在使用 LangSmith 跟踪时,您可能需要防止记录敏感信息,以维护隐私并满足安全要求。LangSmith 提供了多种方法来保护您的数据,然后再将其发送到后端:
如果您的合规或隐私要求规定某些操作根本不应被跟踪(例如,具有零保留策略的客户端),请考虑使用条件跟踪来有选择地为特定请求禁用跟踪,而不是对数据进行掩码处理。 隐藏输入和输出
如果您想完全隐藏跟踪的输入和输出,可以在运行应用程序时设置以下环境变量:
LANGSMITH_HIDE_INPUTS=true
LANGSMITH_HIDE_OUTPUTS=true
hide_inputs 和 hide_outputs 参数来完成(在 TypeScript 中为 hideInputs 和 hideOutputs)。
以下示例为 hide_inputs 和 hide_outputs 都返回一个空对象,但您可以根据需要自定义:
import openai
from langsmith import Client
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(openai.Client())
langsmith_client = Client(
hide_inputs=lambda inputs: {}, hide_outputs=lambda outputs: {}
)
# 生成的跟踪将保留其元数据,但输入将被隐藏
openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "你好!"},
],
langsmith_extra={"client": langsmith_client},
)
# 生成的跟踪不会隐藏输入和输出
openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "你好!"},
],
)
import OpenAI from "openai";
import { Client } from "langsmith";
import { wrapOpenAI } from "langsmith/wrappers";
const langsmithClient = new Client({
hideInputs: (inputs) => ({}),
hideOutputs: (outputs) => ({}),
});
// 生成的跟踪将保留其元数据,但输入将被隐藏
const filteredOAIClient = wrapOpenAI(new OpenAI(), {
client: langsmithClient,
});
await filteredOAIClient.chat.completions.create({
model: "gpt-4.1-mini",
messages: [
{ role: "system", content: "你是一个乐于助人的助手。" },
{ role: "user", content: "你好!" },
],
});
const openaiClient = wrapOpenAI(new OpenAI());
// 生成的跟踪不会隐藏输入和输出
await openaiClient.chat.completions.create({
model: "gpt-4.1-mini",
messages: [
{ role: "system", content: "你是一个乐于助人的助手。" },
{ role: "user", content: "你好!" },
],
});
隐藏元数据
hide_metadata 参数允许您控制在使用 LangSmith Python SDK 进行跟踪时,是否隐藏或转换运行元数据。元数据在创建运行时通过 extra 参数传递(例如,extra={"metadata": {...}})。hide_metadata 对于删除敏感信息、遵守隐私要求或减少发送到 LangSmith 的数据量非常有用。您可以通过两种方式配置元数据隐藏:
-
使用 SDK:
from langsmith import Client
client = Client(hide_metadata=True)
-
使用环境变量:
export LANGSMITH_HIDE_METADATA=true
hide_metadata 参数接受三种类型的值:
True:完全删除所有元数据(发送空字典)。False 或 None:按原样保留元数据(默认行为)。Callable:转换元数据字典的自定义函数。
设置后,此参数将影响 Client 创建或更新的所有运行的 extra 参数中的 metadata 字段,包括通过 @traceable 装饰器或 LangChain 集成创建的运行。
隐藏所有元数据
设置 hide_metadata=True 以完全删除发送到 LangSmith 的运行中的所有元数据:
from langsmith import Client
# 完全隐藏所有元数据
client = Client(hide_metadata=True)
# 现在,当您创建运行时,元数据将为空
client.create_run(
"my_run",
inputs={"question": "2+2 等于多少?"},
run_type="llm",
extra={"metadata": {"user_id": "123", "session": "abc"}}
)
# 发送到 LangSmith 的元数据将是 {},而不是提供的元数据
自定义转换
使用可调用函数有选择地过滤、编辑或修改发送到 LangSmith 之前的元数据:
# 删除敏感键
def hide_sensitive_metadata(metadata: dict) -> dict:
return {k: v for k, v in metadata.items() if not k.startswith("_private")}
client = Client(hide_metadata=hide_sensitive_metadata)
# 编辑特定值
def redact_emails(metadata: dict) -> dict:
import re
result = {}
