

概念:成对评估
evaluate() 与两个现有实验来定义成对评估器并运行成对评估。最后,您将使用 LangSmith UI 来查看成对实验。
前提条件
您也可以使用
evaluate_comparative() 来比较两个以上的现有实验。evaluate() 比较参数
最简单的 evaluate / aevaluate 函数接受以下参数:
| 参数 | 描述 |
|---|---|
target | 要相互评估的两个现有实验的列表。可以是 UUID 或实验名称。 |
evaluators | 要附加到此评估的成对评估器列表。请参阅下文了解如何定义这些评估器。 |
| 参数 | 描述 |
|---|---|
randomize_order / randomizeOrder | 可选布尔值,指示是否应在每次评估中随机化输出的顺序。这是最小化提示中位置偏差的一种策略:通常,LLM 会根据顺序对其中一个回答产生偏差。这应主要通过提示工程来解决,但这是另一种可选的缓解措施。默认为 False。 |
experiment_prefix / experimentPrefix | 要附加到成对实验名称开头的前缀。默认为 None。 |
description | 成对实验的描述。默认为 None。 |
max_concurrency / maxConcurrency | 要运行的最大并发评估数。默认为 5。 |
client | 要使用的 LangSmith 客户端。默认为 None。 |
metadata | 要附加到成对实验的元数据。默认为 None。 |
load_nested / loadNested | 是否加载实验的所有子运行。当为 False 时,只有根跟踪会传递给您的评估器。默认为 False。 |
定义成对评估器
成对评估器只是具有预期签名的函数。评估器参数
自定义评估器函数必须具有特定的参数名称。它们可以接受以下任意子集的参数:inputs: dict:与数据集中单个示例对应的输入字典。outputs: list[dict]:每个实验在给定输入上产生的两个字典输出的列表。reference_outputs/referenceOutputs: dict:示例关联的参考输出字典(如果可用)。runs: list[Run]:两个实验在给定示例上生成的完整 Run 对象的两个项目列表。如果您需要访问中间步骤或每个运行的元数据,请使用此参数。example: Example:完整的数据集 Example,包括示例输入、输出(如果可用)和元数据(如果可用)。
inputs、outputs 和 reference_outputs / referenceOutputs。runs 和 example 仅在您需要应用程序实际输入和输出之外的一些额外跟踪或示例元数据时有用。
评估器输出
自定义评估器应返回以下类型之一: Python 和 JS/TS-
