部署应用程序只是持续改进过程的开始。部署到生产环境后,您需要通过优化提示、语言模型、工具和架构来完善系统。回测涉及使用历史数据评估应用程序的新版本,并将新输出与原始输出进行比较。与使用预生产数据集进行评估相比,回测能更清晰地表明新版本应用程序是否比当前部署版本有所改进。
以下是回测的基本步骤:
- 从您的生产追踪项目中选择要测试的样本运行。
- 将运行输入转换为数据集,并将运行输出记录为该数据集的初始实验。
- 在新数据集上执行新系统,并比较实验结果。
此过程将为您提供一个具有代表性输入的新数据集,您可以对其进行版本控制并用于模型回测。
通常,您可能没有明确的“真实答案”可用。在这种情况下,您可以手动标注输出或使用不依赖参考数据的评估器。如果您的应用程序允许捕获真实标签(例如允许用户提供反馈),我们强烈建议这样做。
配置环境
安装并设置环境变量。本指南要求 langsmith>=0.2.4。
为方便起见,本教程将使用 LangChain OSS 框架,但展示的 LangSmith 功能是框架无关的。
pip install -U langsmith langchain langchain-anthropic langchainhub emoji
uv add langsmith langchain langchain-anthropic langchainhub emoji
import getpass
import os
# 将项目名称设置为您要测试的项目
project_name = "Tweet Writing Task"
os.environ["LANGSMITH_PROJECT"] = project_name
os.environ["LANGSMITH_TRACING"] = "true"
if not os.environ.get("LANGSMITH_API_KEY"):
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("YOUR API KEY")
# 可选。您可以将 OpenAI 替换为任何其他支持工具调用的聊天模型。
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
# 可选。如果愿意,您可以将 Tavily 替换为免费的 DuckDuckGo 搜索工具。
# 获取 Tavily API 密钥:https://tavily.com
os.environ["TAVILY_API_KEY"] = "YOUR TAVILY API KEY"
定义应用程序
对于此示例,让我们创建一个简单的推文撰写应用程序,该应用程序可以访问一些互联网搜索工具:
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langchain_community.tools import DuckDuckGoSearchRun, TavilySearchResults
from langchain_core.rate_limiters import InMemoryRateLimiter
# 我们将使用 GPT-3.5 Turbo 作为基线,并与 GPT-4o 进行比较
gpt_3_5_turbo = init_chat_model(
"gpt-3.5-turbo",
temperature=1,
configurable_fields=("model", "model_provider"),
)
# 指令作为系统消息传递给代理
instructions = """您是一个推文撰写助手。给定一个主题,进行一些研究并撰写一条相关且引人入胜的推文。
