

- 相比于基于预先存在的完整轨迹数据集进行评估,更容易上手
- 从初始查询到成功或失败解决的端到端覆盖
- 能够检测应用在多次迭代中的重复行为或上下文丢失
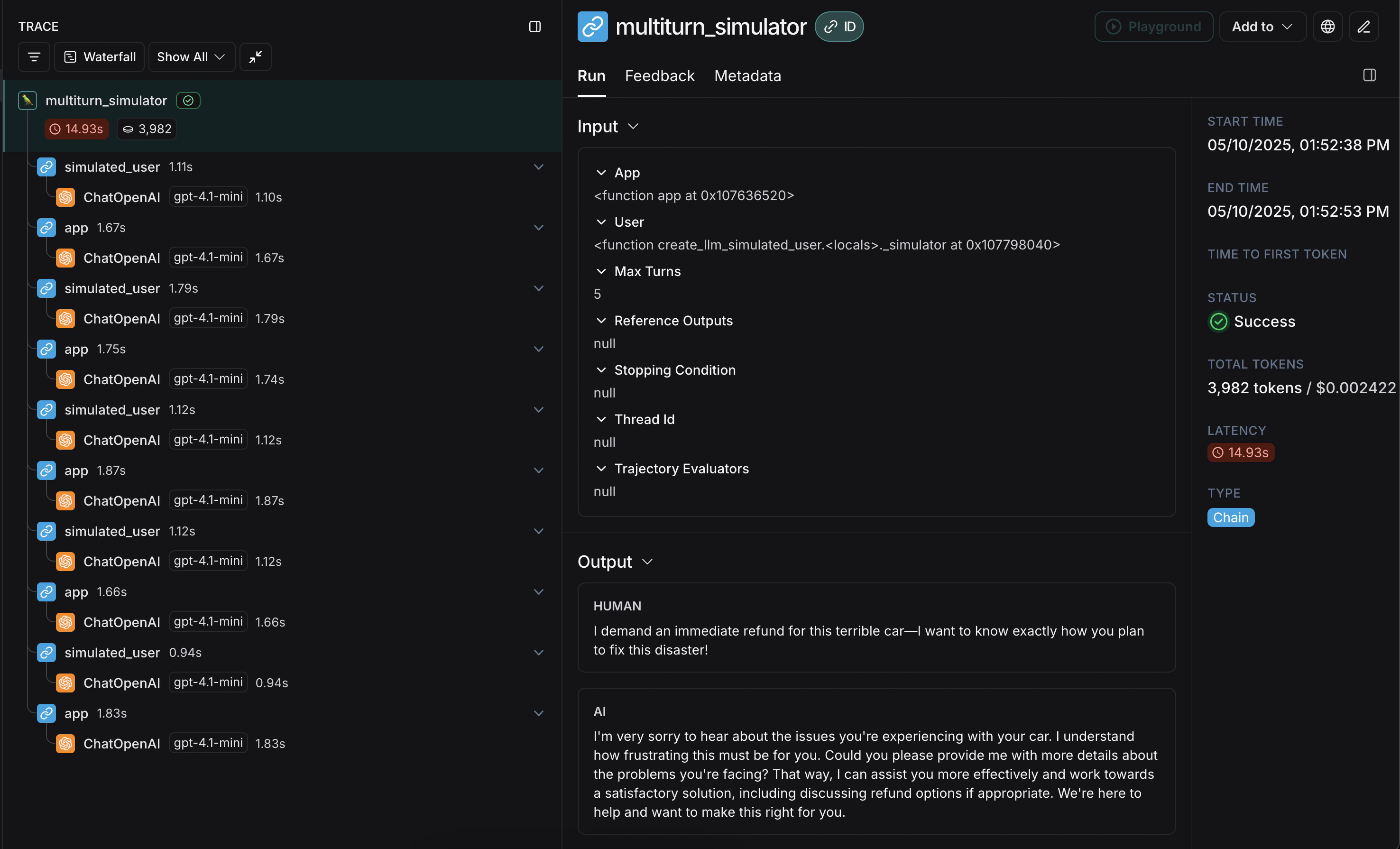
openevals 包来模拟多轮交互并进行评估。该包包含预构建的评估器和其他用于评估 AI 应用的便捷资源。本指南也将使用 OpenAI 模型,不过您也可以使用其他供应商的模型。
设置
首先,确保已安装所需的依赖项:如果您使用
yarn 作为包管理器,还需要手动安装 @langchain/core 作为 openevals 的对等依赖项。这对于 LangSmith 评估来说通常不是必需的。运行模拟
开始前需要两个主要组件:app:您的应用程序,或包装它的函数。必须接受单个聊天消息(包含 “role” 和 “content” 键的字典)作为输入参数,并接受thread_id作为关键字参数。应接受其他关键字参数,因为未来版本可能会添加更多参数。返回一个至少包含 role 和 content 键的聊天消息作为输出。user:模拟用户。在本指南中,我们将使用一个名为create_llm_simulated_user的预构建导入函数,该函数使用 LLM 生成用户响应,不过您也可以创建自己的模拟用户。
openevals 中的模拟器在每一轮中将来自 user 的单个聊天消息传递给您的 app。因此,如果需要,您应该根据 thread_id 在内部有状态地跟踪当前历史记录。
以下是一个模拟多轮客户支持交互的示例。本指南使用一个简单的聊天应用,该应用包装了对 OpenAI 聊天补全 API 的单个调用,但这里您可以调用您的应用程序或代理。在此示例中,我们的模拟用户扮演一个特别具有攻击性的客户角色:
user 生成初始查询,然后在 app 和 user 之间来回传递响应聊天消息,直到达到 max_turns(您也可以传递一个 stopping_condition,该函数接收当前轨迹并返回 True 或 False - 详见 OpenEvals README)。返回值是构成对话轨迹的最终聊天消息列表。
有多种方式可以配置模拟用户,例如让它在模拟的前几轮返回固定响应,以及整体模拟的配置。完整详情请查看 OpenEvals README。
app 和 user 的交替响应:
在 LangSmith 实验中运行
