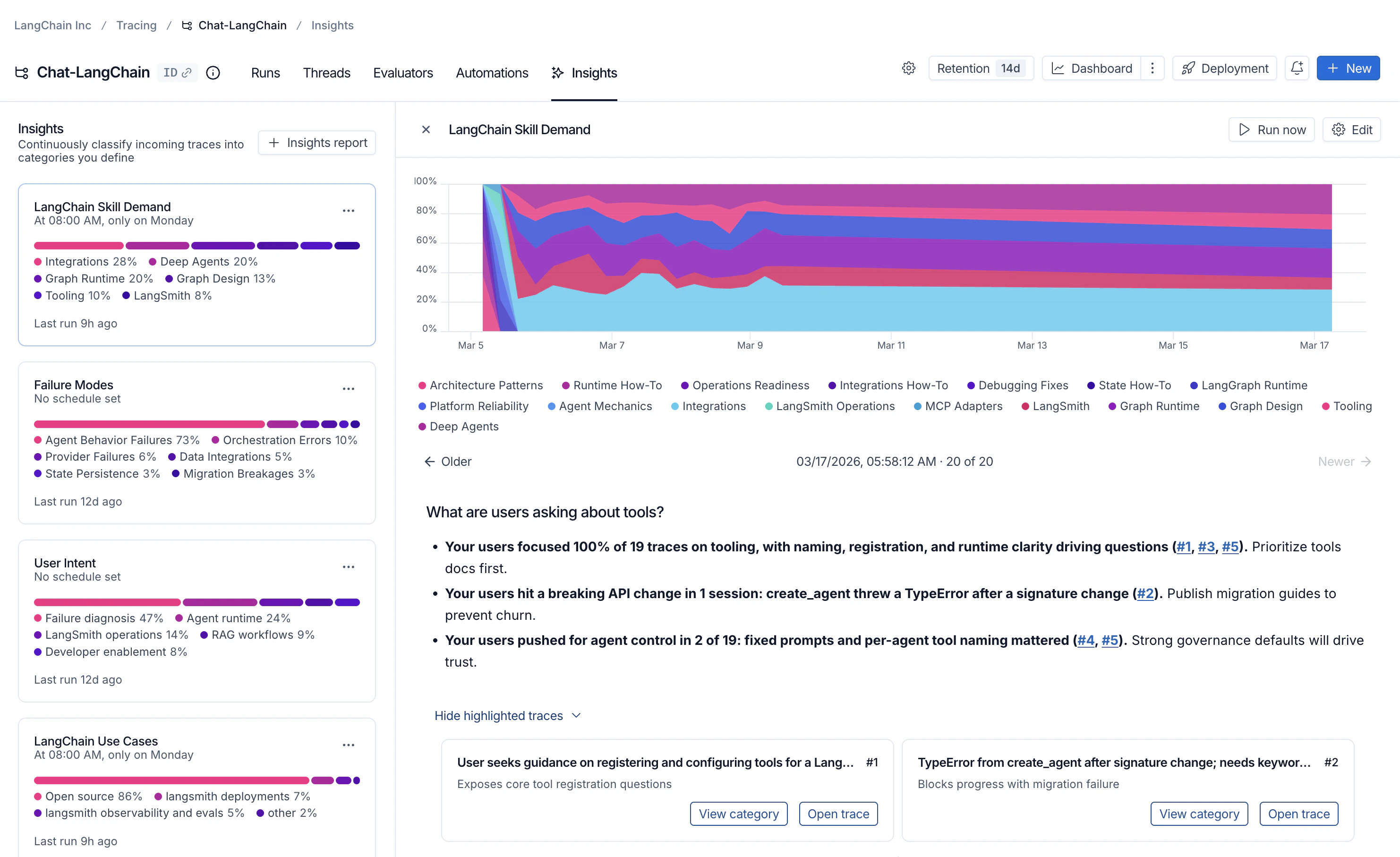
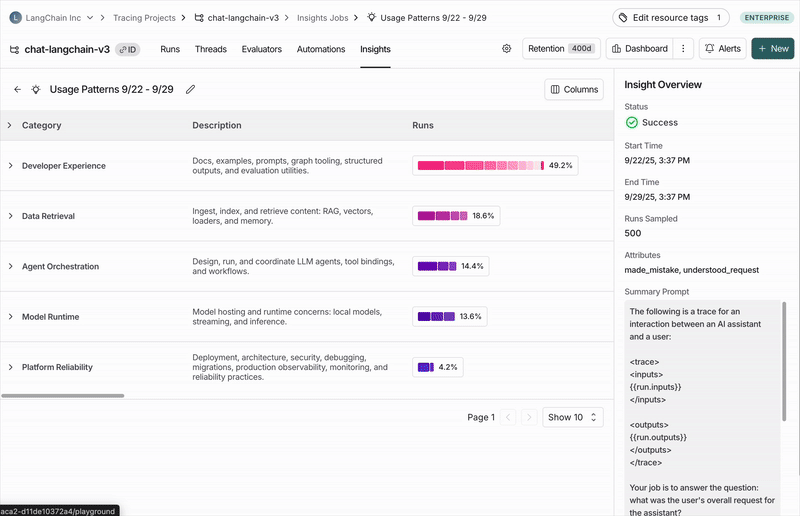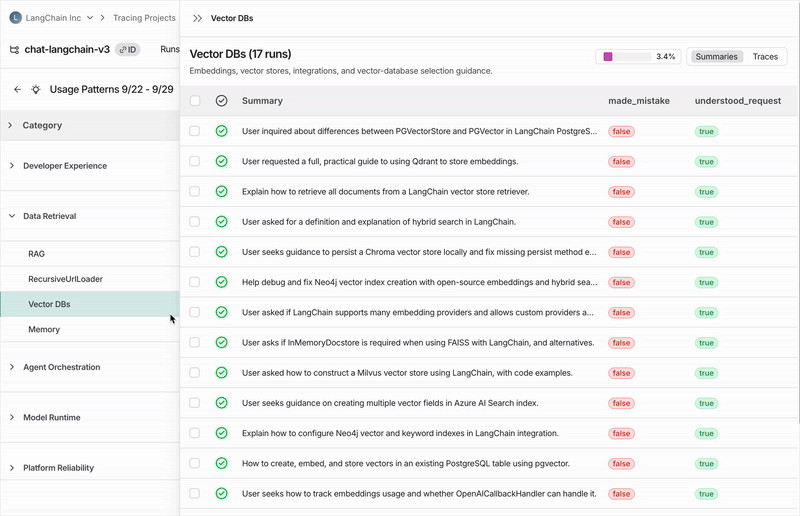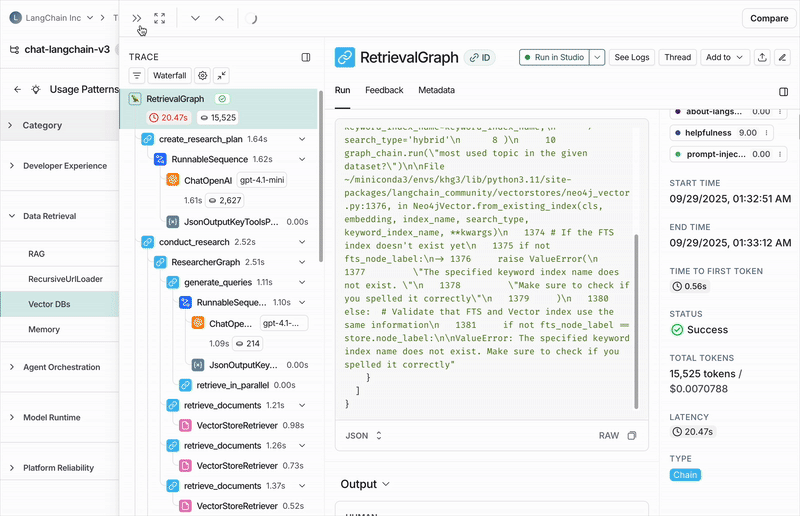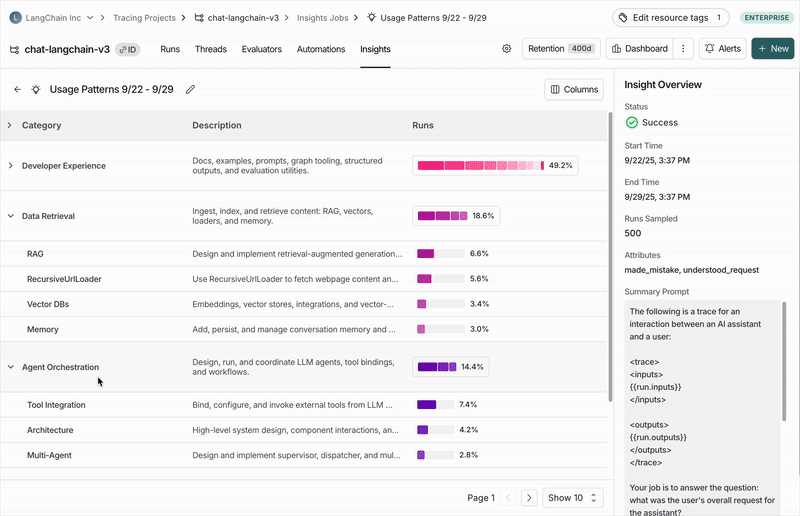
执行摘要
在每个报告的顶部,您会找到一个执行摘要,其中列出了在您的追踪数据中发现的最重要模式。这包括:- 关键发现,并附有显示每个模式出现频率的百分比。
- 可点击的引用(例如,#1, #2, #3),指向代理识别为与您的问题特别相关的追踪数据。
顶级类别
您的追踪数据会自动分组到代表数据中最广泛模式的顶级类别中。 分布条显示了每个模式出现的频率,便于发现比预期发生更多或更少的行为。 每个类别都有一个简短的描述,并显示其所包含追踪数据的聚合指标,包括:- 典型的追踪统计信息(如错误率、延迟、成本)
- 来自评估者的反馈分数
- 作为任务一部分提取的属性
子类别
点击任何类别会显示其细分为子类别,这使您能更细致地理解该类追踪数据中的交互模式。 在 Chat Langchain 示例中,数据与检索 下有如 向量存储 和 数据摄取 这样的子类别。单个追踪数据
您可以点击查看分配给每个类别或子类别的追踪数据,进入追踪数据表格。从那里,您可以点击任何追踪数据以查看完整的对话详情。配置任务
您可以使用自动生成的流程或通过手动配置来创建 Insights 报告。自动生成配置
- 打开 新建 Insights 并确保 自动 切换开关处于活动状态。
