

- 创建初始的黄金数据集以衡量性能
- 定义用于衡量性能的指标
- 在几个不同的提示或模型上运行评估
- 手动比较结果
- 随时间跟踪结果
- 设置在 CI/CD 中运行的自动化测试
设置
首先安装本教程所需的依赖项。我们这里使用 OpenAI,但 LangSmith 可以与任何模型一起使用:创建数据集
准备测试和评估应用程序的第一步是定义要评估的数据点。这里有几个方面需要考虑:- 每个数据点的模式应该是什么?
- 我应该收集多少个数据点?
- 我应该如何收集这些数据点?
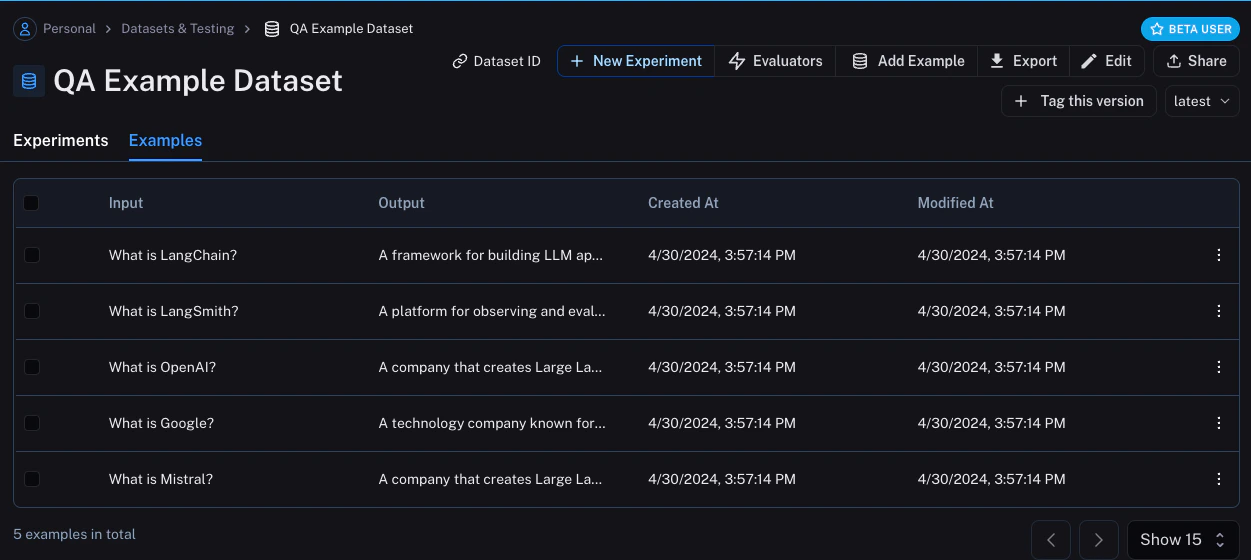
数据集与测试 页面中查找 问答示例数据集,点击进入后应该会看到五个新示例。
定义指标
创建数据集后,我们现在可以定义一些指标来评估我们的响应。由于我们有预期的答案,我们可以将其作为评估的一部分进行比较。