for k, v in metadata.items():
if isinstance(v, str) and "@" in v:
result[k] = "[已编辑_EMAIL]"
else:
result[k] = v
return result
client = Client(hide_metadata=redact_emails)
# 添加转换标记
def add_marker(metadata: dict) -> dict:
return {**metadata, "transformed": True}
client = Client(hide_metadata=add_marker)
基于规则的输入和输出掩码
此功能在以下 LangSmith SDK 版本中可用:
- Python:0.1.81 及更高版本
- TypeScript:0.1.33 及更高版本
create_anonymizer / createAnonymizer 函数,并在实例化 Client 时传递新创建的匿名化器。匿名化器可以从正则表达式模式和替换值的列表构建,也可以从接受并返回字符串值的函数构建。
如果设置了 LANGSMITH_HIDE_INPUTS = true,则匿名化器将跳过输入。如果设置了 LANGSMITH_HIDE_OUTPUTS = true,则输出同样如此。
但是,如果输入或输出要发送给 Client,则 anonymizer 方法将优先于 hide_inputs 和 hide_outputs 中的函数。默认情况下,create_anonymizer 只会查看最多 10 层深度,这可以通过 max_depth 参数进行配置。
from langsmith.anonymizer import create_anonymizer
from langsmith import Client, traceable
import re
# 从正则表达式模式和替换值列表创建匿名化器
anonymizer = create_anonymizer([
{ "pattern": r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}", "replace": "<电子邮件地址>" },
{ "pattern": r"[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}", "replace": "<UUID>" }
])
# 或从函数创建匿名化器
email_pattern = re.compile(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}")
uuid_pattern = re.compile(r"[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}")
anonymizer = create_anonymizer(
lambda text: email_pattern.sub("<电子邮件地址>", uuid_pattern.sub("<UUID>", text))
)
client = Client(anonymizer=anonymizer)
@traceable(client=client)
def main(inputs: dict) -> dict:
...
import { createAnonymizer } from "langsmith/anonymizer"
import { traceable } from "langsmith/traceable"
import { Client } from "langsmith"
// 从正则表达式模式和替换值列表创建匿名化器
const anonymizer = createAnonymizer([
{ pattern: /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/g, replace: "<电子邮件>" },
{ pattern: /[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}/g, replace: "<uuid>" }
])
// 或从函数创建匿名化器
const anonymizer = createAnonymizer((value) => value.replace("...", "<值>"))
const client = new Client({ anonymizer })
const main = traceable(async (inputs: any) => {
// ...
}, { client })
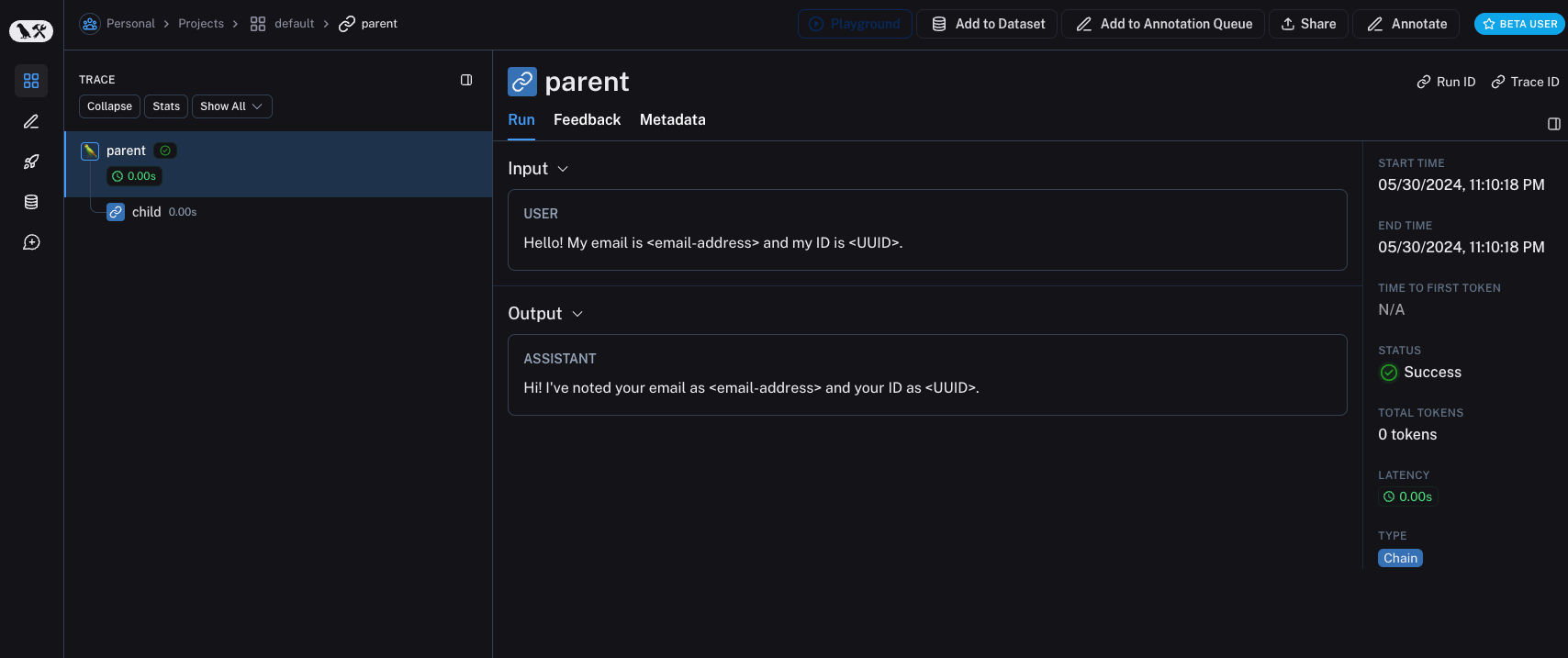 较旧版本的 LangSmith SDK 可以使用
较旧版本的 LangSmith SDK 可以使用 hide_inputs 和 hide_outputs 参数来实现相同的效果。您也可以使用这些参数更高效地处理输入和输出。
import re
from langsmith import Client, traceable
# 定义电子邮件地址和 UUID 的正则表达式模式
EMAIL_REGEX = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}"
UUID_REGEX = r"[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}"
def replace_sensitive_data(data, depth=10):
if depth == 0:
return data
if isinstance(data, dict):
return {k: replace_sensitive_data(v, depth-1) for k, v in data.items()}
elif isinstance(data, list):
return [replace_sensitive_data(item, depth-1) for item in data]
elif isinstance(data, str):
