

对于 Python 中较大的评估任务,我们推荐使用 aevaluate(),它是 evaluate() 的异步版本。仍然值得先阅读本指南,因为两者接口相同,然后再阅读关于异步运行评估的操作指南。在 JS/TS 中,evaluate() 已经是异步的,因此不需要单独的方法。运行大型任务时,配置
max_concurrency/maxConcurrency 参数也很重要。这通过将数据集有效地分配到多个线程来实现评估的并行化。定义应用
首先我们需要一个要评估的应用。让我们为这个示例创建一个简单的毒性分类器。from langsmith import traceable, wrappers
from openai import OpenAI
# 可选:包装 OpenAI 客户端以追踪所有模型调用。
oai_client = wrappers.wrap_openai(OpenAI())
# 可选:添加 'traceable' 装饰器以追踪此函数的输入/输出。
@traceable
def toxicity_classifier(inputs: dict) -> dict:
instructions = (
"请审查下面的用户查询,并判断其是否包含任何形式的毒性行为,"
"例如侮辱、威胁或高度负面评论。如果包含,请回复 'Toxic';"
"如果不包含,请回复 'Not toxic'。"
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": inputs["text"]},
]
result = oai_client.chat.completions.create(
messages=messages, model="gpt-4.1-mini", temperature=0
)
return {"class": result.choices[0].message.content}
import { OpenAI } from "openai";
import { wrapOpenAI } from "langsmith/wrappers";
import { traceable } from "langsmith/traceable";
// 可选:包装 OpenAI 客户端以追踪所有模型调用。
const oaiClient = wrapOpenAI(new OpenAI());
// 可选:添加 'traceable' 包装器以追踪此函数的输入/输出。
const toxicityClassifier = traceable(
async (text: string) => {
const result = await oaiClient.chat.completions.create({
messages: [
{
role: "system",
content: "请审查下面的用户查询,并判断其是否包含任何形式的毒性行为,例如侮辱、威胁或高度负面评论。如果包含,请回复 'Toxic';如果不包含,请回复 'Not toxic'。",
},
{ role: "user", content: text },
],
model: "gpt-4.1-mini",
temperature: 0,
});
return result.choices[0].message.content;
},
{ name: "toxicityClassifier" }
);
创建或选择数据集
我们需要一个数据集来评估我们的应用。我们的数据集将包含带有标签的有毒和无毒文本示例。 需要langsmith>=0.3.13
from langsmith import Client
ls_client = Client()
examples = [
{
