

- 如何创建测试数据集
- 如何在这些数据集上运行您的 RAG 应用
- 如何使用不同的评估指标来衡量应用性能
概述
典型的 RAG 评估工作流程包含三个主要步骤:- 创建包含问题及其预期答案的数据集
- 在这些问题上运行您的 RAG 应用
-
使用评估器来衡量应用的表现,考察因素包括:
- 答案相关性
- 答案准确性
- 检索质量
环境设置
环境
首先,让我们设置环境变量:import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = "您的 LANGSMITH API 密钥"
os.environ["OPENAI_API_KEY"] = "您的 OPENAI API 密钥"
process.env.LANGSMITH_TRACING = "true";
process.env.LANGSMITH_API_KEY = "您的 LANGSMITH API 密钥";
process.env.OPENAI_API_KEY = "您的 OPENAI API 密钥";
pip install -U langsmith langchain[openai] langchain-community
yarn add langsmith langchain @langchain/community @langchain/openai
应用
虽然本教程使用 LangChain,但这里演示的评估技术和 LangSmith 功能适用于任何框架。请随意使用您偏好的工具和库。
- 索引:将 Lilian Weng 的几篇博客文章分块并索引到向量存储中
- 检索:根据用户问题检索这些文本块
- 生成:将问题和检索到的文档传递给 LLM。
索引与检索
首先,让我们加载要为其构建聊天机器人的博客文章并对其进行索引。from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 要加载文档的 URL 列表
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# 从 URL 加载文档
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# 使用指定的块大小和重叠度初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# 将文档分割成块
doc_splits = text_splitter.split_documents(docs_list)
# 使用 OpenAIEmbeddings 将文档块添加到“向量存储”中
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
# 使用 langchain,我们可以轻松地将任何向量存储转换为检索组件:
retriever = vectorstore.as_retriever(k=6)
import { OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
import { BrowserbaseLoader } from "@langchain/community/document_loaders/web/browserbase";
import { RecursiveCharacterTextSplitter } from "@langchain/text_splitters";
// 要加载文档的 URL 列表
const urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
const loader = new BrowserbaseLoader(urls, {
textContent: true,
});
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000, chunkOverlap: 200
});
const allSplits = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large"
});
const vectorStore = new MemoryVectorStore(embeddings); // 索引块
await vectorStore.addDocuments(allSplits)
生成
我们现在可以定义生成流程。from langchain_openai import ChatOpenAI
from langsmith import traceable
llm = ChatOpenAI(model="gpt-4.1", temperature=1)
# 添加装饰器,以便此函数在 LangSmith 中被追踪
@traceable()
def rag_bot(question: str) -> dict:
# LangChain 检索器将被自动追踪
docs = retriever.invoke(question)
docs_string = "".join(doc.page_content for doc in docs)
instructions = f"""您是一个乐于助人的助手,擅长分析源信息并回答问题。
使用以下源文档来回答用户的问题。
如果您不知道答案,只需说您不知道。
最多使用三个句子,保持答案简洁。
文档:
{docs_string}"""
# langchain ChatModel 将被自动追踪
ai_msg = llm.invoke([
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
)
return {"answer": ai_msg.content, "documents": docs}
import { ChatOpenAI } from "@langchain/openai";
import { traceable } from "langsmith/traceable";
const llm = new ChatOpenAI({
model: "gpt-4.1",
temperature: 1,
})
// 添加装饰器,以便此函数在 LangSmith 中被追踪
const ragBot = traceable(
async (question: string) => {
// LangChain 检索器将被自动追踪
const retrievedDocs = await vectorStore.similaritySearch(question);
const docsContent = retrievedDocs.map((doc) => doc.pageContent).join("");
const instructions = `您是一个乐于助人的助手,擅长分析源信息并回答问题
