

将追踪记录分组到线程中
线程 是代表单次对话的一系列追踪记录。每次响应都表示为独立的追踪记录,但这些追踪记录通过属于同一线程而相互关联。 要将追踪记录关联在一起,你需要传入一个特殊的metadata 键,其值为该线程的唯一标识符。键名应为以下之一:
session_idthread_idconversation_id
f47ac10b-58cc-4372-a567-0e02b2c3d479。查看 向追踪记录添加元数据和标签 获取操作指南。
示例
此示例演示了如何使用结构化的消息格式来记录和检索对话历史,以维护长期运行的聊天。get_chat_history=True/getChatHistory: true,你可以从上次中断的地方继续对话。这意味着 LLM 将接收整个消息历史并据此响应,而不仅仅是响应最新消息。
查看线程
你可以在任何项目详情页中点击 Threads 标签页来查看线程。然后你将看到所有线程的列表,按最近活动排序。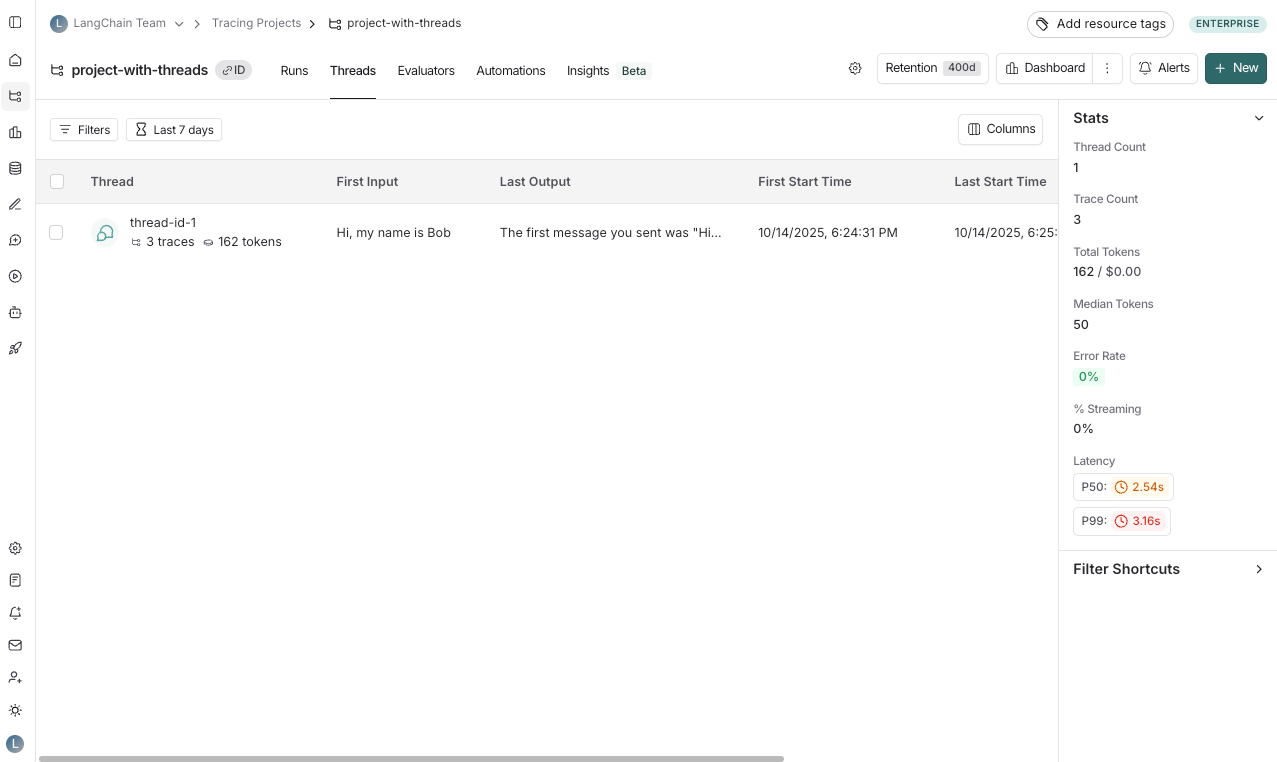
在线程视图中使用 Polly 来分析对话线程、理解用户情绪、识别痛点并跟踪问题是否得到解决。
查看单个线程
你可以点击进入特定线程。这将打开该特定线程的历史记录。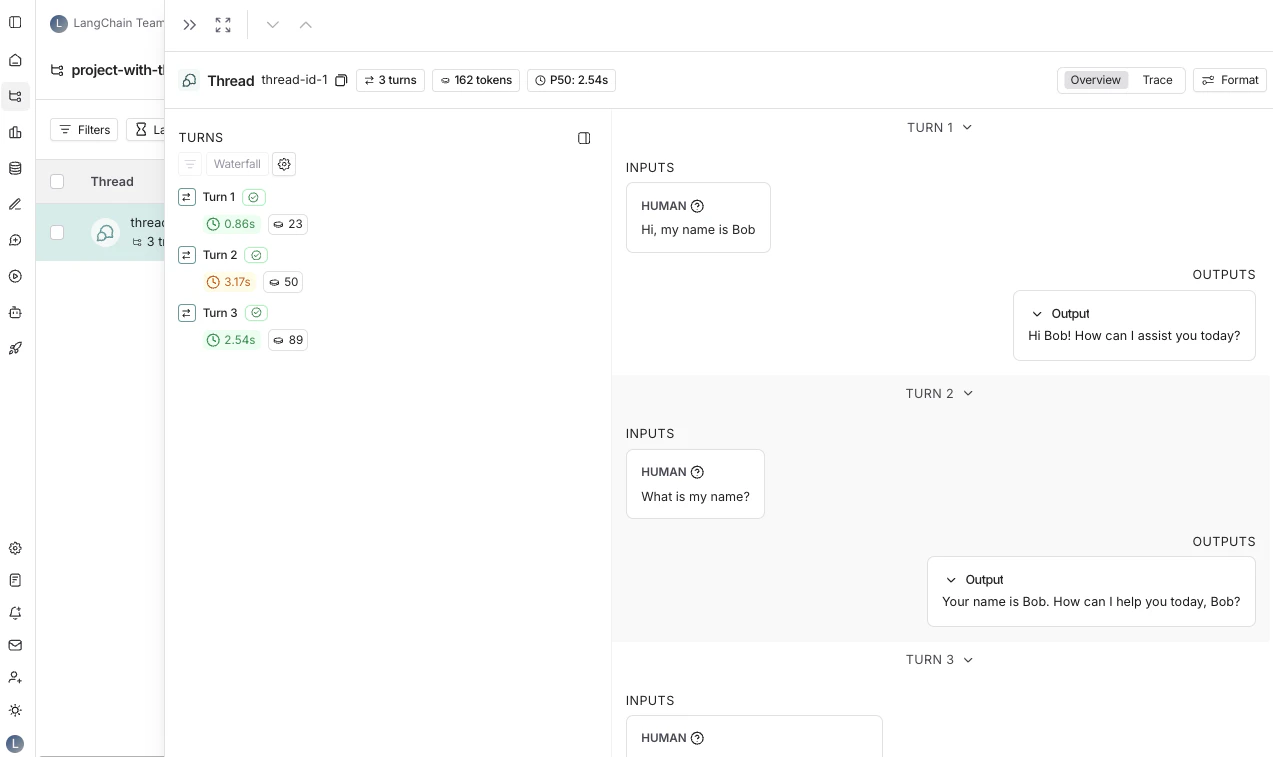
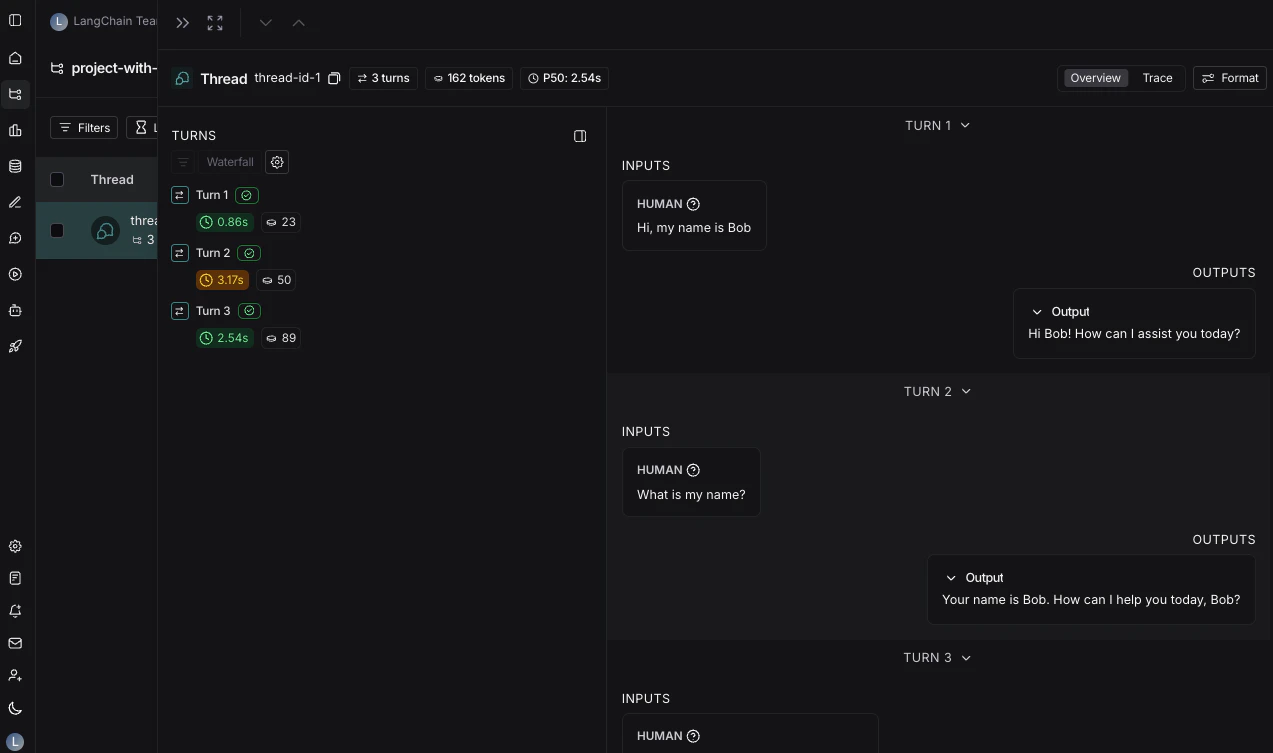
T 在两种视图之间切换。
线程概览
线程概览页面显示类似聊天机器人的界面,你可以看到对话每一轮的输入和输出。你可以配置在概览中显示输入和输出的哪些字段,或通过点击 Configure 按钮显示多个字段。 输入和输出的 JSON 路径支持负索引,因此你可以使用-1 来访问数组的最后一个元素。例如,inputs.messages[-1].content 将访问 messages 数组中的最后一条消息。
追踪视图
这里的追踪视图类似于查看单个运行时的追踪视图,不同之处在于你可以轻松访问线程中每一轮的所有运行。查看反馈
查看线程时,在页面顶部你会看到一个名为Feedback 的部分。在这里你可以看到构成线程的每个运行的反馈。这些反馈是聚合的,因此如果你对线程的每个运行评估相同的标准,你将看到所有运行的平均分数。你也可以在这里看到留下的 线程级别反馈。
保存线程级别筛选器
线程筛选器会检查所有运行,如果至少有一个运行匹配筛选条件,就会显示该线程。
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.