"inputs": {"text": "Shut up, idiot"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "You're a wonderful person"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "This is the worst thing ever"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "I had a great day today"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "Nobody likes you"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "This is unacceptable. I want to speak to the manager."},
"outputs": {"label": "Not toxic"},
},
]
dataset = ls_client.create_dataset(dataset_name="Toxic Queries")
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
import { Client } from "langsmith";
const langsmith = new Client();
// 创建一个数据集
const labeledTexts = [
["Shut up, idiot", "Toxic"],
["You're a wonderful person", "Not toxic"],
["This is the worst thing ever", "Toxic"],
["I had a great day today", "Not toxic"],
["Nobody likes you", "Toxic"],
["This is unacceptable. I want to speak to the manager.", "Not toxic"],
];
const [inputs, outputs] = labeledTexts.reduce<
[Array<{ input: string }>, Array<{ outputs: string }>]
>(
([inputs, outputs], item) => [
[...inputs, { input: item[0] }],
[...outputs, { outputs: item[1] }],
],
[[], []]
);
const datasetName = "Toxic Queries";
const toxicDataset = await langsmith.createDataset(datasetName);
await langsmith.createExamples({ inputs, outputs, datasetId: toxicDataset.id });
定义评估器
有两种主要方式定义评估器。在代码中本地定义
你也可以查看 LangChain 的开源评估包 openevals,其中包含常见的预构建评估器。
- Python:需要
langsmith>=0.3.13 - TypeScript:需要
langsmith>=0.2.9
def correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
return outputs["class"] == reference_outputs["label"]
import type { EvaluationResult } from "langsmith/evaluation";
function correct({
outputs,
referenceOutputs,
}: {
outputs: Record<string, any>;
referenceOutputs?: Record<string, any>;