- 回答关于您代理的目的、您想了解的内容以及追踪数据结构化的自然语言问题。Insights 会将您的答案转换为一个草稿配置(任务名称、摘要提示、属性和采样默认值)。
- 选择一个提供商,然后点击 生成配置 进行预览,或点击 运行任务 立即启动。
选择模型
Insights 使用两种模型:- 思考模型:执行聚类步骤(能力更强,成本更高)。
- 摘要模型:生成每个追踪数据的摘要(速度更快,成本更低)。
手动配置
手动配置为您提供更多控制权——例如,预定义您希望数据分组到的类别,或针对匹配特定反馈分数和筛选条件的追踪数据。选择追踪数据
- 样本大小:要分析的最大追踪数据数量。目前上限为 1,000 条
- 时间范围:从此时间范围内采样追踪数据
- 筛选器:额外的追踪数据筛选器。调整筛选器时,您将看到有多少追踪数据符合您的条件
类别
默认情况下,顶级类别是从底层追踪数据自底向上自动生成的。 在某些情况下,您事先知道感兴趣的特定类别,并希望任务将追踪数据分到这些预定义的类别中。 配置的 类别 部分允许您通过枚举您希望使用的顶级类别的名称和描述来实现这一点。 子类别仍然由算法在预定义的顶级类别内自动生成。 当任务完成时,发现的顶级类别会自动保存回配置中——但前提是配置之前没有定义任何类别。这意味着后续的定时运行将重用这些类别以保持一致性。摘要提示
任务的第一步是为每条追踪数据创建一个简短的摘要——正是这些摘要随后被分类。 在摘要中提取正确的信息对于获得有用的类别至关重要。 用于生成这些摘要的提示是可以编辑的。 编辑提示时需要考虑的两点是:- 摘要指令:任何不在追踪摘要中的信息都不会影响生成的类别,因此请确保提供清晰的指令,说明从每条追踪数据中提取哪些重要信息。
