

- 评估类型:_何时以及为何_进行评估。用于部署前测试的离线评估类型(基准测试、单元测试、回归测试),以及用于生产环境的在线评估类型(监控、异常检测)。
- 评估器实现:_如何_进行评估。可用的评估器方法(LLM 即法官、代码、复合、摘要、成对比较)以及在哪里配置它们(UI 或 SDK,离线或在线)。
离线评估类型
离线评估在部署前,在精心策划的数据集上测试应用程序。通过在具有参考输出的示例上运行评估,团队可以比较版本、验证功能,并在将变更暴露给用户之前建立信心。 使用 LangSmith SDK(Python 或 TypeScript)在客户端运行离线评估,或通过 Playground 在服务端运行,或通过将评估器绑定到数据集来运行。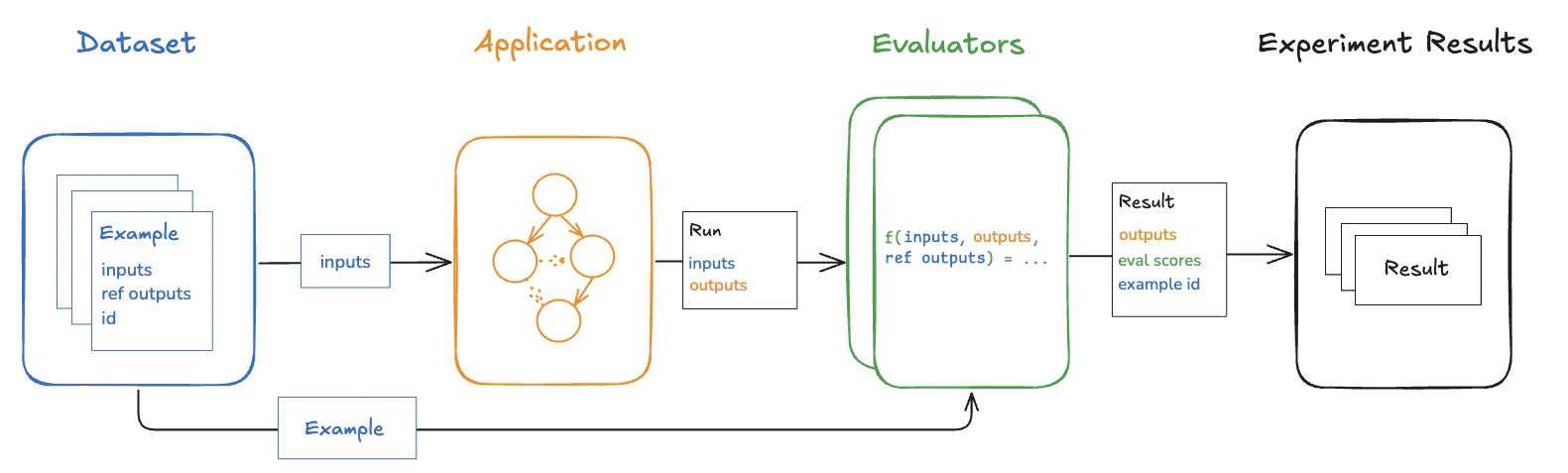
基准测试
基准测试 在精心策划的数据集上比较多个应用程序版本,以确定最佳表现者。此过程涉及创建具有代表性输入的数据集、定义性能指标并测试每个版本。 基准测试需要包含黄金标准参考输出的数据集和精心设计的比较指标。例如:- RAG 问答机器人:包含问题和参考答案的数据集,使用 LLM 即法官评估器检查实际答案与参考答案之间的语义等价性。
- ReACT 智能体:包含用户请求和参考工具调用的数据集,使用启发式评估器验证是否进行了所有预期的工具调用。
单元测试
单元测试 验证单个系统组件的正确性。在 LLM 上下文中,单元测试通常是基于规则的断言,针对输入或输出(例如,验证 LLM 生成的代码能否编译、JSON 能否成功加载)以验证基本功能。 单元测试通常期望一致的通过结果,因此适合 CI 流水线。在 CI 中运行时,请配置缓存以最小化 LLM API 调用及相关成本。 更多详细信息,请参阅 Pytest 和 Vitest/Jest 页面。回归测试
回归测试 衡量不同应用程序版本随时间推移的性能一致性。它们确保新版本不会在当前版本能正确处理的情况下降低性能,并且理想情况下能展示相对于基线的改进。这些测试通常在预计会影响用户体验的更新(例如,模型或架构变更)时运行。 LangSmith 的比较视图突出显示了相对于基线的回归(红色)和改进(绿色),便于快速识别变更。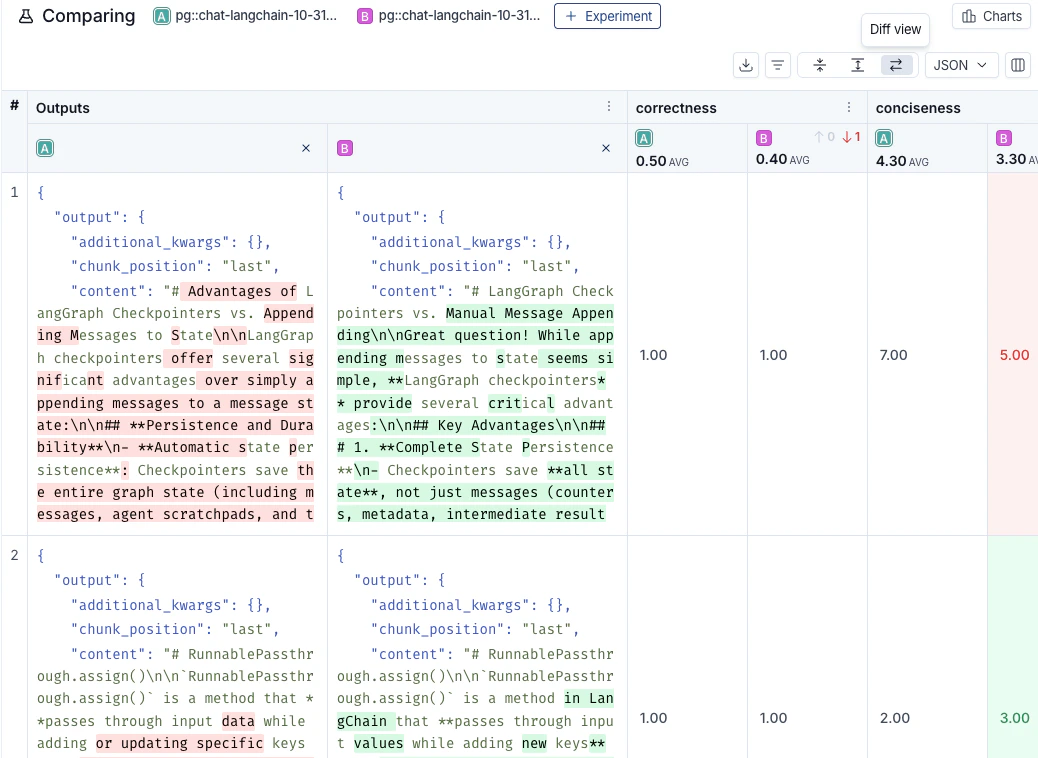