data = re.sub(EMAIL_REGEX, "<电子邮件地址>", data)
data = re.sub(UUID_REGEX, "<UUID>", data)
return data
else:
return data
client = Client(
hide_inputs=lambda inputs: replace_sensitive_data(inputs),
hide_outputs=lambda outputs: replace_sensitive_data(outputs)
)
inputs = {"role": "user", "content": "你好!我的电子邮件是 user@example.com,我的 ID 是 123e4567-e89b-12d3-a456-426614174000。"}
outputs = {"role": "assistant", "content": "嗨!我已将您的电子邮件记录为 user@example.com,将您的 ID 记录为 123e4567-e89b-12d3-a456-426614174000。"}
@traceable(client=client)
def child(inputs: dict) -> dict:
return outputs
@traceable(client=client)
def parent(inputs: dict) -> dict:
child_outputs = child(inputs)
return child_outputs
parent(inputs)
import { Client } from "langsmith";
import { traceable } from "langsmith/traceable";
// 定义电子邮件地址和 UUID 的正则表达式模式
const EMAIL_REGEX = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/g;
const UUID_REGEX = /[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}/g;
function replaceSensitiveData(data: any, depth: number = 10): any {
if (depth === 0) return data;
if (typeof data === "object" && !Array.isArray(data)) {
const result: Record<string, any> = {};
for (const [key, value] of Object.entries(data)) {
result[key] = replaceSensitiveData(value, depth - 1);
}
return result;
} else if (Array.isArray(data)) {
return data.map(item => replaceSensitiveData(item, depth - 1));
} else if (typeof data === "string") {
return data.replace(EMAIL_REGEX, "<电子邮件地址>").replace(UUID_REGEX, "<UUID>");
} else {
return data;
}
}
const langsmithClient = new Client({
hideInputs: (inputs) => replaceSensitiveData(inputs),
hideOutputs: (outputs) => replaceSensitiveData(outputs)
});
const inputs = {
role: "user",
content: "你好!我的电子邮件是 user@example.com,我的 ID 是 123e4567-e89b-12d3-a456-426614174000。"
};
const outputs = {
role: "assistant",
content: "嗨!我已将您的电子邮件记录为 <电子邮件地址>,将您的 ID 记录为 <UUID>。"
};
const child = traceable(async (inputs: any) => {
return outputs;
}, { name: "child", client: langsmithClient });
const parent = traceable(async (inputs: any) => {
const childOutputs = await child(inputs);
return childOutputs;
}, { name: "parent", client: langsmithClient });
await parent(inputs);
处理单个函数的输入和输出
process_outputs 参数在 Python 的 LangSmith SDK 0.1.98 及更高版本中可用。
@traceable 装饰器的 process_inputs 和 process_outputs 参数提供函数级处理。
这些参数接受函数,允许您在将特定函数的输入和输出记录到 LangSmith 之前对其进行转换。这对于减少负载大小、删除敏感信息或自定义对象在 LangSmith 中为特定函数序列化和表示的方式非常有用。
以下是使用 process_inputs 和 process_outputs 的示例:
from langsmith import traceable
def process_inputs(inputs: dict) -> dict:
# inputs 是一个字典,其中键是参数名称,值是提供的参数
# 返回一个包含处理后输入的新字典
return {
"processed_key": inputs.get("my_cool_key", "default"),
"length": len(inputs.get("my_cool_key", ""))
}
