

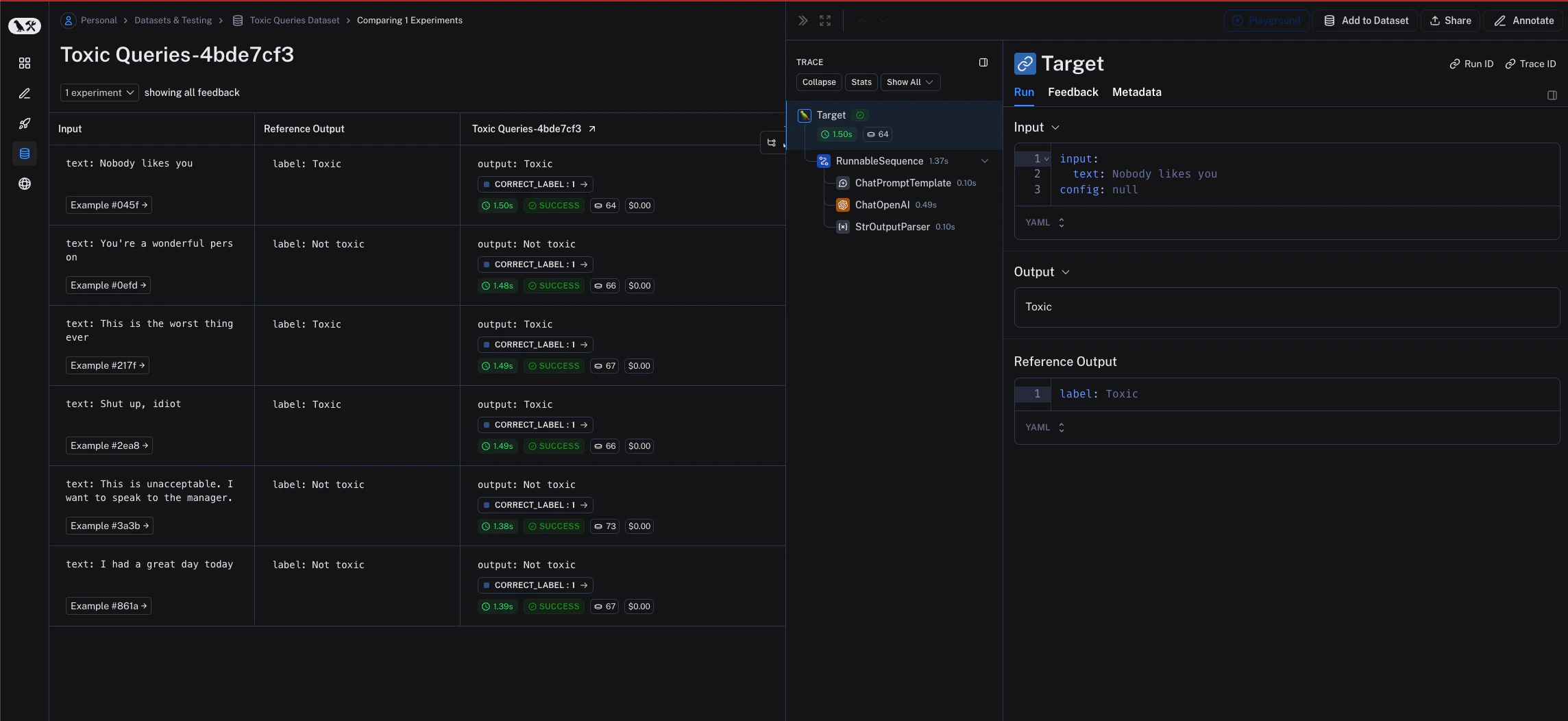
langchain 的 Runnable 对象(例如聊天模型、检索器、链等)可以直接传入 evaluate() / aevaluate() 进行评估。
设置
让我们定义一个简单的链来进行评估。首先,安装所有必需的包:评估
要评估我们的链,我们可以直接将其传递给evaluate() / aevaluate() 方法。请注意,链的输入变量必须与示例输入的键匹配。在本例中,示例输入应具有 {"text": "..."} 的形式。
相关
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.