使用以下源文档来回答用户的问题。
如果您不知道答案,只需说您不知道。
最多使用三个句子,保持答案简洁。
文档:
${docsContent}`;
const aiMsg = await llm.invoke([
{
role: "system",
content: instructions
},
{
role: "user",
content: question
}
])
return {"answer": aiMsg.content, "documents": retrievedDocs}
}
)
数据集
现在我们有了应用,让我们构建一个数据集来评估它。在本例中,我们的数据集将非常简单:我们将包含示例问题和参考答案。from langsmith import Client
client = Client()
# 定义数据集的示例
examples = [
{
"inputs": {"question": "ReAct 代理如何使用自我反思?"},
"outputs": {"answer": "ReAct 整合了推理和行动,执行操作——例如像 Wikipedia 搜索 API 这样的工具——然后观察/推理工具的输出。"},
},
{
"inputs": {"question": "少样本提示可能产生哪些类型的偏差?"},
"outputs": {"answer": "少样本提示可能产生的偏差包括 (1) 多数标签偏差,(2) 近因偏差,以及 (3) 常见词元偏差。"},
},
{
"inputs": {"question": "对抗性攻击有哪五种类型?"},
"outputs": {"answer": "五种对抗性攻击类型是 (1) 词元操纵,(2) 基于梯度的攻击,(3) 越狱提示,(4) 人工红队测试,(5) 模型红队测试。"},
},
]
# 在 LangSmith 中创建数据集和示例
dataset_name = "Lilian Weng 博客问答"
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
import { Client } from "langsmith";
const client = new Client();
// 定义数据集的示例
const examples = [
[
"ReAct 代理如何使用自我反思?",
"ReAct 整合了推理和行动,执行操作——例如像 Wikipedia 搜索 API 这样的工具——然后观察/推理工具的输出。",
],
[
"少样本提示可能产生哪些类型的偏差?",
"少样本提示可能产生的偏差包括 (1) 多数标签偏差,(2) 近因偏差,以及 (3) 常见词元偏差。",
],
[
"对抗性攻击有哪五种类型?",
"五种对抗性攻击类型是 (1) 词元操纵,(2) 基于梯度的攻击,(3) 越狱提示,(4) 人工红队测试,(5) 模型红队测试。",
]
]
const [inputs, outputs] = examples.reduce<[Array<{ input: string }>, Array<{ outputs: string }>]>(
([inputs, outputs], item) => [
[...inputs, { input: item[0] }],
[...outputs, { outputs: item[1] }],
],
[[], []]
);
const datasetName = "Lilian Weng 博客问答";
const dataset = await client.createDataset(datasetName);
await client.createExamples({ inputs, outputs, datasetId: dataset.id })
评估器
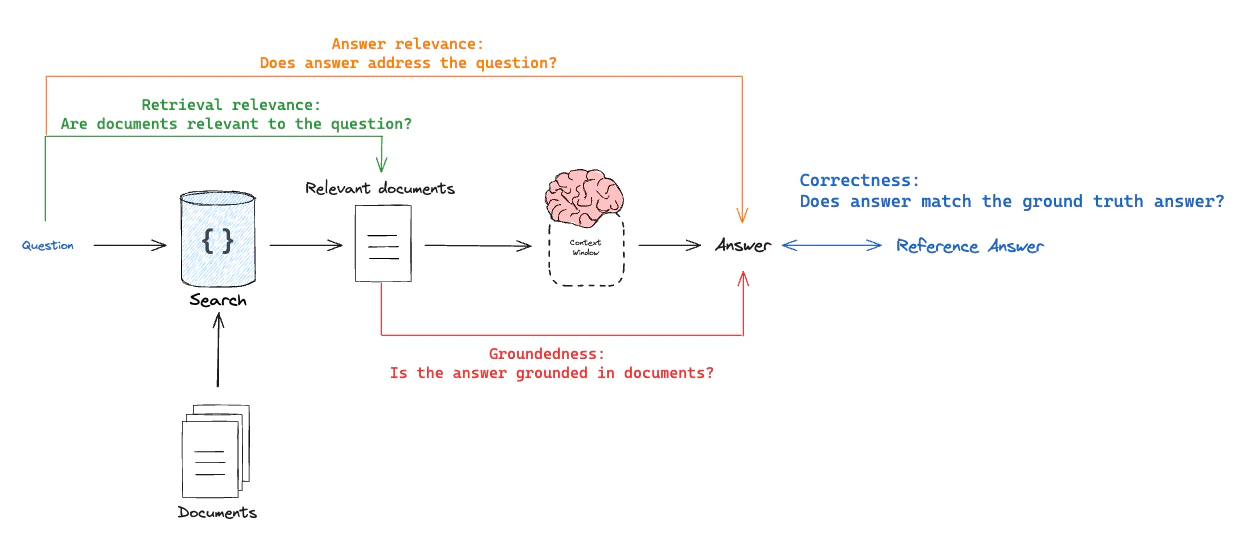
思考不同类型 RAG 评估器的一种方式是将其视为“被评估对象”与“评估参照物”组成的元组:-
正确性:响应 vs 参考答案
目标:衡量“RAG 链的答案相对于真实答案的相似度/正确程度”模式:需要通过数据集提供的真实(参考)答案评估器:使用 LLM 作为评判者来评估答案正确性。
-
相关性:响应 vs 输入
目标:衡量“生成的响应对初始用户输入的解决程度”模式:不需要参考答案,因为它将比较答案与输入问题评估器:使用 LLM 作为评判者来评估答案相关性、有用性等。
-
** groundedness(基于事实性)**:响应 vs 检索到的文档
目标:衡量“生成的响应与检索到的上下文的一致程度”模式:不需要参考答案,因为它将比较答案与检索到的上下文评估器:使用 LLM 作为评判者来评估忠实度、幻觉等。
-
检索相关性:检索到的文档 vs 输入
目标:衡量“我的检索结果对此查询的相关程度”模式:不需要参考答案,因为它将比较问题与检索到的上下文评估器:使用 LLM 作为评判者来评估相关性
正确性:响应 vs 参考答案
from typing_extensions import Annotated, TypedDict
# 评分输出模式
class CorrectnessGrade(TypedDict):
# 注意,字段定义的顺序是模型生成它们的顺序。
# 将解释放在响应之前很有用,因为这迫使模型在生成最终响应之前进行思考:
explanation: Annotated[str, ..., "解释您评分的推理过程"]
correct: Annotated[bool, ..., "如果答案正确则为 True,否则为 False。"]
# 评分提示
correctness_instructions = """您是一位给测验评分的老师。您将收到一个问题、真实(正确)答案和学生答案。请遵循以下评分标准:
(1) 仅根据学生答案相对于真实答案的事实准确性来评分。(2) 确保学生答案不包含任何相互矛盾的陈述。
(3) 如果学生答案包含的信息多于真实答案,只要其相对于真实答案在事实上是准确的,也是可以的。
正确性:
正确性值为 True 表示学生答案符合所有标准。
正确性值为 False 表示学生答案不符合所有标准。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。"""
# 评分 LLM
grader_llm = ChatOpenAI(model="gpt-4.1", temperature=0).with_structured_output(
CorrectnessGrade, method="json_schema", strict=True
)
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""用于 RAG 答案准确性的评估器"""
answers = f"""\
问题:{inputs['question']}