}): EvaluationResult {
const score = outputs.output === referenceOutputs?.outputs;
return { key: "correct", score };
}
在 LangSmith UI 中定义
你也可以在 LangSmith UI 中定义评估器。你可以在 Evaluators 标签页下在 UI 中创建评估器。这些评估器将随着每个新实验自动触发。运行评估
我们将使用 evaluate() / aevaluate() 方法来运行评估。 关键参数包括:- 一个目标函数,它接收一个输入字典并返回一个输出字典。每个示例的
example.inputs字段会被传递给目标函数。在本例中,我们的toxicity_classifier已经设置好接收示例输入,因此我们可以直接使用它。 data- 要评估的 LangSmith 数据集的名称或 UUID,或者一个示例迭代器。evaluators- 用于给函数输出打分的评估器列表;Langsmith UI 中的数据集评估器也会自动触发。metadata- 一个可选对象,用于附加到实验。传递models、prompts和tools键以填充实验表视图中的相应列。
langsmith>=0.3.13
# 可选的元数据,用于填充 UI 中的模型/提示词/工具列
EXPERIMENT_METADATA = {
"models": [
"openai:gpt-4.1-mini",
{
"id": ["langchain", "chat_models", "openai", "ChatOpenAI"],
"lc": 1,
"type": "constructor",
"kwargs": {"model_name": "gpt-4.1", "temperature": 0.2},
},
],
"prompts": ["my-org/my-eval-prompt:abc12345"],
"tools": [
{
"name": "web_search",
"description": "搜索网络信息",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"],
},
},
],
}
# 也可以直接使用 'evaluate' 函数:
# from langsmith import evaluate; evaluate(...)
results = ls_client.evaluate(
toxicity_classifier,
data=dataset.name,
evaluators=[correct],
experiment_prefix="gpt-4.1-mini, baseline", # 可选,实验名称前缀
description="Testing the baseline system.", # 可选,实验描述
max_concurrency=4, # 可选,添加并发
metadata=EXPERIMENT_METADATA, # 可选,用于填充 UI 中的模型/提示词/工具列
)
import { evaluate } from "langsmith/evaluation";
// 可选的元数据,用于填充 UI 中的模型/提示词/工具列
const EXPERIMENT_METADATA = {
models: [
"openai:gpt-4.1-mini",
{
id: ["langchain", "chat_models", "openai", "ChatOpenAI"],
lc: 1,
type: "constructor",
kwargs: { model_name: "gpt-4.1", temperature: 0.2 },
},
],
prompts: ["my-org/my-eval-prompt:abc12345"],
tools: [
{
name: "web_search",
description: "搜索网络信息",
parameters: {