然而,我们不期望我们的应用程序输出那些完全相同的答案,而是期望输出类似的内容。这使得我们的评估稍微复杂一些。 除了评估正确性,我们还希望确保答案简短精炼。这会容易一些——我们可以定义一个简单的 Python 函数来测量响应的长度。 让我们继续定义这两个指标。 对于第一个指标,我们将使用 LLM 来判断输出是否正确(相对于预期输出)。这种 LLM 作为评判者 对于过于复杂而无法用简单函数测量的情况相对常见。我们可以在这里定义自己的提示词和用于评估的 LLM:运行评估
太好了!现在我们如何运行评估?现在我们有了数据集和评估器,我们需要的只是我们的应用程序!我们将构建一个简单的应用程序,它只有一个包含如何响应的指令的系统消息,然后将其传递给 LLM。我们将直接使用 OpenAI SDK 构建这个应用程序: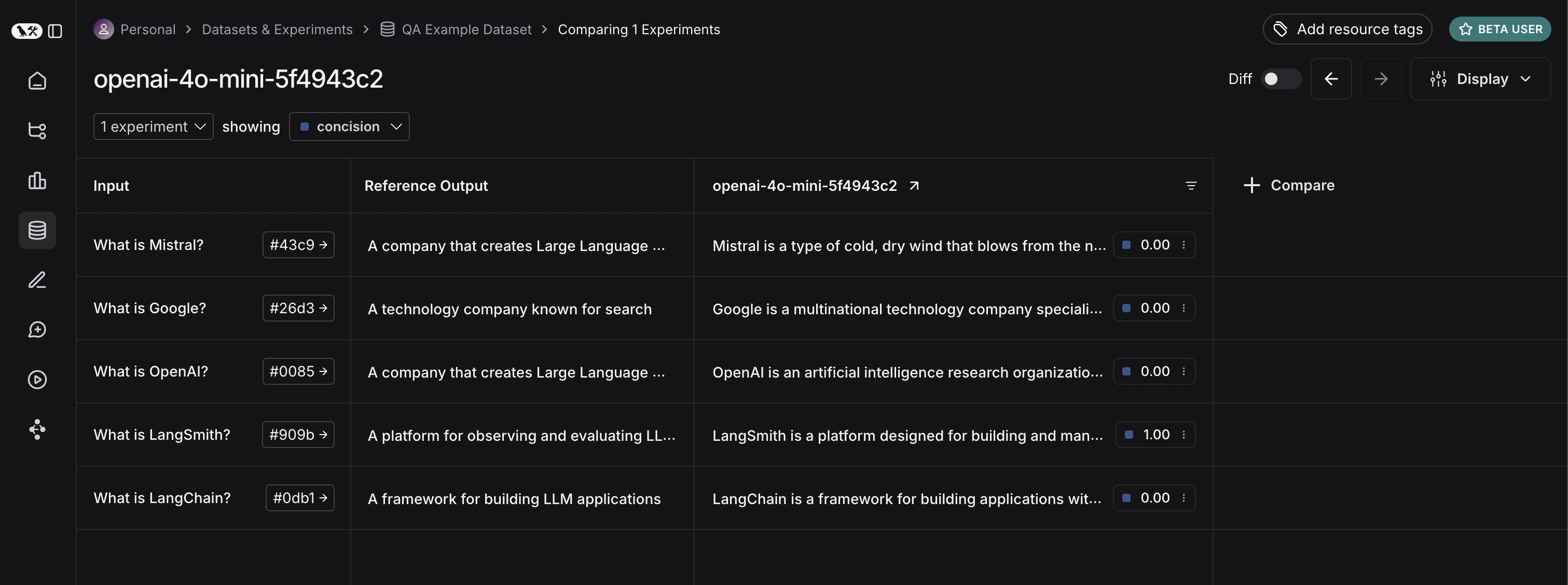
实验 选项卡,现在可以看到我们一次运行的摘要!