真实答案:{reference_outputs['answer']}
学生答案:{outputs['answer']}"""
# 运行评估器
grade = grader_llm.invoke([
{"role": "system", "content": correctness_instructions},
{"role": "user", "content": answers}
])
return grade["correct"]
import type { EvaluationResult } from "langsmith/evaluation";
import { z } from "zod";
// 评分提示
const correctnessInstructions = `您是一位给测验评分的老师。您将收到一个问题、真实(正确)答案和学生答案。请遵循以下评分标准:
(1) 仅根据学生答案相对于真实答案的事实准确性来评分。(2) 确保学生答案不包含任何相互矛盾的陈述。
(3) 如果学生答案包含的信息多于真实答案,只要其相对于真实答案在事实上是准确的,也是可以的。
正确性:
正确性值为 True 表示学生答案符合所有标准。
正确性值为 False 表示学生答案不符合所有标准。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。`
const graderLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释您评分的推理过程"),
correct: z
.boolean()
.describe("如果答案正确则为 True,否则为 False。")
})
.describe("参考答案与生成答案的正确性评分。")
);
async function correctness({
inputs,
outputs,
referenceOutputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
referenceOutputs?: Record<string, any>;
}): Promise<EvaluationResult> => {
const answer = `问题:${inputs.question}
真实答案:${referenceOutputs.answer}
学生答案:${outputs.answer}`
// 运行评估器
const grade = graderLLM.invoke([{role: "system", content: correctnessInstructions}, {role: "user", content: answer}])
return grade.score;
};
相关性:响应 vs 输入
流程与上述类似,但我们只查看inputs 和 outputs,不需要 reference_outputs。没有参考答案,我们无法评估准确性,但仍然可以评估相关性——即模型是否解决了用户的问题。
# 评分输出模式
class RelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "解释您评分的推理过程"]
relevant: Annotated[
bool, ..., "给出答案是否解决问题的评分"
]
# 评分提示
relevance_instructions = """您是一位给测验评分的老师。您将收到一个问题和一个学生答案。请遵循以下评分标准:
(1) 确保学生答案简洁且与问题相关
(2) 确保学生答案有助于回答问题
相关性:
相关性值为 True 表示学生答案符合所有标准。
相关性值为 False 表示学生答案不符合所有标准。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。"""
# 评分 LLM
relevance_llm = ChatOpenAI(model="gpt-4.1", temperature=0).with_structured_output(
RelevanceGrade, method="json_schema", strict=True
)
# 评估器
def relevance(inputs: dict, outputs: dict) -> bool:
"""用于 RAG 答案有用性的简单评估器。"""
answer = f"问题:{inputs['question']}\n学生答案:{outputs['answer']}"
grade = relevance_llm.invoke([
{"role": "system", "content": relevance_instructions},
{"role": "user", "content": answer}
])
return grade["relevant"]
import type { EvaluationResult } from "langsmith/evaluation";
import { z } from "zod";
// 评分提示
const relevanceInstructions = `您是一位给测验评分的老师。您将收到一个问题和一个学生答案。请遵循以下评分标准:
(1) 确保学生答案简洁且与问题相关
(2) 确保学生答案有助于回答问题
相关性:
相关性值为 True 表示学生答案符合所有标准。
相关性值为 False 表示学生答案不符合所有标准。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。`
const relevanceLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释您评分的推理过程"),
relevant: z
.boolean()
.describe("给出答案是否解决问题的评分")
})
.describe("生成答案与输入问题的相关性评分。")
);
async function relevance({
inputs,
outputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
}): Promise<EvaluationResult> => {
const answer = `问题:${inputs.question}
学生答案:${outputs.answer}`
// 运行评估器
const grade = relevanceLLM.invoke([{role: "system", content: relevanceInstructions}, {role: "user", content: answer}])
return grade.relevant;
};