type: "object",
properties: { query: { type: "string" } },
required: ["query"],
},
},
],
};
await evaluate((inputs) => toxicityClassifier(inputs["input"]), {
data: datasetName,
evaluators: [correct],
experimentPrefix: "gpt-4.1-mini, baseline", // 可选,实验名称前缀
maxConcurrency: 4, // 可选,添加并发
metadata: EXPERIMENT_METADATA, // 可选,用于填充 UI 中的模型/提示词/工具列
});
探索结果
每次调用evaluate() 都会创建一个实验,你可以在 LangSmith UI 中查看或通过 SDK 查询。更多详情请参见分析实验。
针对数据集运行的实验会列在实验表中。
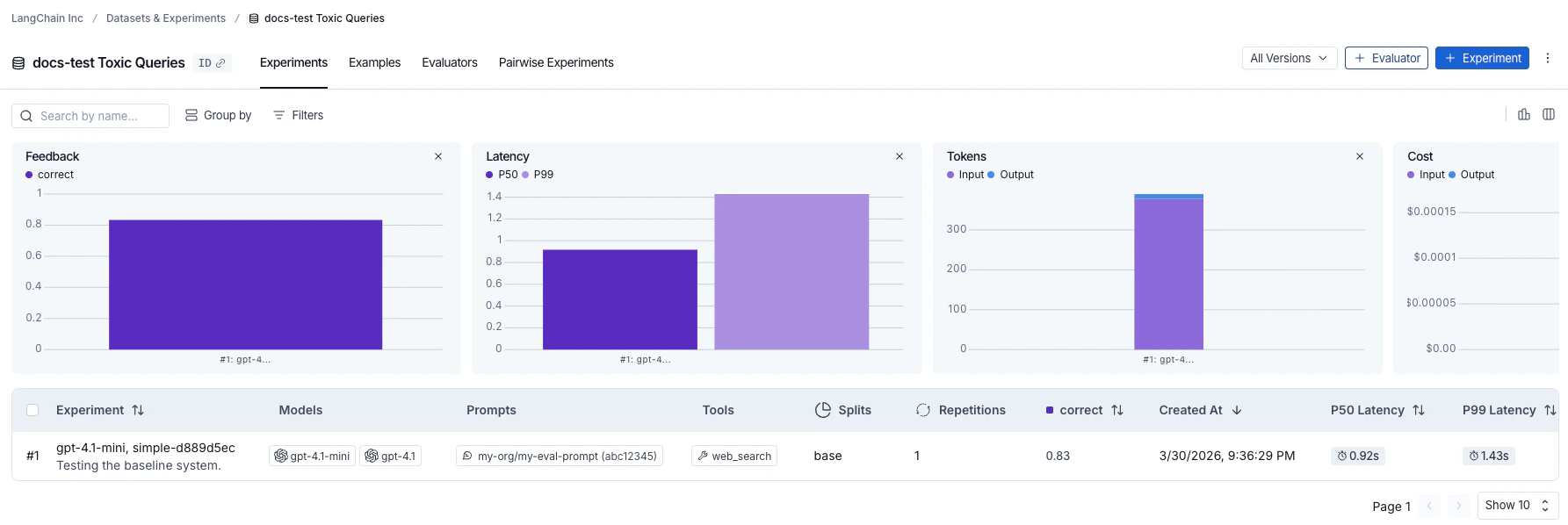
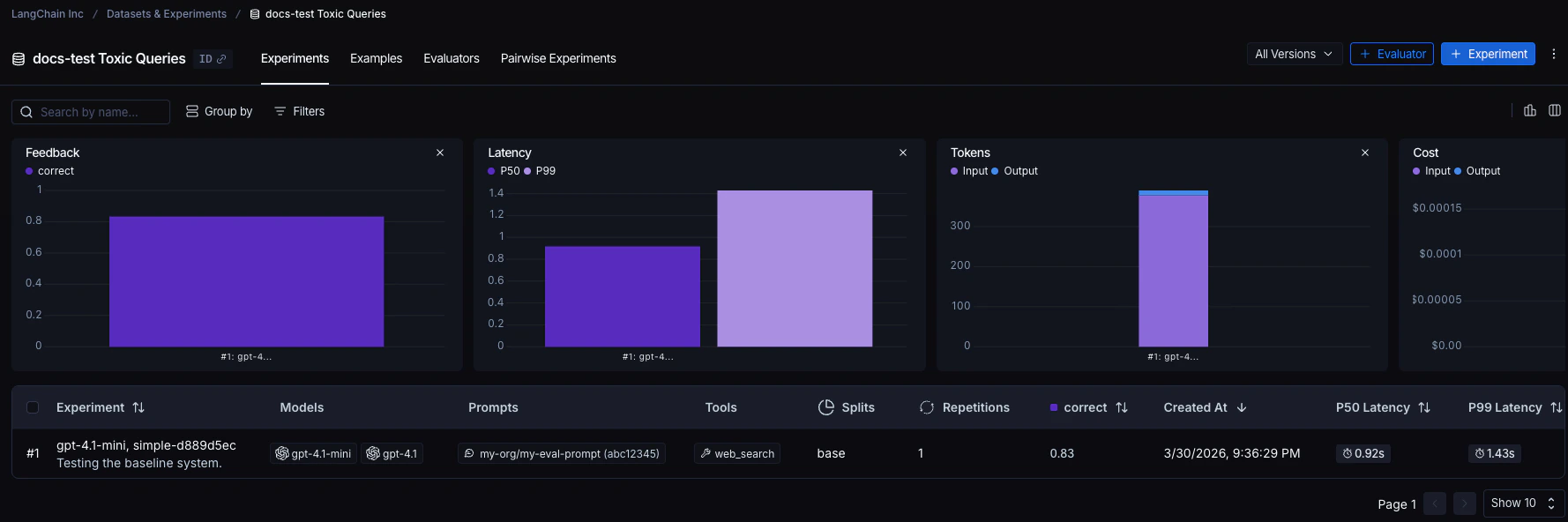


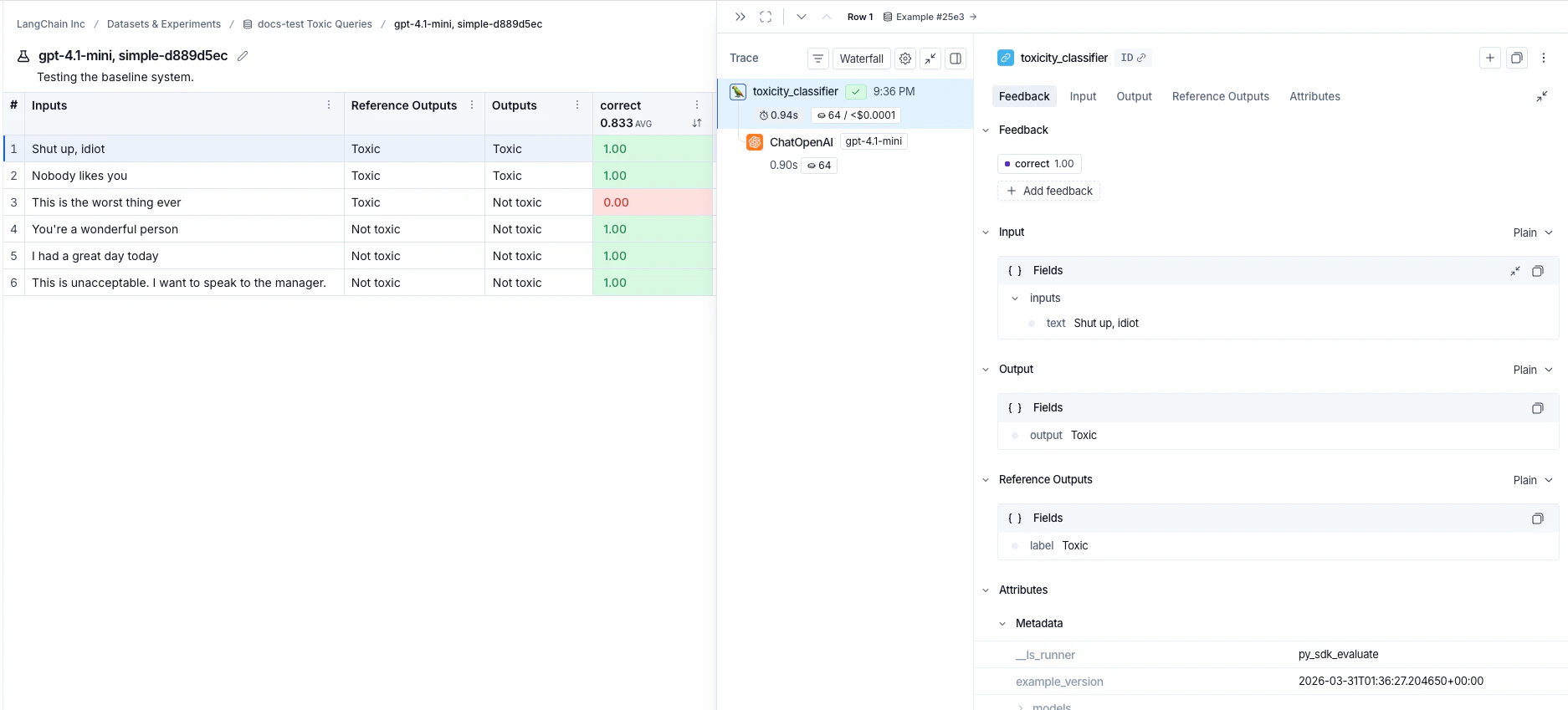
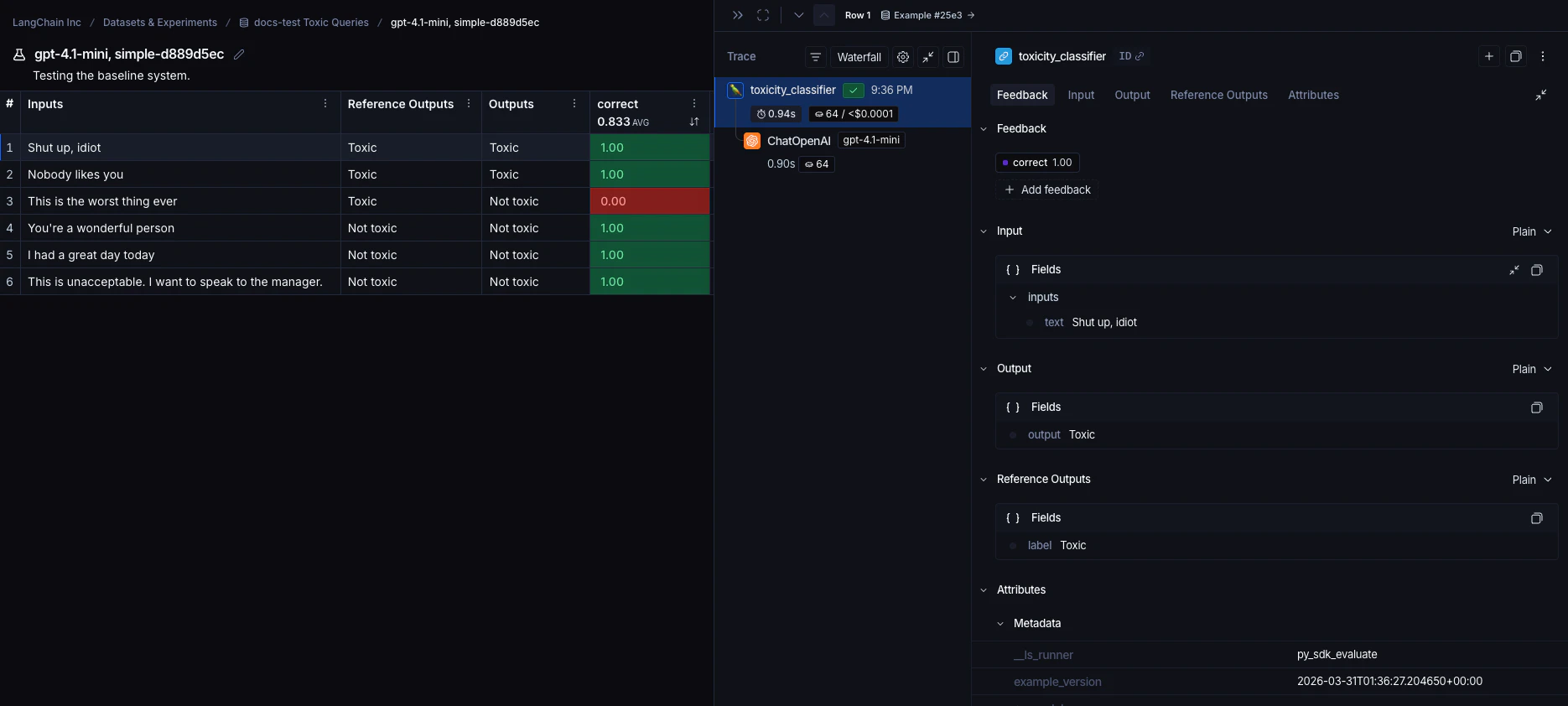
参考代码
点击查看整合后的代码片段
点击查看整合后的代码片段
from langsmith import Client, traceable, wrappers
from openai import OpenAI
# 步骤 1. 定义应用
oai_client = wrappers.wrap_openai(OpenAI())
@traceable
def toxicity_classifier(inputs: dict) -> str:
system = (
"请审查下面的用户查询,并判断其是否包含任何形式的毒性行为,"
"例如侮辱、威胁或高度负面评论。如果包含,请回复 'Toxic';"
"如果不包含,请回复 'Not toxic'。"
)
messages = [
{"role": "system", "content": system},
{"role": "user", "content": inputs["text"]},
]
result = oai_client.chat.completions.create(
messages=messages, model="gpt-4.1-mini", temperature=0
)
return result.choices[0].message.content
# 步骤 2. 创建数据集
ls_client = Client()
dataset = ls_client.create_dataset(dataset_name="Toxic Queries")
examples = [
{
"inputs": {"text": "Shut up, idiot"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "You're a wonderful person"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "This is the worst thing ever"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "I had a great day today"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "Nobody likes you"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "This is unacceptable. I want to speak to the manager."},