- 追踪内容:使用 mustache 格式来指定将每条追踪数据的哪些部分传递给摘要器。包含大量输入和输出的大型追踪数据可能成本高昂且噪声大。将提示减少到仅包含追踪数据中最相关的部分可以改善您的结果。
| 变量 | 描述 | 示例 |
|---|---|---|
run.inputs | 最近一次根运行的输入 | {{run.inputs}} |
run.outputs | 最近一次根运行的输出 | {{run.outputs}} |
run.error | 错误字符串(如果运行失败) | {{run.error}} |
run.feedback | 所有反馈分数的 JSON 数据块 | {{run.feedback}} |
run.feedback.<key> | 按键指定的特定反馈分数 | {{run.feedback.correctness}} |
all_thread_messages | 线程的完整消息历史记录(仅适用于具有线程的项目) | {{all_thread_messages}} |
{{run.inputs.foo.bar}} 仅包含最后一次运行输入中 foo 内的 bar 字段。
对于具有线程的项目,Insights 会分析完整的对话。每个线程中只有最近的根运行用于
run.* 变量。使用 all_thread_messages 来访问完整的对话历史记录。属性
除了摘要之外,您还可以定义要从每条追踪数据中提取的额外字符串、数值和布尔属性。 这些属性将影响分类步骤——具有相似属性值的追踪数据往往会被归类在一起。 您还可以查看每个类别中这些属性的聚合值。 例如,您可能希望从每条追踪数据中提取属性user_satisfied: boolean,以引导算法将正面和负面用户体验区分开来的类别,并查看每个类别的平均用户满意度。
筛选属性
您可以在布尔属性上使用filter_by 参数,在生成洞察之前预先筛选追踪数据。启用后,只有属性评估为 true 的追踪数据才会包含在分析中。
当您希望将 Insights 报告聚焦于特定的追踪数据子集时,这非常有用——例如,仅分析错误、仅检查英语对话,或仅包含符合特定质量标准的追踪数据。
工作原理:
- 为 Insights Agent 创建配置时,在任何布尔属性中添加
"filter_by": true。 - LLM 在摘要生成过程中根据属性描述评估每条追踪数据。
- 属性为
false或缺失的追踪数据在生成洞察之前被排除。
定时运行 Insights 报告
安排 Insights 报告按重复计划自动运行。在创建或编辑配置时,使用 计划 部分选择:- 每日:每天 UTC 时间 8:00 运行。
- 每周一:每周一 UTC 时间 8:00 运行。
- 自定义:输入您自己的 cron 表达式(UTC 时间)。
保存您的配置
您可以选择使用“另存为”按钮保存配置以供将来重用。 如果您想比较不同时间的 Insights 报告以识别用户和代理行为的变化,这尤其有用。 在创建新的 Insights 报告时,可以在窗格左上角的下拉菜单中选择先前保存的配置。Connect these docs to Claude, VSCode, and more via MCP for real-time answers.