Groundedness(基于事实性):响应 vs 检索到的文档
另一种无需参考答案即可评估响应的有用方法是检查响应是否由检索到的文档所证明(或“基于”)。# 评分输出模式
class GroundedGrade(TypedDict):
explanation: Annotated[str, ..., "解释您评分的推理过程"]
grounded: Annotated[
bool, ..., "给出答案是否偏离文档产生幻觉的评分"
]
# 评分提示
grounded_instructions = """您是一位给测验评分的老师。您将收到一些事实和一个学生答案。请遵循以下评分标准:
(1) 确保学生答案基于这些事实。(2) 确保学生答案不包含超出事实范围的“幻觉”信息。
Grounded(基于事实):
Grounded 值为 True 表示学生答案符合所有标准。
Grounded 值为 False 表示学生答案不符合所有标准。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。"""
# 评分 LLM
grounded_llm = ChatOpenAI(model="gpt-4.1", temperature=0).with_structured_output(
GroundedGrade, method="json_schema", strict=True
)
# 评估器
def groundedness(inputs: dict, outputs: dict) -> bool:
"""用于 RAG 答案基于事实性的简单评估器。"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"事实:{doc_string}\n学生答案:{outputs['answer']}"
grade = grounded_llm.invoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": answer}
])
return grade["grounded"]
import type { EvaluationResult } from "langsmith/evaluation";
import { z } from "zod";
// 评分提示
const groundedInstructions = `您是一位给测验评分的老师。您将收到一些事实和一个学生答案。请遵循以下评分标准:
(1) 确保学生答案基于这些事实。(2) 确保学生答案不包含超出事实范围的“幻觉”信息。
Grounded(基于事实):
Grounded 值为 True 表示学生答案符合所有标准。
Grounded 值为 False 表示学生答案不符合所有标准。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。`
const groundedLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释您评分的推理过程"),
grounded: z
.boolean()
.describe("给出答案是否偏离文档产生幻觉的评分")
})
.describe("答案相对于检索文档的基于事实性评分。")
);
async function grounded({
inputs,
outputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
}): Promise<EvaluationResult> => {
const docString = outputs.documents.map((doc) => doc.pageContent).join("");
const answer = `事实:${docString}
学生答案:${outputs.answer}`
// 运行评估器
const grade = groundedLLM.invoke([{role: "system", content: groundedInstructions}, {role: "user", content: answer}])
return grade.grounded;
};
检索相关性:检索到的文档 vs 输入
# 评分输出模式
class RetrievalRelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "解释您评分的推理过程"]
relevant: Annotated[
bool,
...,
"如果检索到的文档与问题相关则为 True,否则为 False",
]
# 评分提示
retrieval_relevance_instructions = """您是一位给测验评分的老师。您将收到一个问题以及学生提供的一组事实。请遵循以下评分标准:
(1) 您的目标是识别与问题完全无关的事实
(2) 如果事实包含与问题相关的任何关键词或语义含义,则认为它们相关
(3) 只要满足 (2),事实中包含一些与问题无关的信息也是可以的
相关性:
相关性值为 True 表示事实包含与问题相关的任何关键词或语义含义,因此是相关的。
相关性值为 False 表示事实与问题完全无关。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。"""
# 评分 LLM
retrieval_relevance_llm = ChatOpenAI(
model="gpt-4.1", temperature=0
).with_structured_output(RetrievalRelevanceGrade, method="json_schema", strict=True)
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
"""用于文档相关性的评估器"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"事实:{doc_string}\n问题:{inputs['question']}"
# 运行评估器
grade = retrieval_relevance_llm.invoke([
{"role": "system", "content": retrieval_relevance_instructions},
{"role": "user", "content": answer}
])
return grade["relevant"]
import type { EvaluationResult } from "langsmith/evaluation";
import { z } from "zod";
// 评分提示
const retrievalRelevanceInstructions = `您是一位给测验评分的老师。您将收到一个问题以及学生提供的一组事实。请遵循以下评分标准:
(1) 您的目标是识别与问题完全无关的事实
(2) 如果事实包含与问题相关的任何关键词或语义含义,则认为它们相关
(3) 只要满足 (2),事实中包含一些与问题无关的信息也是可以的
相关性:
相关性值为 True 表示事实包含与问题相关的任何关键词或语义含义,因此是相关的。
相关性值为 False 表示事实与问题完全无关。
以逐步的方式解释您的推理,以确保您的推理和结论是正确的。避免在一开始就直接陈述正确答案。`
const retrievalRelevanceLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释您评分的推理过程"),
relevant: z
.boolean()
.describe("如果检索到的文档与问题相关则为 True,否则为 False")
})
.describe("检索到的文档相对于问题的检索相关性评分。")
);
async function retrievalRelevance({
inputs,
outputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
}): Promise<EvaluationResult> => {
const docString = outputs.documents.map((doc) => doc.pageContent).join("");
const answer = `事实:${docString}
问题:${inputs.question}`
// 运行评估器
const grade = retrievalRelevanceLLM.invoke([{role: "system", content: retrievalRelevanceInstructions}, {role: "user", content: answer}])
return grade.relevant;
};
运行评估
我们现在可以使用所有不同的评估器来启动评估任务。def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[correctness, groundedness, relevance, retrieval_relevance],
experiment_prefix="rag-doc-relevance",
metadata={"version": "LCEL context, gpt-4-0125-preview"},
)
# 如果您安装了 pandas,可以在本地将结果作为数据框查看
# experiment_results.to_pandas()
import { evaluate } from "langsmith/evaluation";
const targetFunc = (inputs: Record<string, any>) => {
return ragBot(inputs.question)
};
const experimentResults = await evaluate(targetFunc, {
data: datasetName,
evaluators: [correctness, groundedness, relevance, retrievalRelevance],
experimentPrefix: "rag-doc-relevance",
metadata: {version: "LCEL context, gpt-4-0125-preview"},
});
以下是包含上述所有代码的整合脚本:
以下是包含上述所有代码的整合脚本:
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langsmith import Client, traceable
from typing_extensions import Annotated, TypedDict
# 要加载文档的 URL 列表
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# 从 URL 加载文档
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# 初始化文本分割器,指定块大小和重叠量
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# 将文档分割成块
doc_splits = text_splitter.split_documents(docs_list)
# 使用 OpenAIEmbeddings 将文档块添加到"向量存储"中
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
# 使用 langchain 可以轻松地将任何向量存储转换为检索组件:
retriever = vectorstore.as_retriever(k=6)
llm = ChatOpenAI(model="gpt-4.1", temperature=1)
# 添加装饰器,使该函数在 LangSmith 中被追踪
@traceable()
def rag_bot(question: str) -> dict:
# langchain 检索器将被自动追踪
docs = retriever.invoke(question)
docs_string = "".join(doc.page_content for doc in docs)
instructions = f"""你是一位乐于助人的助手,擅长分析源信息并回答问题。
请使用以下源文档来回答用户的问题。
如果你不知道答案,就说你不知道。
最多使用三句话,保持答案简洁。
文档:
{docs_string}"""
# langchain 聊天模型将被自动追踪
ai_msg = llm.invoke([
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
)
return {"answer": ai_msg.content, "documents": docs}
client = Client()
# 为数据集定义示例
examples = [
{
"inputs": {"question": "ReAct 代理如何使用自我反思?"},
"outputs": {"answer": "ReAct 整合了推理和行动,执行诸如维基百科搜索 API 等工具的操作,然后观察/推理工具的输出。"},
},
{
"inputs": {"question": "少样本提示可能产生哪些类型的偏差?"},
"outputs": {"answer": "少样本提示可能产生的偏差包括 (1) 多数标签偏差、(2) 近因偏差和 (3) 常见词元偏差。"},