gpt-4-turbo
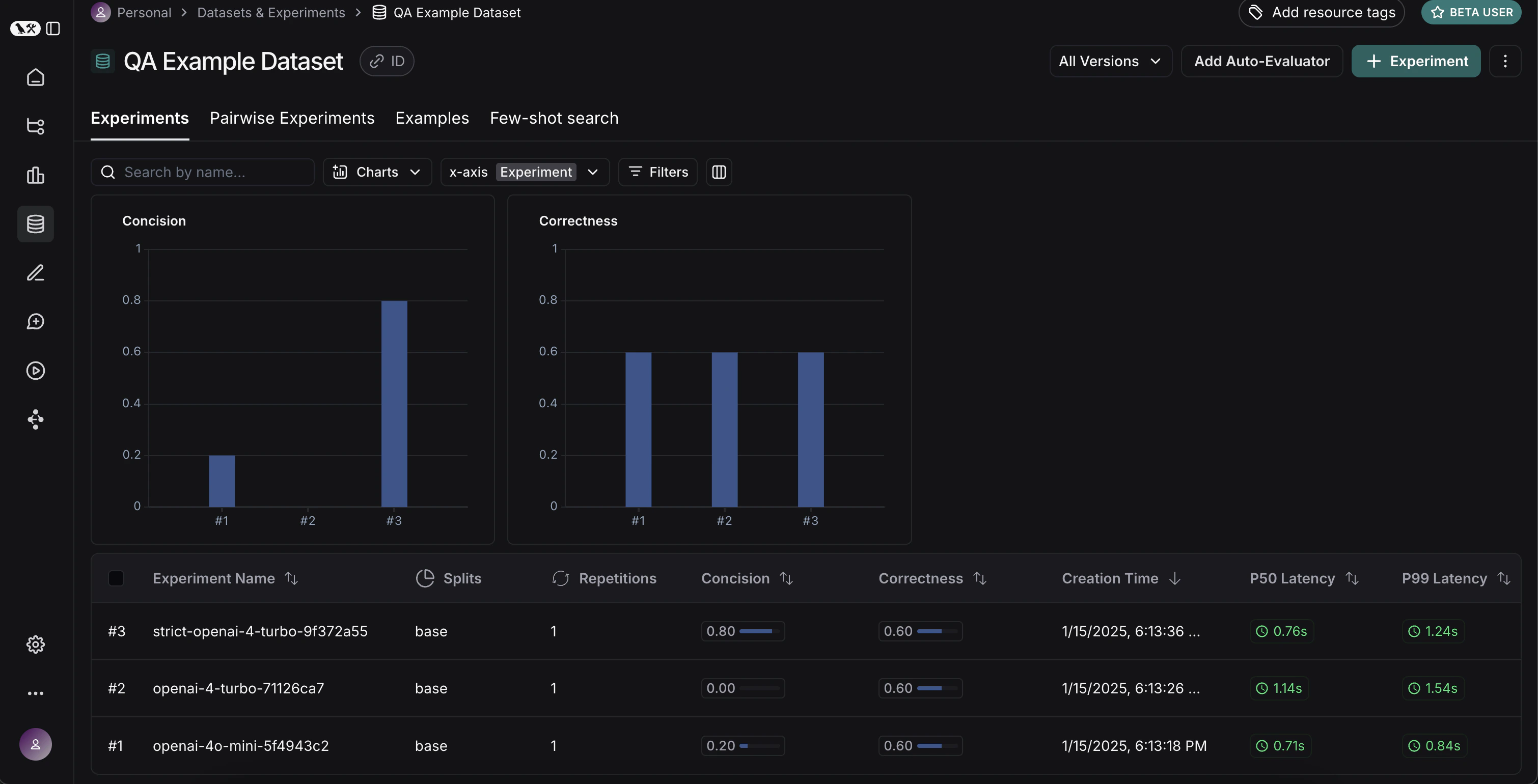
实验 选项卡,应该会看到所有三次运行都显示出来了!