- 每条推文中至少使用 3 个表情符号
- 推文长度不应超过 280 个字符
- 始终使用搜索工具收集有关推文主题的最新信息
- 仅根据搜索内容撰写推文。不要依赖您的内部知识
- 在相关时,链接到您的来源
- 使您的推文尽可能吸引人"""
# 定义我们的代理可以使用的工具
# 如果您有更高级的 Tavily API 计划,可以增加此值
rate_limiter = InMemoryRateLimiter(requests_per_second=0.08)
# 如果您没有 Tavily API 密钥,请使用 DuckDuckGo:
# tools = [DuckDuckGoSearchRun(rate_limiter=rate_limiter)]
tools = [TavilySearchResults(max_results=5, rate_limiter=rate_limiter)]
agent = create_agent(gpt_3_5_turbo, tools=tools, system_prompt=instructions)
模拟生产数据
现在让我们模拟一些生产数据:
fake_production_inputs = [
"Alan turing's early childhood",
"Economic impacts of the European Union",
"Underrated philosophers",
"History of the Roxie theater in San Francisco",
"ELI5: gravitational waves",
"The arguments for and against a parliamentary system",
"Pivotal moments in music history",
"Big ideas in programming languages",
"Big questions in biology",
"The relationship between math and reality",
"What makes someone funny",
]
agent.batch(
[{"messages": [{"role": "user", "content": content}]} for content in fake_production_inputs],
)
将生产追踪转换为实验
第一步是基于生产输入生成数据集。然后复制所有追踪作为基线实验。
选择要回测的运行
您可以使用 list_runs 的 filter 参数选择要回测的运行。filter 参数使用 LangSmith 追踪查询语法 来选择运行。
from datetime import datetime, timedelta, timezone
from uuid import uuid4
from langsmith import Client
from langsmith.beta import convert_runs_to_test
# 获取我们要转换为数据集/实验的运行
client = Client()
# 我们如何采样要包含在数据集中的运行
end_time = datetime.now(tz=timezone.utc)
start_time = end_time - timedelta(days=1)
run_filter = f'and(gt(start_time, "{start_time.isoformat()}"), lt(end_time, "{end_time.isoformat()}"))'