},
{
"inputs": {"question": "五种对抗性攻击的类型是什么?"},
"outputs": {"answer": "五种对抗性攻击类型是 (1) 词元操纵、(2) 基于梯度的攻击、(3) 越狱提示、(4) 人工红队测试、(5) 模型红队测试。"},
},
]
# 在 LangSmith 中创建数据集和示例
dataset_name = "Lilian Weng 博客问答"
if not client.has_dataset(dataset_name=dataset_name):
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
# 评分输出模式
class CorrectnessGrade(TypedDict):
# 注意,字段定义的顺序是模型生成它们的顺序。
# 在响应之前放置解释很有用,因为它迫使模型在生成最终响应之前进行思考:
explanation: Annotated[str, ..., "解释你给出该分数的理由"]
correct: Annotated[bool, ..., "如果答案正确则为 True,否则为 False。"]
# 评分提示
correctness_instructions = """你是一位批改测验的教师。你会收到一个问题、正确答案(标准答案)和学生答案。请遵循以下评分标准:
(1) 仅根据学生答案相对于标准答案的事实准确性来评分。
(2) 确保学生答案不包含任何相互矛盾的陈述。
(3) 如果学生答案包含的信息多于标准答案,只要相对于标准答案在事实上是准确的,也是可以的。
正确性:
正确性值为 True 表示学生答案满足所有标准。
正确性值为 False 表示学生答案不满足所有标准。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。"""
# 评分 LLM
grader_llm = ChatOpenAI(model="gpt-4.1", temperature=0).with_structured_output(
CorrectnessGrade, method="json_schema", strict=True
)
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""RAG 答案准确性的评估器"""
answers = f"""\
问题:{inputs['question']}
标准答案:{reference_outputs['answer']}
学生答案:{outputs['answer']}"""
# 运行评估器
grade = grader_llm.invoke([
{"role": "system", "content": correctness_instructions},
{"role": "user", "content": answers},
]
)
return grade["correct"]
# 评分输出模式
class RelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "解释你给出该分数的理由"]
relevant: Annotated[
bool, ..., "给出答案是否针对问题的评分"
]
# 评分提示
relevance_instructions = """你是一位批改测验的教师。你会收到一个问题和学生答案。请遵循以下评分标准:
(1) 确保学生答案简洁且与问题相关
(2) 确保学生答案有助于回答问题
相关性:
相关性值为 True 表示学生答案满足所有标准。
相关性值为 False 表示学生答案不满足所有标准。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。"""
# 评分 LLM
relevance_llm = ChatOpenAI(model="gpt-4.1", temperature=0).with_structured_output(
RelevanceGrade, method="json_schema", strict=True
)
# 评估器
def relevance(inputs: dict, outputs: dict) -> bool:
"""RAG 答案有用性的简单评估器。"""
answer = f"问题:{inputs['question']}\n学生答案:{outputs['answer']}"
grade = relevance_llm.invoke([
{"role": "system", "content": relevance_instructions},
{"role": "user", "content": answer},
]
)
return grade["relevant"]
# 评分输出模式
class GroundedGrade(TypedDict):
explanation: Annotated[str, ..., "解释你给出该分数的理由"]
grounded: Annotated[
bool, ..., "给出答案是否基于文档(即没有幻觉)的评分"
]
# 评分提示
grounded_instructions = """你是一位批改测验的教师。你会收到事实依据和学生答案。请遵循以下评分标准:
(1) 确保学生答案基于事实依据。
(2) 确保学生答案不包含超出事实依据范围的"幻觉"信息。
基于依据:
基于依据值为 True 表示学生答案满足所有标准。
基于依据值为 False 表示学生答案不满足所有标准。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。"""
# 评分 LLM
grounded_llm = ChatOpenAI(model="gpt-4.1", temperature=0).with_structured_output(
GroundedGrade, method="json_schema", strict=True
)
# 评估器
def groundedness(inputs: dict, outputs: dict) -> bool:
"""RAG 答案基于依据程度的简单评估器。"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"事实依据:{doc_string}\n学生答案:{outputs['answer']}"
grade = grounded_llm.invoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": answer},
]
)
return grade["grounded"]