比较结果
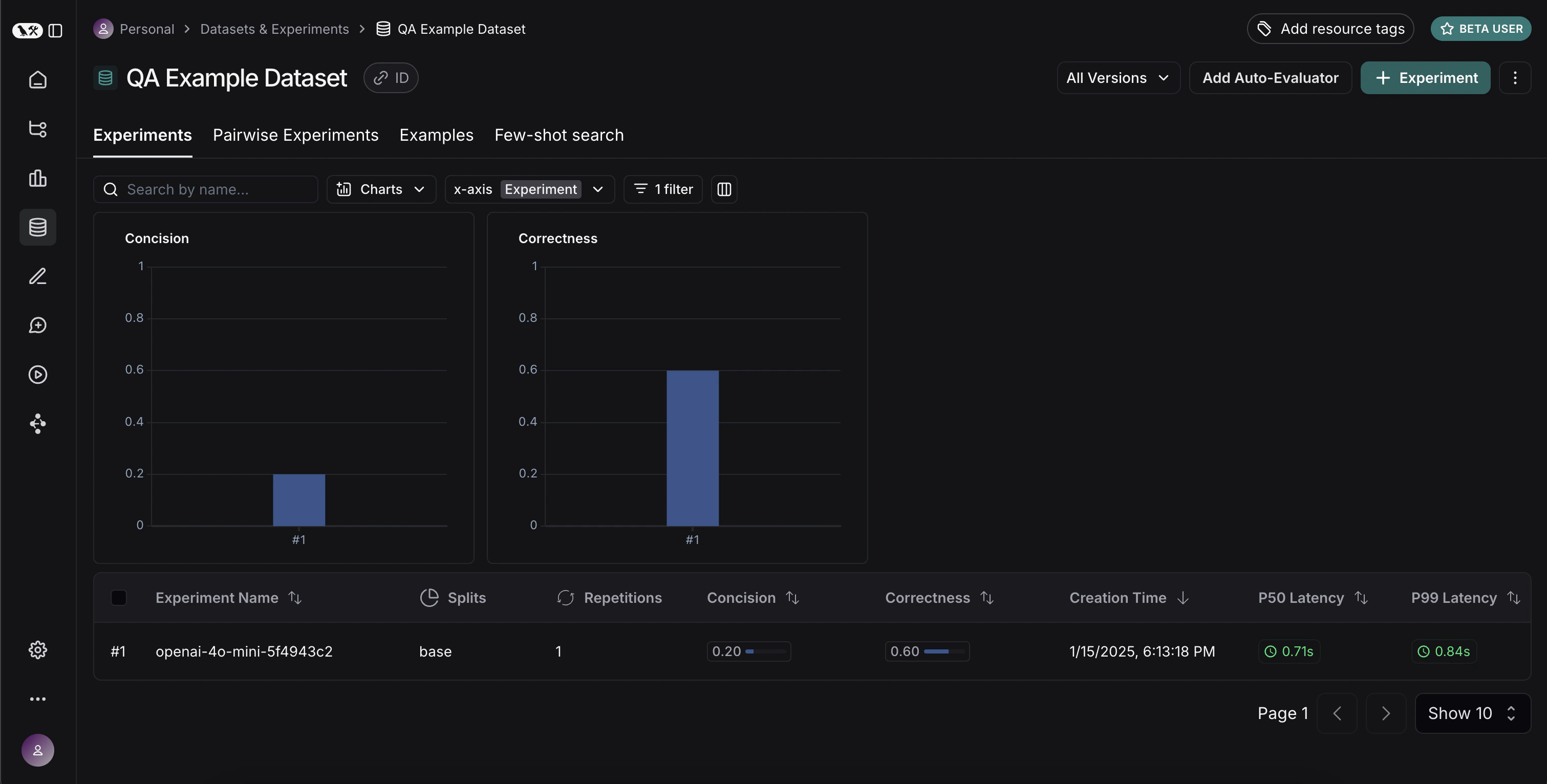
太棒了,我们已经评估了三种不同的运行。但是我们如何比较结果呢?第一种方法是查看实验 选项卡中的运行。如果我们这样做,可以看到每次运行指标的高级视图:
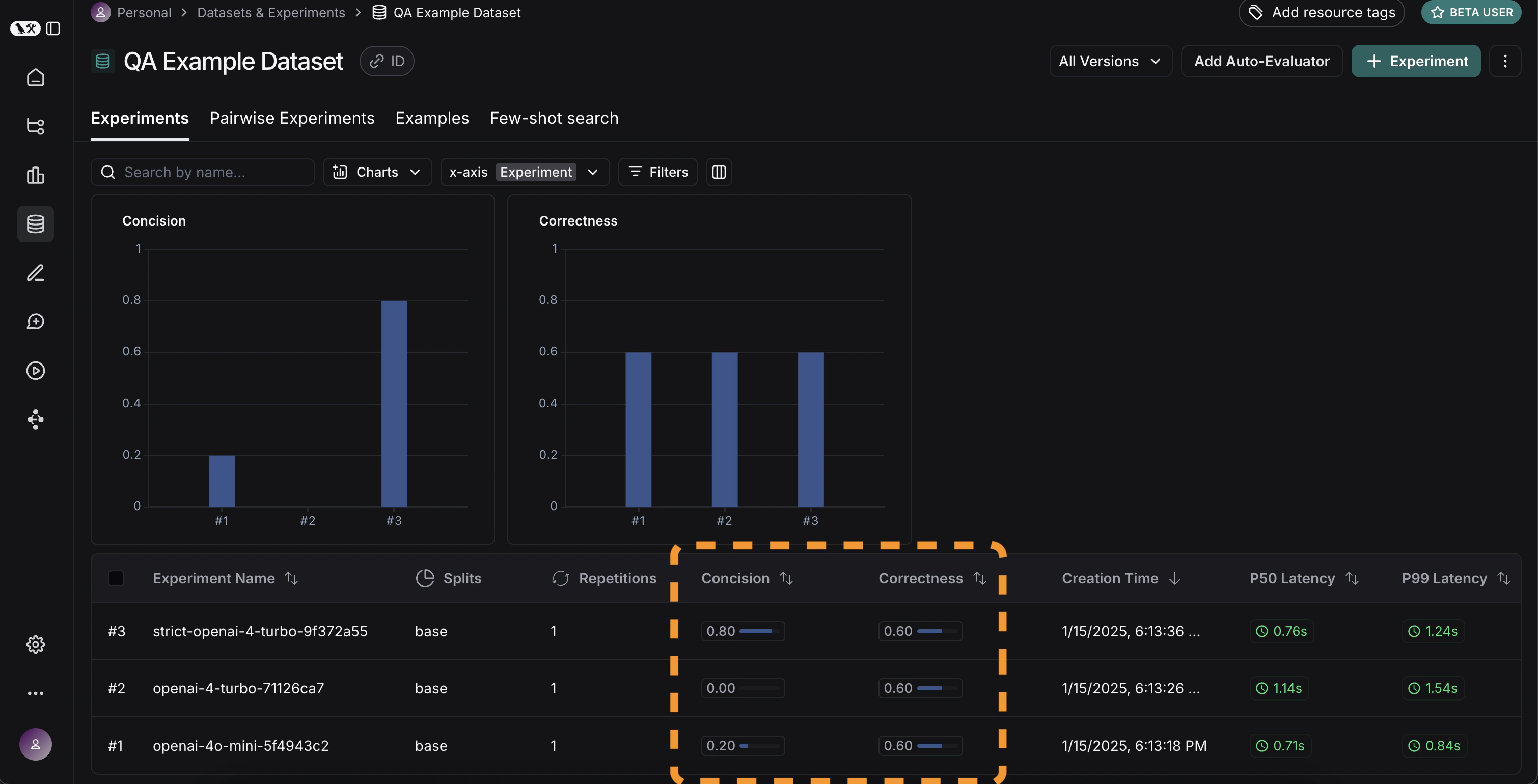
显示 控件选择要查看的列和指标。您还可以通过点击顶部的图标自动筛选,只显示有改进/回归的运行。