def process_outputs(output: Any) -> dict:
# output 是函数的直接返回值
# 将输出转换为字典
# 在此例中,"output" 将是一个整数
return {"processed_output": str(output)}
@traceable(process_inputs=process_inputs, process_outputs=process_outputs)
def my_function(my_cool_key: str) -> int:
# 函数实现
return len(my_cool_key)
result = my_function("example")
process_inputs 创建一个包含处理后输入数据的新字典,process_outputs 在记录到 LangSmith 之前将输出转换为特定格式。
建议避免在处理函数中修改源对象。相反,应创建并返回包含处理后数据的新对象。
@traceable(process_inputs=process_inputs, process_outputs=process_outputs)
async def async_function(key: str) -> int:
# 异步实现
return len(key)
hide_inputs 和 hide_outputs)。
您可以将基于规则的掩码与各种匿名化器结合使用,以清除输入和输出中的敏感信息。以下示例将涵盖使用正则表达式、Microsoft Presidio 和 Amazon Comprehend。
正则表达式
下面的实现并不详尽,可能会遗漏某些格式或边缘情况。在生产环境中使用之前,请彻底测试任何实现。
import re
import openai
from langsmith import Client
from langsmith.wrappers import wrap_openai
# 为各种 PII 定义正则表达式模式
SSN_PATTERN = re.compile(r'\b\d{3}-\d{2}-\d{4}\b')
CREDIT_CARD_PATTERN = re.compile(r'\b(?:\d[ -]*?){13,16}\b')
EMAIL_PATTERN = re.compile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b')
PHONE_PATTERN = re.compile(r'\b(?:\+?1[-.\s]?)?\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4}\b')
FULL_NAME_PATTERN = re.compile(r'\b([A-Z][a-z]*\s[A-Z][a-z]*)\b')
def regex_anonymize(text):
"""
使用正则表达式模式匿名化文本中的敏感信息。
参数:
text (str):要匿名化的输入文本。
返回:
str:匿名化后的文本。
"""
# 用占位符替换敏感信息
text = SSN_PATTERN.sub('[已编辑 SSN]', text)
text = CREDIT_CARD_PATTERN.sub('[已编辑信用卡]', text)
text = EMAIL_PATTERN.sub('[已编辑电子邮件]', text)
text = PHONE_PATTERN.sub('[已编辑电话号码]', text)
text = FULL_NAME_PATTERN.sub('[已编辑姓名]', text)
return text
def recursive_anonymize(data, depth=10):
"""
递归遍历数据结构并匿名化敏感信息。
参数:
data (any):要匿名化的输入数据。
depth (int):当前递归深度,以防止过度递归。
返回:
any:匿名化后的数据。
"""
if depth == 0:
return data
if isinstance(data, dict):
anonymized_dict = {}
for k, v in data.items():
anonymized_value = recursive_anonymize(v, depth - 1)
anonymized_dict[k] = anonymized_value
return anonymized_dict
elif isinstance(data, list):
anonymized_list = []
for item in data:
anonymized_item = recursive_anonymize(item, depth - 1)
anonymized_list.append(anonymized_item)
return anonymized_list
elif isinstance(data, str):
anonymized_data = regex_anonymize(data)
return anonymized_data
else:
return data
openai_client = wrap_openai(openai.Client())
# 使用匿名化函数初始化 LangSmith @[Client]
langsmith_client = Client(
hide_inputs=recursive_anonymize, hide_outputs=recursive_anonymize
)
# 生成的跟踪将保留其元数据,但输入和输出将被匿名化
response_with_anonymization = openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "我叫 John Doe,我的 SSN 是 123-45-6789,我的信用卡号是 4111 1111 1111 1111,我的电子邮件是 john.doe@example.com,我的电话号码是 (123) 456-7890。"},
],
langsmith_extra={"client": langsmith_client},
)