# 评分输出模式
class RetrievalRelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "解释你给出该分数的理由"]
relevant: Annotated[
bool,
...,
"如果检索到的文档与问题相关则为 True,否则为 False",
]
# 评分提示
retrieval_relevance_instructions = """你是一位批改测验的教师。你会收到一个问题以及学生提供的一组事实依据。请遵循以下评分标准:
(1) 你的目标是识别与问题完全无关的事实依据
(2) 如果事实依据包含与问题相关的任何关键词或语义含义,则认为它们相关
(3) 只要满足 (2),事实依据中包含一些与问题无关的信息也是可以的
相关性:
相关性值为 True 表示事实依据包含与问题相关的任何关键词或语义含义,因此是相关的。
相关性值为 False 表示事实依据与问题完全无关。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。"""
# 评分 LLM
retrieval_relevance_llm = ChatOpenAI(
model="gpt-4.1", temperature=0
).with_structured_output(RetrievalRelevanceGrade, method="json_schema", strict=True)
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
"""文档相关性的评估器"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"事实依据:{doc_string}\n问题:{inputs['question']}"
# 运行评估器
grade = retrieval_relevance_llm.invoke([
{"role": "system", "content": retrieval_relevance_instructions},
{"role": "user", "content": answer},
]
)
return grade["relevant"]
def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[correctness, groundedness, relevance, retrieval_relevance],
experiment_prefix="rag-doc-relevance",
metadata={"version": "LCEL context, gpt-4-0125-preview"},
)
# 如果安装了 pandas,可以在本地以 DataFrame 形式查看结果
# experiment_results.to_pandas()
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
import { BrowserbaseLoader } from "@langchain/community/document_loaders/web/browserbase";
import { traceable } from "langsmith/traceable";
import { Client } from "langsmith";
import { evaluate, type EvaluationResult } from "langsmith/evaluation";
import { z } from "zod";
// 要加载文档的 URL 列表
const urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
const loader = new BrowserbaseLoader(urls, {
textContent: true,
});
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000, chunkOverlap: 200
});
const allSplits = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large"
});
const vectorStore = new MemoryVectorStore(embeddings); // 索引块
await vectorStore.addDocuments(allSplits)
const llm = new ChatOpenAI({
model: "gpt-4.1",
temperature: 1,
})
// 添加装饰器,使该函数在 LangSmith 中被追踪
const ragBot = traceable(
async (question: string) => {
// LangChain 检索器将被自动追踪
const retrievedDocs = await vectorStore.similaritySearch(question);
const docsContent = retrievedDocs.map((doc) => doc.pageContent).join("");
const instructions = `你是一位乐于助人的助手,擅长分析源信息并回答问题。
请使用以下源文档来回答用户的问题。
如果你不知道答案,就说你不知道。
最多使用三句话,保持答案简洁。
文档:
${docsContent}`;
const aiMsg = await llm.invoke([
{
role: "system",
content: instructions
},
{
role: "user",
content: question
}
])
return {"answer": aiMsg.content, "documents": retrievedDocs}
}
)
const client = new Client();
// 为数据集定义示例
const examples = [
[
"ReAct 代理如何使用自我反思?",
"ReAct 整合了推理和行动,执行诸如维基百科搜索 API 等工具的操作,然后观察/推理工具的输出。",
],
[
"少样本提示可能产生哪些类型的偏差?",
"少样本提示可能产生的偏差包括 (1) 多数标签偏差、(2) 近因偏差和 (3) 常见词元偏差。",
],
[
"五种对抗性攻击的类型是什么?",
"五种对抗性攻击类型是 (1) 词元操纵、(2) 基于梯度的攻击、(3) 越狱提示、(4) 人工红队测试、(5) 模型红队测试。",
]
]
const [inputs, outputs] = examples.reduce<[Array<{ input: string }>, Array<{ outputs: string }>]>(