prod_runs = list(
client.list_runs(
project_name=project_name,
is_root=True,
filter=run_filter,
)
)
将运行转换为实验
convert_runs_to_test 是一个函数,它接受一些运行并执行以下操作:
- 输入(以及可选的输出)作为示例保存到数据集中。
- 输入和输出存储为实验,就像您运行了
evaluate 函数并获得了这些输出一样。
# 我们要创建的数据集名称
dataset_name = f'{project_name}-backtesting {start_time.strftime("%Y-%m-%d")}-{end_time.strftime("%Y-%m-%d")}'
# 我们要从历史运行中创建的实验名称
baseline_experiment_name = f"prod-baseline-gpt-3.5-turbo-{str(uuid4())[:4]}"
# 这将运行转换为数据集 + 实验
convert_runs_to_test(
prod_runs,
# 结果数据集的名称
dataset_name=dataset_name,
# 是否将运行输出作为参考/真实答案包含在内
include_outputs=False,
# 是否在结果实验中包含完整追踪
# (默认仅包含根运行)
load_child_runs=True,
# 实验名称,以便之后可以对其应用评估器
test_project_name=baseline_experiment_name
)
对新系统进行基准测试
现在我们可以开始将生产运行与新系统进行基准测试的过程。
定义评估器
首先,让我们定义用于比较两个系统的评估器。请注意,我们没有参考输出,因此需要设计仅需要实际输出的评估指标。
import emoji
from pydantic import BaseModel, Field
from langchain_core.messages import convert_to_openai_messages
class Grade(BaseModel):
"""评估响应是否得到某些上下文的支持。"""
grounded: bool = Field(..., description="响应的大部分是否得到检索到的上下文的支持?")
grounded_instructions = f"""您向某人提供了一些上下文信息,并要求他们撰写基于该上下文的陈述。
评估他们的响应是否完全得到您提供的上下文的支持。\
如果他们的陈述的任何有意义的部分没有直接得到您提供的上下文的支持,那么他们的响应就是不基于上下文的。\
否则就是基于上下文的。"""
grounded_model = init_chat_model(model="gpt-4.1").with_structured_output(Grade)
def lt_280_chars(outputs: dict) -> bool:
messages = convert_to_openai_messages(outputs["messages"])
return len(messages[-1]['content']) <= 280
def gte_3_emojis(outputs: dict) -> bool:
messages = convert_to_openai_messages(outputs["messages"])
return len(emoji.emoji_list(messages[-1]['content'])) >= 3