回测
回测 使用历史生产数据评估新的应用程序版本。将生产日志转换为数据集,然后让较新的版本处理这些示例,以评估其在过去、真实的用户输入上的性能。 这种方法通常用于评估新模型发布。例如,当新模型可用时,在最近的生产运行上测试它,并将结果与实际生产结果进行比较。成对比较评估
成对比较评估 通过确定相对质量来比较两个版本的输出,而不是分配绝对分数。对于某些任务,确定“版本 A 优于版本 B” 比独立评分每个版本更容易。 这种方法对于主观任务的 LLM 即法官评估特别有用。例如,在摘要任务中,确定“哪个摘要更清晰、更简洁?”通常比分配数字清晰度分数更简单。 了解如何运行成对比较评估。在线评估类型
在线评估近乎实时地评估生产环境应用程序的输出。在没有参考输出的情况下,这些评估侧重于检测问题、监控质量趋势以及识别可能影响未来离线测试的边缘情况。 在线评估器通常在服务端运行。LangSmith 提供内置的 LLM 即法官评估器 用于配置,并支持在 LangSmith 内运行的自定义代码评估器。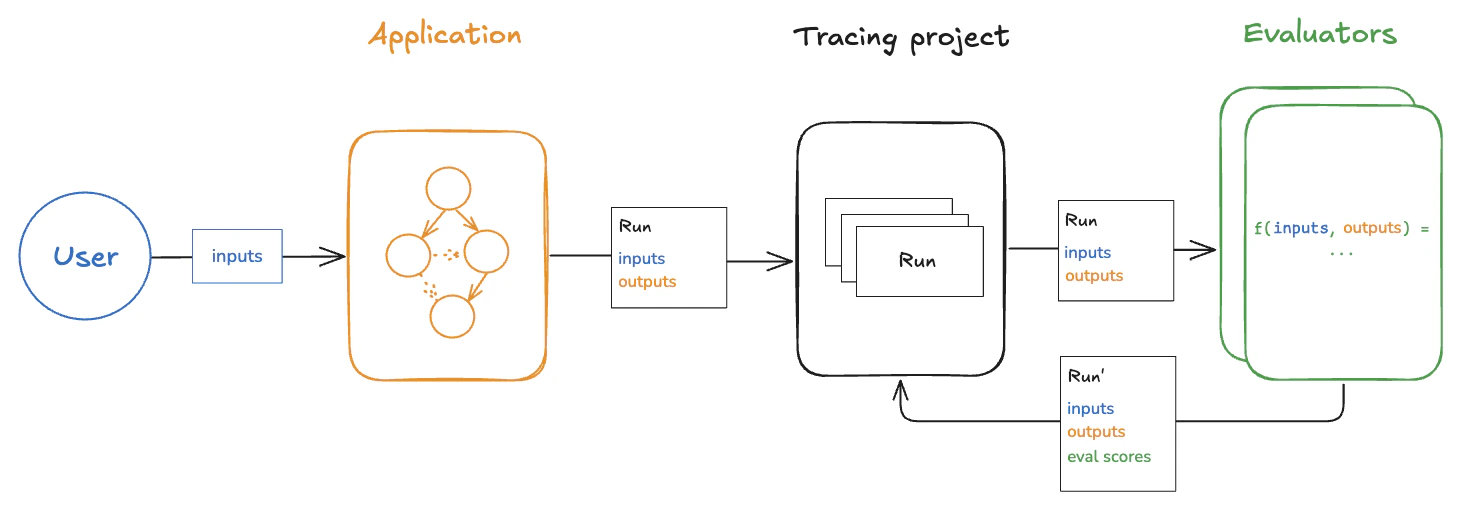
实时监控
在用户与系统交互时持续监控应用程序质量。在线评估自动在生产流量上运行,为每次交互提供即时反馈。这使得能够在质量问题、异常模式或意外行为影响大量用户之前检测到它们。异常检测
识别偏离预期模式的异常值和边缘情况。在线评估器可以标记具有异常特征的运行——极长或极短的响应、意外的错误率或未能通过安全检查的输出——以供人工审查,并可能添加到离线数据集中。生产反馈循环
利用生产环境的洞察来改进离线评估。在线评估会暴露真实世界的问题和使用模式,这些可能在精心策划的数据集中不会出现。失败的生产运行成为数据集示例的候选,创建一个迭代循环,使生产经验不断优化测试覆盖范围。实现评估器
上述评估类型描述了 何时 进行评估。LangSmith 提供了几种方法来实现适用于这些评估类型的评估器,即 如何 进行评估。LLM 即法官