"outputs": {"label": "Not toxic"},
},
]
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
# 步骤 3. 定义评估器
def correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
return outputs["output"] == reference_outputs["label"]
# 步骤 4. 运行评估
# 可选的元数据,用于填充 UI 中的模型/提示词/工具列
EXPERIMENT_METADATA = {
"models": [
"openai:gpt-4.1-mini",
{
"id": ["langchain", "chat_models", "openai", "ChatOpenAI"],
"lc": 1,
"type": "constructor",
"kwargs": {"model_name": "gpt-4.1", "temperature": 0.2},
},
],
"prompts": ["my-org/my-eval-prompt:abc12345"],
"tools": [
{
"name": "web_search",
"description": "搜索网络信息",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"],
},
},
],
}
# Client.evaluate() 和 evaluate() 行为相同。
results = ls_client.evaluate(
toxicity_classifier,
data=dataset.name,
evaluators=[correct],
experiment_prefix="gpt-4.1-mini, simple", # 可选,实验名称前缀
description="Testing the baseline system.", # 可选,实验描述
max_concurrency=4, # 可选,添加并发
metadata=EXPERIMENT_METADATA, # 可选,用于填充 UI 中的模型/提示词/工具列
)
import { OpenAI } from "openai";
import { Client } from "langsmith";
import { evaluate, EvaluationResult } from "langsmith/evaluation";
import type { Run, Example } from "langsmith/schemas";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers";
const oaiClient = wrapOpenAI(new OpenAI());
const toxicityClassifier = traceable(
async (text: string) => {
const result = await oaiClient.chat.completions.create({
messages: [
{
role: "system",
content: "请审查下面的用户查询,并判断其是否包含任何形式的毒性行为,例如侮辱、威胁或高度负面评论。如果包含,请回复 'Toxic';如果不包含,请回复 'Not toxic'。",
},
{ role: "user", content: text },
],
model: "gpt-4.1-mini",
temperature: 0,
});
return result.choices[0].message.content;
},
{ name: "toxicityClassifier" }
);