# 生成的跟踪不会匿名化输入和输出
response_without_anonymization = openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "我叫 John Doe,我的 SSN 是 123-45-6789,我的信用卡号是 4111 1111 1111 1111,我的电子邮件是 john.doe@example.com,我的电话号码是 (123) 456-7890。"},
],
)
 在 LangSmith 中,未匿名化的运行将如下所示:
在 LangSmith 中,未匿名化的运行将如下所示:
Microsoft Presidio
下面的实现提供了一个关于如何匿名化用户和 LLM 之间交换的消息中的敏感信息的通用示例。它并不详尽,也没有涵盖所有情况。在生产环境中使用之前,请彻底测试任何实现。
pip install presidio-analyzer
pip install presidio-anonymizer
python -m spacy download en_core_web_lg
uv add presidio-analyzer
uv add presidio-anonymizer
python -m spacy download en_core_web_lg
import openai
from langsmith import Client
from langsmith.wrappers import wrap_openai
from presidio_anonymizer import AnonymizerEngine
from presidio_analyzer import AnalyzerEngine
anonymizer = AnonymizerEngine()
analyzer = AnalyzerEngine()
def presidio_anonymize(data):
"""
匿名化用户发送或模型返回的敏感信息。
参数:
data (any):要匿名化的数据。
返回:
any:匿名化后的数据。
"""
message_list = (
data.get('messages') or [data.get('choices', [{}])[0].get('message')]
)
if not message_list or not all(isinstance(msg, dict) and msg for msg in message_list):
return data
for message in message_list:
content = message.get('content', '')
if not content.strip():
print("检测到空内容。跳过匿名化。")
continue
results = analyzer.analyze(
text=content,
entities=["PERSON", "PHONE_NUMBER", "EMAIL_ADDRESS", "US_SSN"],
language='en'
)
anonymized_result = anonymizer.anonymize(
text=content,
analyzer_results=results
)
message['content'] = anonymized_result.text
return data
openai_client = wrap_openai(openai.Client())
# 使用匿名化函数初始化 LangSmith @[Client]
langsmith_client = Client(
hide_inputs=presidio_anonymize, hide_outputs=presidio_anonymize
)
# 生成的跟踪将保留其元数据,但输入和输出将被匿名化
response_with_anonymization = openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "我叫 Slim Shady,请拨打 313-666-7440 联系我,或发送电子邮件至 real.slim.shady@gmail.com"},
],
langsmith_extra={"client": langsmith_client},
)
# 生成的跟踪不会匿名化输入和输出
response_without_anonymization = openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "我叫 Slim Shady,请拨打 313-666-7440 联系我,或发送电子邮件至 real.slim.shady@gmail.com"},
],
)
 在 LangSmith 中,未匿名化的运行将如下所示:
在 LangSmith 中,未匿名化的运行将如下所示:
Amazon Comprehend
下面的实现提供了一个关于如何匿名化用户和 LLM 之间交换的消息中的敏感信息的通用示例。它并不详尽,也没有涵盖所有情况。在生产环境中使用之前,请彻底测试任何实现。
import openai
import boto3
from langsmith import Client
from langsmith.wrappers import wrap_openai
comprehend = boto3.client('comprehend', region_name='us-east-1')
def redact_pii_entities(text, entities):
"""
根据检测到的实体编辑文本中的 PII 实体。
参数:
text (str):包含 PII 的原始文本。
entities (list):检测到的 PII 实体列表。
返回:
str:已编辑 PII 实体的文本。
"""
sorted_entities = sorted(entities, key=lambda x: x['BeginOffset'], reverse=True)
redacted_text = text
for entity in sorted_entities:
begin = entity['BeginOffset']