您可以将多轮模拟的结果用作 LangSmith 实验的一部分,以跟踪性能并随时间推移观察进展。对于这些部分,熟悉至少一种 LangSmith 的pytest(仅限 Python)、Vitest/Jest(仅限 JS)或 evaluate 运行器会很有帮助。
使用 pytest 或 Vitest/Jest
请参阅以下指南,了解如何使用 LangSmith 与测试框架的集成来设置评估:
trajectory_evaluators 参数传入。这些评估器将在模拟结束时运行,将最终的聊天消息列表作为 outputs 关键字参数接收。因此,您传入的 trajectory_evaluator 必须接受此关键字参数。
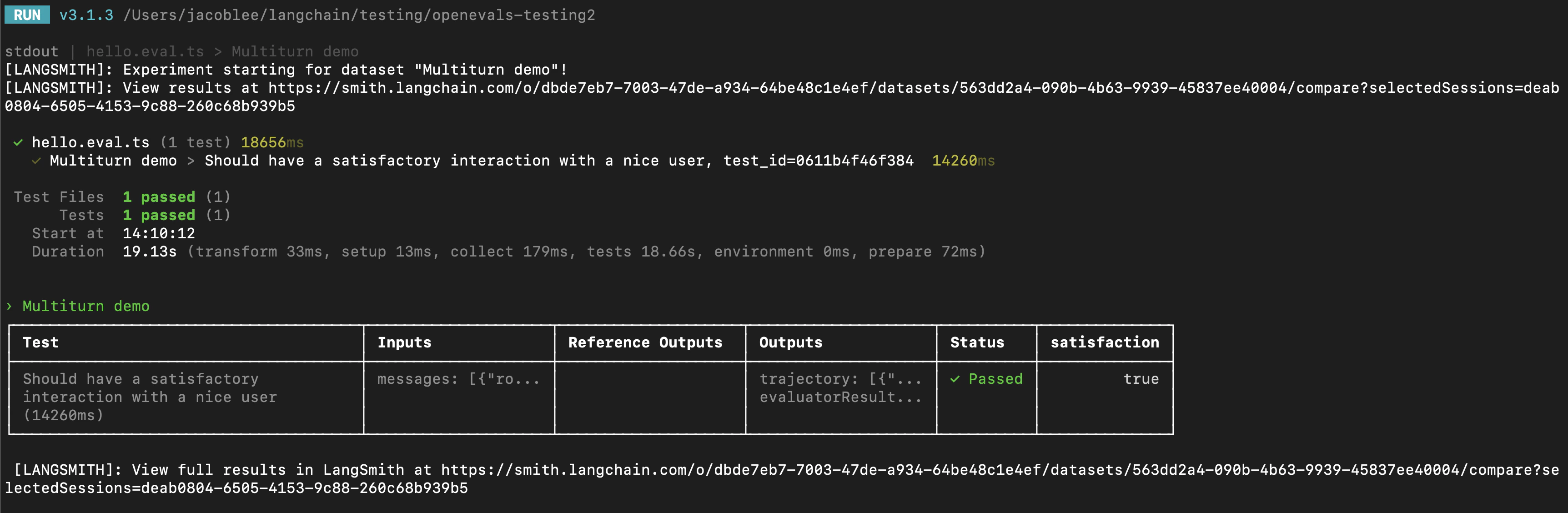
trajectory_evaluators 返回的反馈,并将其添加到实验中。还要注意,测试用例使用模拟用户的 fixed_responses 参数以特定输入开始对话,您可以记录该输入并将其作为存储数据集的一部分。
您可能还会发现,将模拟用户的系统提示作为记录数据集的一部分会很方便。
使用 evaluate
您也可以使用 evaluate 运行器来评估模拟的多轮交互。这与 pytest/Vitest/Jest 示例在以下方面略有不同:
- 模拟应该是您的
target函数的一部分,并且您的 target 函数应返回最终轨迹。- 这将使轨迹成为 LangSmith 传递给您的评估器的
outputs。
- 这将使轨迹成为 LangSmith 传递给您的评估器的
- 不应使用
trajectory_evaluators参数,而应将您的评估器作为参数传递给evaluate()方法。 - 您需要一个包含输入和(可选)参考轨迹的现有数据集。
修改模拟用户角色
上述示例对所有输入示例使用相同的模拟用户角色,该角色由传递给create_llm_simulated_user 的 system 参数定义。如果您希望为数据集中的特定项目使用不同的角色,可以更新数据集示例以包含一个带有所需 system 提示的额外字段,然后在创建模拟用户时像这样传入该字段:
后续步骤
您刚刚了解了一些模拟多轮交互并在 LangSmith 评估中运行它们的技术。 以下是一些您可能想要探索的后续主题: 您也可以探索 OpenEvals 自述文件以获取更多关于预构建评估器的信息。Connect these docs to Claude, VSCode, and more via MCP for real-time answers.