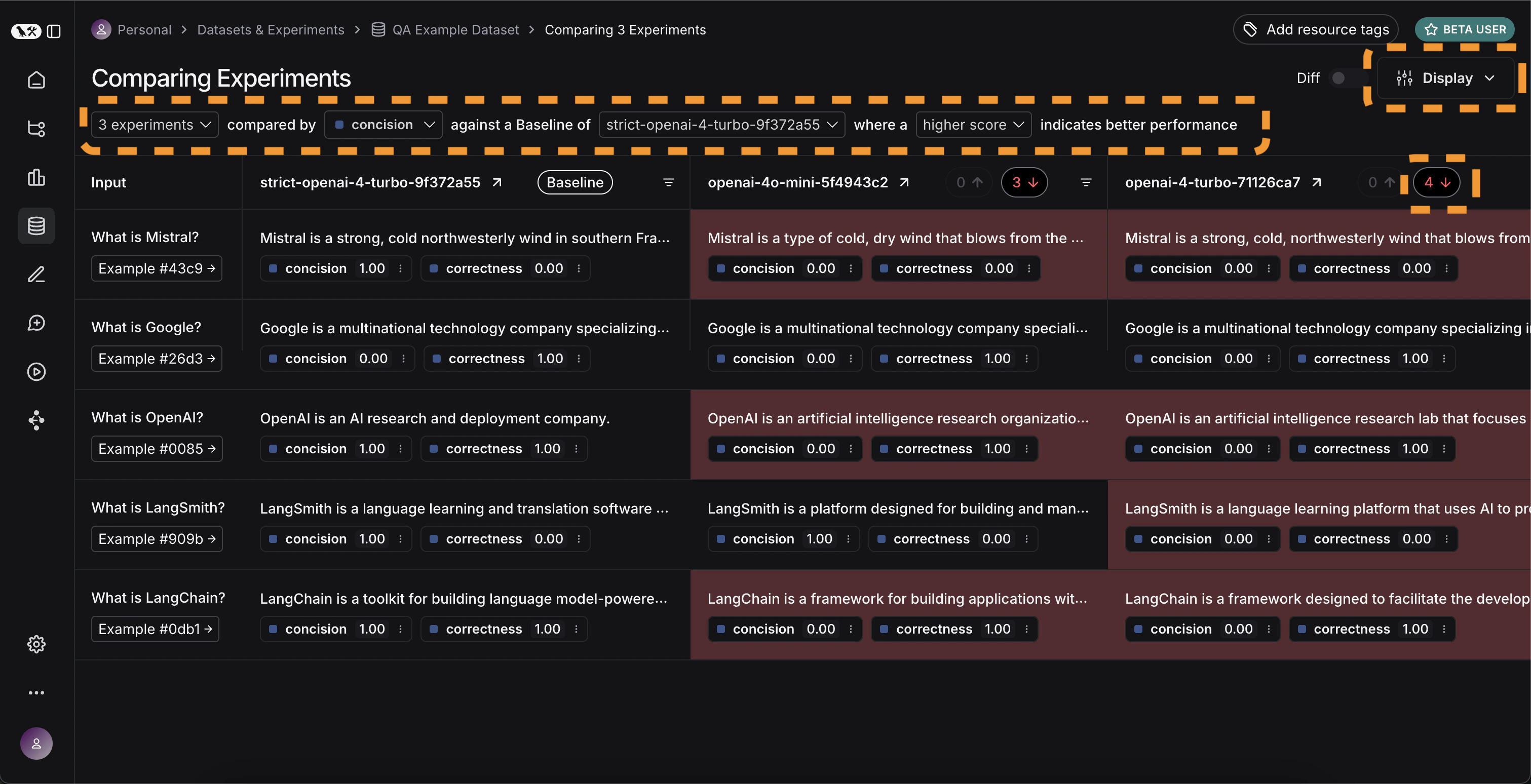
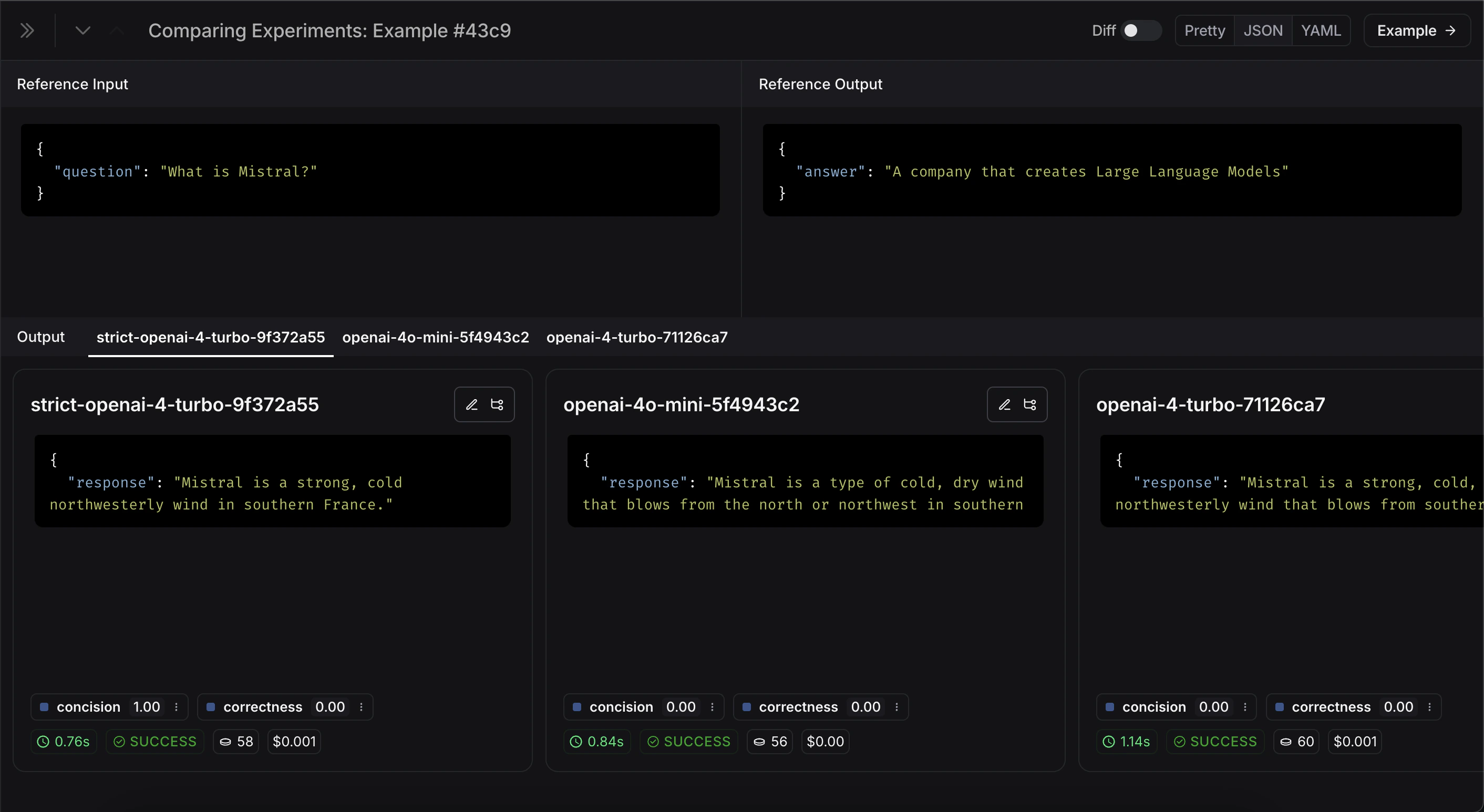
展开 按钮,打开一个侧边面板,显示更详细的信息:
设置在 CI/CD 中运行的自动化测试
既然我们已经以一次性方式运行了此测试,我们可以将其设置为以自动化方式运行。我们可以很容易地通过将其包含在 CI/CD 中运行的 pytest 文件中来实现。