dict:包含以下键的字典:key,表示将记录的反馈键scores,是从运行 ID 到该运行分数的映射。comment,是一个字符串。最常用于模型推理。
list[int | float | bool]:一个包含两个分数的列表。假定列表的顺序与runs/outputs评估器参数相同。评估器函数名称用作反馈键。
pairwise_ 或 ranked_。
运行成对评估
以下示例使用一个提示,要求 LLM 在两个 AI 助手回答之间决定哪个更好。它使用结构化输出来解析 AI 的响应:0、1 或 2。在下面的 Python 示例中,我们从 LangChain Hub 拉取这个结构化提示,并与 LangChain 聊天模型包装器一起使用。LangChain 的使用完全是可选的。 为了说明这一点,TypeScript 示例直接使用 OpenAI SDK。
- Python:需要
langsmith>=0.2.0 - TypeScript:需要
langsmith>=0.2.9
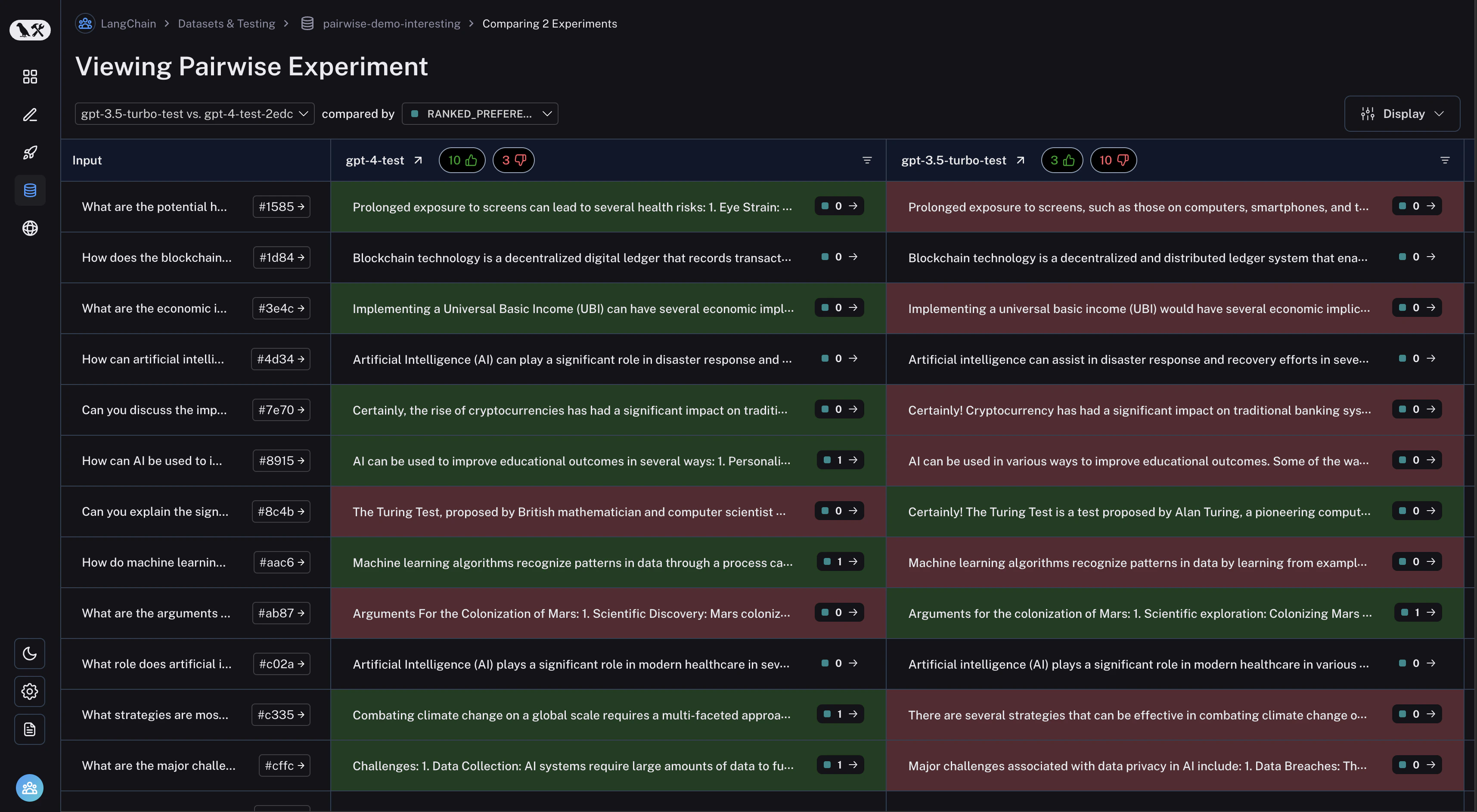
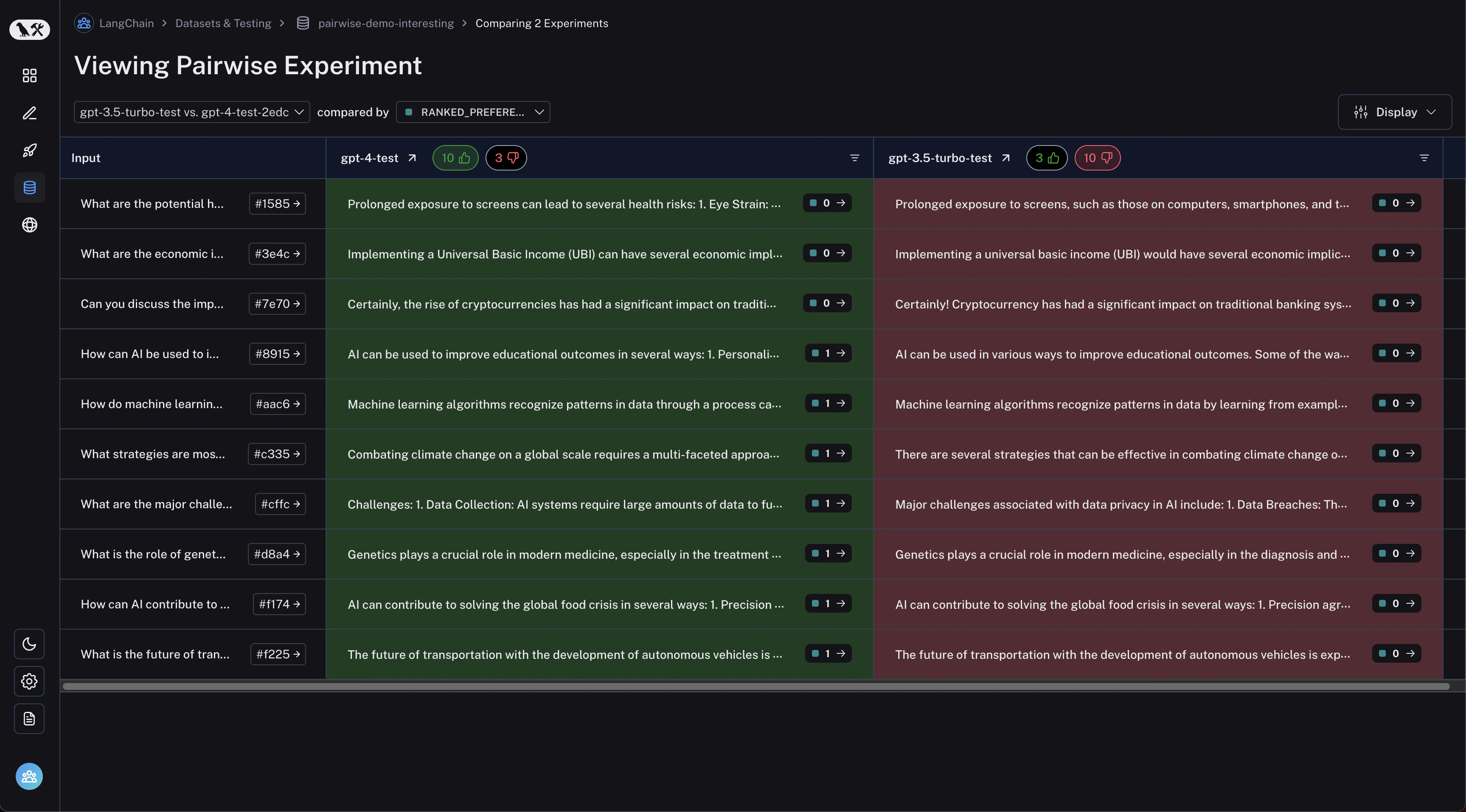
查看成对实验
从数据集页面导航到“成对实验”标签页: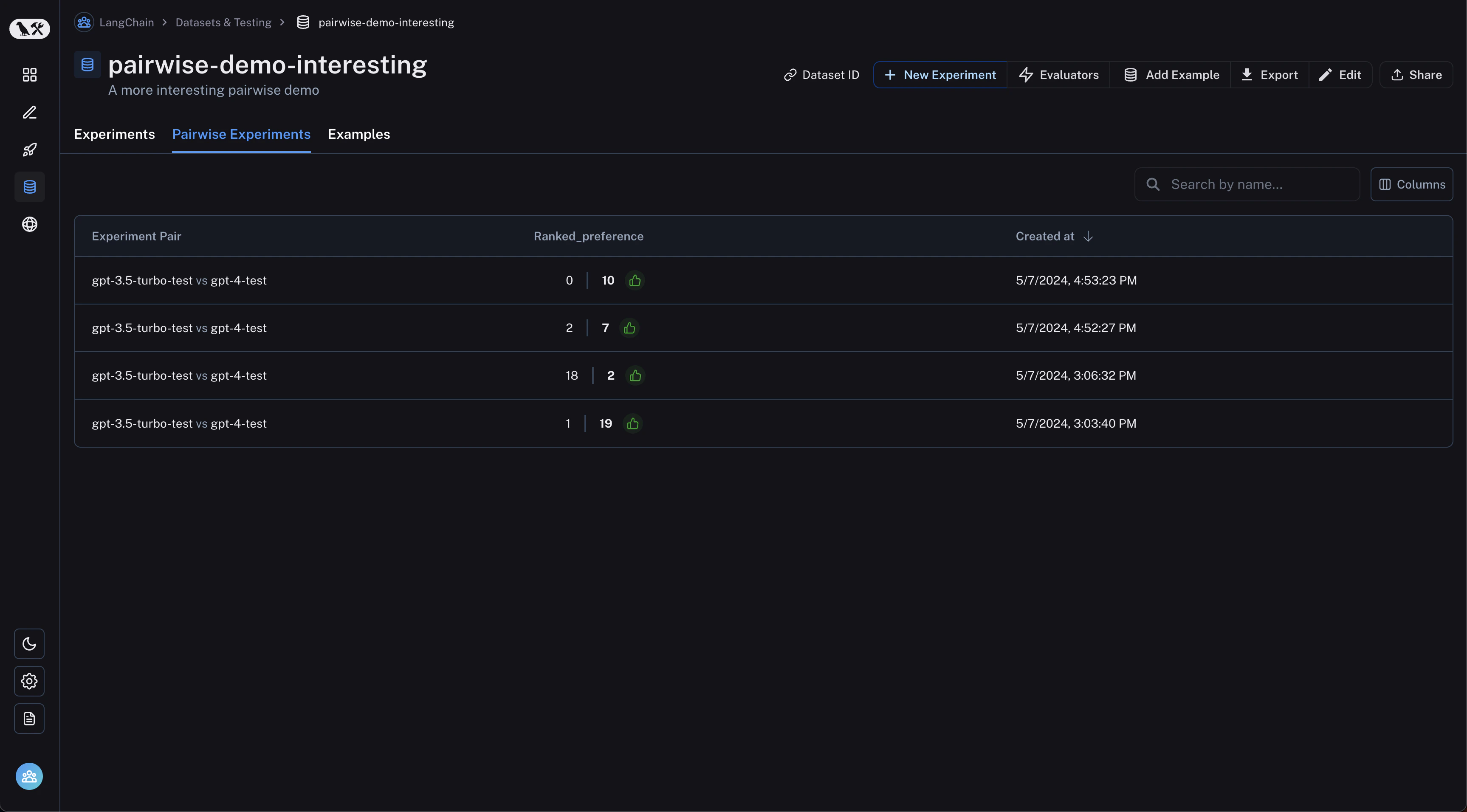
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.