使用 LLM 根据提示中定义的标准对输出进行评分。这种方法适用于难以用确定性规则捕捉的主观质量,如语气、清晰度或语义正确性。 常见用例包括根据参考输出评估事实准确性(离线)或检查生产响应中的毒性(在线)。例如,对 RAG 系统进行基准测试时,可能会使用 LLM 即法官评估器来检查生成答案与参考答案之间的语义等价性。 为以下场景配置 LLM 即法官评估器:代码评估器
编写确定性的、基于规则的函数来检查特定条件。这些评估器执行自定义逻辑以验证结构、检查模式或应用业务规则。 代码评估器对于单元测试特别有用——验证生成的代码能否编译、JSON 能否正确解析或必需字段是否存在。在回归测试中,它们可以跟踪结构化输出的一致性。对于在线监控,它们可以实时捕获格式违规。 为以下场景定义代码评估器:复合评估器
使用加权平均或求和将多个评估器分数组合成单个指标。这创建了反映多个评估标准的同时的聚合质量分数。 对于基准测试,复合分数有助于在多个维度上比较版本(例如,70% 准确性 + 20% 清晰度 + 10% 简洁性)。在在线监控中,它们为仪表板和警报提供单一指标。例如,将聊天机器人的整体质量跟踪为有用性、正确性和语气分数的加权组合。 为以下场景设置复合评估器:摘要评估器
计算整个实验的指标,而不是单个示例的指标。这些评估器接收数据集的所有输出,并计算聚合统计数据,如精确率、召回率、F1 分数或分布分析。 摘要评估器对于基准测试至关重要,当您需要数据集级别的指标时——比较版本之间的整体性能,而不是逐个示例的分数。它们专门用于离线评估,因为它们需要处理完整的数据集。 为以下场景实现摘要评估器:- 用于离线评估的自定义聚合函数:使用 SDK
成对比较评估器
比较两个版本的输出以确定相对质量。这种方法,在前面成对比较评估部分已介绍,在绝对评分困难但确定“哪个更好”相对简单时很有帮助。 为以下场景运行成对比较评估:- 比较现有实验:使用 SDK
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.