async def is_grounded(outputs: dict) -> bool:
context = ""
messages = convert_to_openai_messages(outputs["messages"])
for message in messages:
if message["role"] == "tool":
# 工具消息输出是 Tavily/DuckDuckGo 工具返回的结果
context += "\n\n" + message["content"]
tweet = messages[-1]["content"]
user = f"""提供的上下文:
{context}
给出的响应:
{tweet}"""
grade = await grounded_model.ainvoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": user}
])
return grade.grounded
评估基线
现在,让我们针对基线实验运行评估器。
baseline_results = await client.aevaluate(
baseline_experiment_name,
evaluators=[lt_280_chars, gte_3_emojis, is_grounded],
)
# 如果安装了 pandas,可以轻松将结果作为 DataFrame 查看:
# baseline_results.to_pandas()
定义并评估新系统
现在,让我们定义并评估我们的新系统。在此示例中,我们的新系统将与旧系统相同,但将使用 GPT-4o 而不是 GPT-3.5。由于我们已使模型可配置,我们只需更新传递给代理的默认配置:
candidate_results = await client.aevaluate(
agent.with_config(model="gpt-4.1"),
data=dataset_name,
evaluators=[lt_280_chars, gte_3_emojis, is_grounded],
experiment_prefix="candidate-gpt-4.1",
)
# 如果安装了 pandas,可以轻松将结果作为 DataFrame 查看:
# candidate_results.to_pandas()
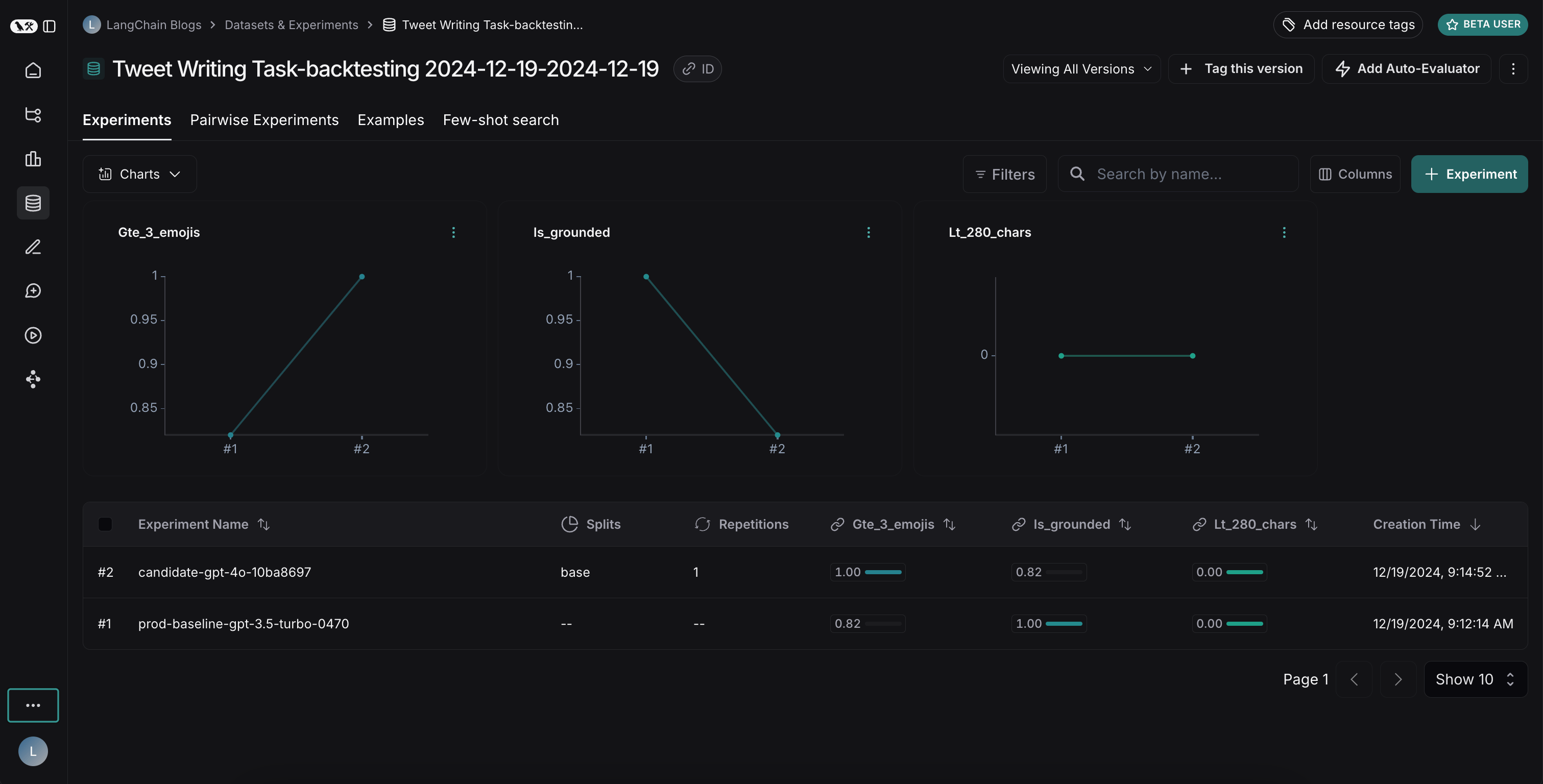
比较结果
运行两个实验后,您可以在数据集中查看它们:
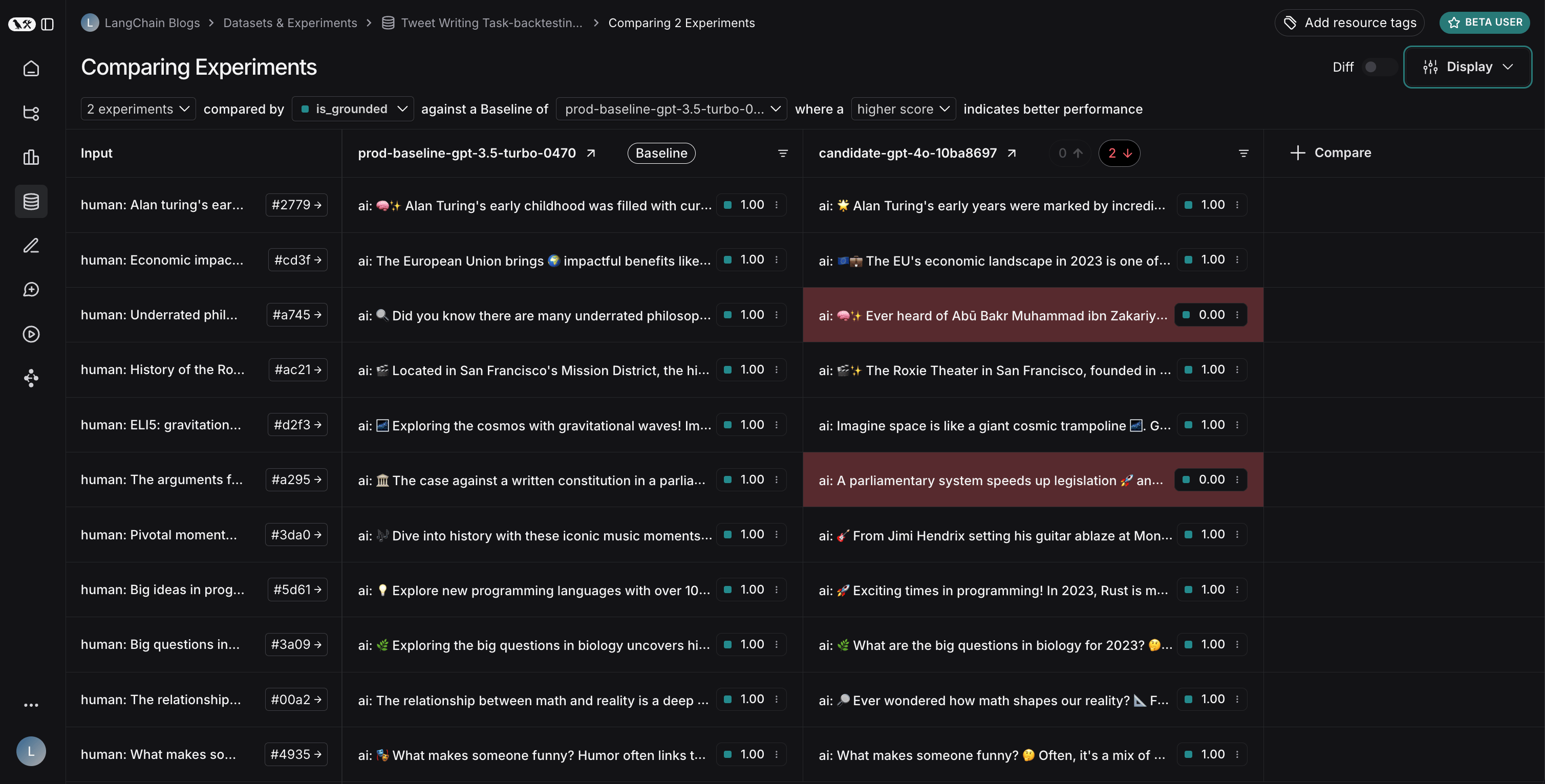
 结果揭示了两个模型之间有趣的权衡:
结果揭示了两个模型之间有趣的权衡:
- GPT-4o 在遵循格式规则方面表现更好,始终包含请求数量的表情符号
- 然而,GPT-4o 在基于提供的搜索结果方面可靠性较低
为了说明基于上下文的问题:在此示例运行中,GPT-4o 包含了关于 Abū Bakr Muhammad ibn Zakariyyā al-Rāzī 医学贡献的事实,但这些事实并未出现在搜索结果中。这表明它是从其内部知识中提取信息,而不是严格使用提供的信息。
这次回测练习表明,虽然 GPT-4o 通常被认为是一个更强大的模型,但简单地升级到它并不会改善我们的推文撰写器。要有效使用 GPT-4o,我们需要:
- 优化我们的提示,更加强调仅使用提供的信息
- 或者修改我们的系统架构,以更好地约束模型的输出
这一见解展示了回测的价值——它帮助我们在部署前识别潜在问题。