end = entity['EndOffset']
entity_type = entity['Type']
# 根据实体类型定义编辑占位符
placeholder = f"[{entity_type}]"
# 用占位符替换文本中的 PII
redacted_text = redacted_text[:begin] + placeholder + redacted_text[end:]
return redacted_text
def detect_pii(text):
"""
使用 AWS Comprehend 检测给定文本中的 PII 实体。
参数:
text (str):要分析的文本。
返回:
list:检测到的 PII 实体列表。
"""
try:
response = comprehend.detect_pii_entities(
Text=text,
LanguageCode='en',
)
entities = response.get('Entities', [])
return entities
except Exception as e:
print(f"检测 PII 时出错:{e}")
return []
def comprehend_anonymize(data):
"""
匿名化用户发送或模型返回的敏感信息。
参数:
data (any):要匿名化的输入数据。
返回:
any:匿名化后的数据。
"""
message_list = (
data.get('messages') or [data.get('choices', [{}])[0].get('message')]
)
if not message_list or not all(isinstance(msg, dict) and msg for msg in message_list):
return data
for message in message_list:
content = message.get('content', '')
if not content.strip():
print("检测到空内容。跳过匿名化。")
continue
entities = detect_pii(content)
if entities:
anonymized_text = redact_pii_entities(content, entities)
message['content'] = anonymized_text
else:
print("未检测到 PII。内容保持不变。")
return data
openai_client = wrap_openai(openai.Client())
# 使用匿名化函数初始化 LangSmith @[Client]
langsmith_client = Client(
hide_inputs=comprehend_anonymize, hide_outputs=comprehend_anonymize
)
# 生成的跟踪将保留其元数据,但输入和输出将被匿名化
response_with_anonymization = openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "我叫 Slim Shady,请拨打 313-666-7440 联系我,或发送电子邮件至 real.slim.shady@gmail.com"},
],
langsmith_extra={"client": langsmith_client},
)
# 生成的跟踪不会匿名化输入和输出
response_without_anonymization = openai_client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "我叫 Slim Shady,请拨打 313-666-7440 联系我,或发送电子邮件至 real.slim.shady@gmail.com"},
],
)
 在 LangSmith 中,未匿名化的运行将如下所示:
在 LangSmith 中,未匿名化的运行将如下所示: ###面向高吞吐量掩码的批处理
本页之前介绍的方法会逐个处理每个运行。如果你的掩码逻辑涉及速率受限的 API 或模型推理(例如 Presidio 或 Amazon Comprehend 示例),逐个处理运行可能会造成瓶颈。
###面向高吞吐量掩码的批处理
本页之前介绍的方法会逐个处理每个运行。如果你的掩码逻辑涉及速率受限的 API 或模型推理(例如 Presidio 或 Amazon Comprehend 示例),逐个处理运行可能会造成瓶颈。process_buffered_run_ops 允许你在原始运行字典被序列化并发送到 API 之前拦截一批这样的字典,从而将成本分摊到多个运行上。LangSmith 会在后台线程中处理这些运行,不会阻塞你的应用程序。
LangSmith 会将运行保存在内存缓冲区中,并在满足以下任一条件时将它们作为一批数据刷新:
- 累积了
run_ops_buffer_size 个运行操作,或者
- 自上次添加运行以来已过去
run_ops_buffer_timeout_ms 毫秒(默认值:5000 毫秒)。
你的函数会接收到一批原始运行字典(以列表形式),并且必须返回一个 长度相同、顺序相同、运行 ID 不变 的列表。违反任一约束都会引发 ValueError。
run_ops_buffer_size 计数的是单个运行 操作,而不是唯一的运行。每个被追踪的调用通常会产生两个操作:创建(当运行开始时)和更新(当运行结束并带有输出时)。请相应地设置缓冲区大小。例如,run_ops_buffer_size=1000 将缓冲大约 500 次被追踪的调用。正因为如此,同一个运行 ID 可能会在同一批次中出现两次:一次带有输入,一次带有输出。
缓冲区仅在达到大小限制或超时时间到时才会自动刷新。务必在程序退出前调用 client.flush(),以避免丢失缓冲中的运行。
inputs,在运行开始时发送),要么是一个更新操作(包含 outputs,在运行结束时发送)。以下是单次被追踪调用的典型配对示例:
# 创建操作 — 在运行开始时发送
{
"id": "018f1b2c-...",