作为此过程的一部分,我们可以只记录结果,或者设置一些标准来确定它是否通过。例如,如果我想确保我们生成的响应中至少有 80% 通过长度 检查,我们可以设置如下测试:
随时间跟踪结果
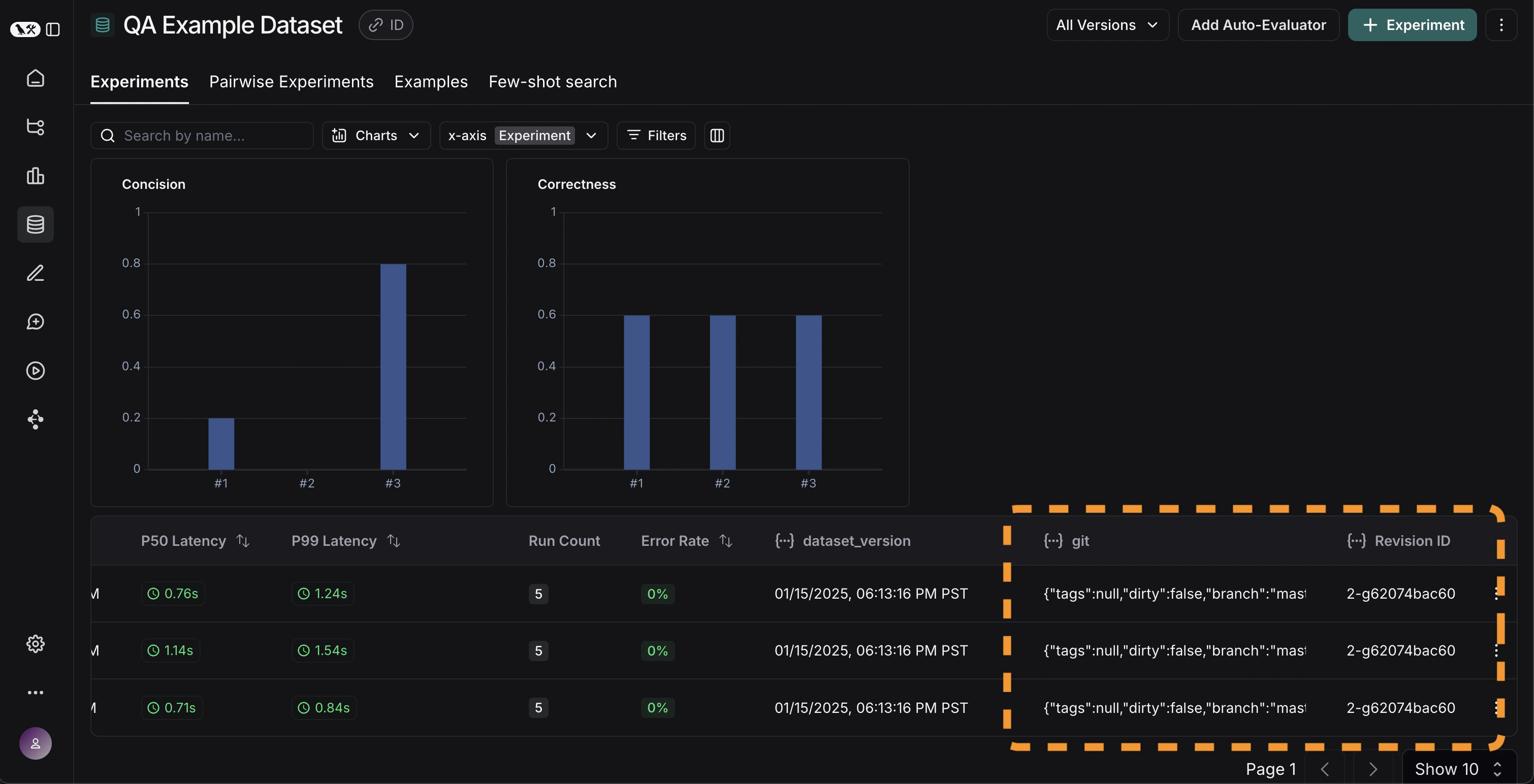
既然我们已经以自动化方式运行了这些实验,我们希望随时间跟踪这些结果。我们可以从数据集页面的整体实验 选项卡中做到这一点。默认情况下,我们显示随时间变化的评估指标(以红色高亮显示)。我们还自动跟踪 git 指标,以便轻松地将其与您的代码分支关联起来(以黄色高亮显示)。
结论
本教程到此结束! 我们已经介绍了如何创建初始测试集、定义一些评估指标、运行实验、手动比较它们、设置 CI/CD 以及随时间跟踪结果。这可以帮助您自信地进行迭代。 这只是一个开始。如前所述,评估是一个持续的过程。例如——您想要评估的数据点可能会随时间继续变化。您可能希望探索许多类型的评估器。有关此信息,请查看操作指南。 此外,除了这种“离线”方式外,还有其他评估数据的方法(例如,您可以评估生产数据)。有关在线评估的更多信息,请查看设置 LLM 作为评判者的在线评估器。参考代码
点击查看整合后的代码片段
点击查看整合后的代码片段
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.