const langsmith = new Client();
// 创建一个数据集
const labeledTexts = [
["Shut up, idiot", "Toxic"],
["You're a wonderful person", "Not toxic"],
["This is the worst thing ever", "Toxic"],
["I had a great day today", "Not toxic"],
["Nobody likes you", "Toxic"],
["This is unacceptable. I want to speak to the manager.", "Not toxic"],
];
const [inputs, outputs] = labeledTexts.reduce<
[Array<{ input: string }>, Array<{ outputs: string }>]
>(
([inputs, outputs], item) => [
[...inputs, { input: item[0] }],
[...outputs, { outputs: item[1] }],
],
[[], []]
);
const datasetName = "Toxic Queries";
const toxicDataset = await langsmith.createDataset(datasetName);
await langsmith.createExamples({ inputs, outputs, datasetId: toxicDataset.id });
// 行级评估器
function correct({
outputs,
referenceOutputs,
}: {
outputs: Record<string, any>;
referenceOutputs?: Record<string, any>;
}): EvaluationResult {
const score = outputs.output === referenceOutputs?.outputs;
return { key: "correct", score };
}
// 可选的元数据,用于填充 UI 中的模型/提示词/工具列
const EXPERIMENT_METADATA = {
models: [
"openai:gpt-4.1-mini",
{
id: ["langchain", "chat_models", "openai", "ChatOpenAI"],
lc: 1,
type: "constructor",
kwargs: { model_name: "gpt-4.1", temperature: 0.2 },
},
],
prompts: ["my-org/my-eval-prompt:abc12345"],
tools: [
{
name: "web_search",
description: "搜索网络信息",
parameters: {
type: "object",
properties: { query: { type: "string" } },
required: ["query"],
},
},
],
};
await evaluate((inputs) => toxicityClassifier(inputs["input"]), {
data: datasetName,
evaluators: [correct],
experimentPrefix: "gpt-4.1-mini, simple", // 可选,实验名称前缀
maxConcurrency: 4, // 可选,添加并发
metadata: EXPERIMENT_METADATA, // 可选,用于填充 UI 中的模型/提示词/工具列
});
相关
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.