"name": "my_llm_call",
"run_type": "llm",
"inputs": {"messages": [{"role": "user", "content": "My name is Jane Smith..."}]},
"start_time": "2024-01-01T00:00:00.000Z",
"trace_id": "018f1b2c-...",
"dotted_order": "20240101T000000000000Z018f1b2c-...",
"extra": {"metadata": {}, "runtime": {...}},
"session_name": "default",
}
# 更新操作 — 在运行结束时发送(相同 id,添加 outputs)
{
"id": "018f1b2c-...",
"outputs": {"choices": [{"message": {"role": "assistant", "content": "Hello Jane..."}}]},
"end_time": "2024-01-01T00:00:01.000Z",
"trace_id": "018f1b2c-...",
"dotted_order": "20240101T000000000000Z018f1b2c-...",
}
batch_detect_pii_entities 端点,该端点每次调用最多可接受 25 条文本。采用逐运行方式(hide_inputs)时,每次运行都需要调用一次 API。而在这里,首先收集整个缓冲区中所有消息的文本,然后以 25 条为一批发送给 Comprehend,从而在高吞吐量下显著减少 API 调用次数。
import boto3
from langsmith import Client, traceable
comprehend = boto3.client("comprehend", region_name="us-east-1")
def redact_entities(text: str, entities: list) -> str:
for entity in sorted(entities, key=lambda e: e["BeginOffset"], reverse=True):
placeholder = f"[{entity['Type']}]"
text = text[:entity["BeginOffset"]] + placeholder + text[entity["EndOffset"]:]
return text
def comprehend_anonymize_batch(runs: list[dict]) -> list[dict]:
# 收集所有消息文本,并记住它们来自何处。
# 注意:同一个运行 ID 可能出现两次 — 一次作为创建(带 inputs)
# 一次作为更新(带 outputs)。
locations = [] # (run_idx, field, msg_idx)
texts = []
for run_idx, run in enumerate(runs):
for field in ("inputs", "outputs"):
data = run.get(field)
if not isinstance(data, dict):
continue
for msg_idx, message in enumerate(data.get("messages") or []):
content = message.get("content", "")
if content.strip():
locations.append((run_idx, field, msg_idx))
texts.append(content)
# 将所有文本以 25 条为一批发送给 Comprehend(API 限制)。
# 对于包含 1000 个操作(约 500 次运行)且每条有 2 条消息的情况:40 次 API 调用,而不是 1000 次。
redacted_texts = []
for i in range(0, len(texts), 25):
chunk = texts[i : i + 25]
response = comprehend.batch_detect_pii_entities(
TextList=chunk, LanguageCode="en"
)
for text, result in zip(chunk, response["ResultList"]):
redacted_texts.append(redact_entities(text, result.get("Entities", [])))
# 将编辑后的文本写回运行字典
for (run_idx, field, msg_idx), redacted in zip(locations, redacted_texts):
runs[run_idx][field]["messages"][msg_idx]["content"] = redacted
return runs
client = Client(
process_buffered_run_ops=comprehend_anonymize_batch,
run_ops_buffer_size=1000, # 约 500 次被追踪调用(每次 2 个操作:创建 + 更新)
run_ops_buffer_timeout_ms=3000, # 或 3 秒后,以先到者为准
)
@traceable(client=client)
def my_llm_call(messages: list) -> dict:
# ... 你的 LLM 调用 ...
pass
try:
my_llm_call([{"role": "user", "content": "My name is Jane Smith, call me at 555-867-5309"}])
finally:
client.flush() # 退出前始终刷新
process_buffered_run_ops 和 run_ops_buffer_size 必须始终一起设置 — 只提供其中一个而不提供另一个会引发 ValueError。