([inputs, outputs], item) => [
[...inputs, { input: item[0] }],
[...outputs, { outputs: item[1] }],
],
[[], []]
);
const datasetName = "Lilian Weng 博客问答";
const dataset = await client.createDataset(datasetName);
await client.createExamples({ inputs, outputs, datasetId: dataset.id })
// 评分提示
const correctnessInstructions = `你是一位批改测验的教师。你会收到一个问题、正确答案(标准答案)和学生答案。请遵循以下评分标准:
(1) 仅根据学生答案相对于标准答案的事实准确性来评分。
(2) 确保学生答案不包含任何相互矛盾的陈述。
(3) 如果学生答案包含的信息多于标准答案,只要相对于标准答案在事实上是准确的,也是可以的。
正确性:
正确性值为 True 表示学生答案满足所有标准。
正确性值为 False 表示学生答案不满足所有标准。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。`
const graderLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释你给出该分数的理由"),
correct: z
.boolean()
.describe("如果答案正确则为 True,否则为 False。")
})
.describe("参考答案与生成答案的正确性评分")
);
async function correctness({
inputs,
outputs,
referenceOutputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
referenceOutputs?: Record<string, any>;
}): Promise<EvaluationResult> => {
const answer = `问题:${inputs.question}
标准答案:${referenceOutputs.answer}
学生答案:${outputs.answer}`
// 运行评估器
const grade = graderLLM.invoke([{role: "system", content: correctnessInstructions}, {role: "user", content: answer}])
return grade.score;
};
// 评分提示
const relevanceInstructions = `你是一位批改测验的教师。你会收到一个问题和学生答案。请遵循以下评分标准:
(1) 确保学生答案简洁且与问题相关
(2) 确保学生答案有助于回答问题
相关性:
相关性值为 True 表示学生答案满足所有标准。
相关性值为 False 表示学生答案不满足所有标准。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。`
const relevanceLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释你给出该分数的理由"),
relevant: z
.boolean()
.describe("给出答案是否针对问题的评分")
})
.describe("生成答案相对于输入问题的相关性评分")
);
async function relevance({
inputs,
outputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
}): Promise<EvaluationResult> => {
const answer = `问题:${inputs.question}
学生答案:${outputs.answer}`
// 运行评估器
const grade = relevanceLLM.invoke([{role: "system", content: relevanceInstructions}, {role: "user", content: answer}])
return grade.relevant;
};
// 评分提示
const groundedInstructions = `你是一位批改测验的教师。你会收到事实依据和学生答案。请遵循以下评分标准:
(1) 确保学生答案基于事实依据。
(2) 确保学生答案不包含超出事实依据范围的"幻觉"信息。
基于依据:
基于依据值为 True 表示学生答案满足所有标准。
基于依据值为 False 表示学生答案不满足所有标准。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。`
const groundedLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释你给出该分数的理由"),
grounded: z
.boolean()
.describe("给出答案是否基于文档(即没有幻觉)的评分")
})
.describe("基于检索文档的答案的基于依据程度评分")
);
async function grounded({
inputs,
outputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
}): Promise<EvaluationResult> => {
const docString = outputs.documents.map((doc) => doc.pageContent).join("");
const answer = `事实依据:${docString}
学生答案:${outputs.answer}`
// 运行评估器
const grade = groundedLLM.invoke([{role: "system", content: groundedInstructions}, {role: "user", content: answer}])
return grade.grounded;
};
// 评分提示
const retrievalRelevanceInstructions = `你是一位批改测验的教师。你会收到一个问题以及学生提供的一组事实依据。请遵循以下评分标准:
(1) 你的目标是识别与问题完全无关的事实依据
(2) 如果事实依据包含与问题相关的任何关键词或语义含义,则认为它们相关
(3) 只要满足 (2),事实依据中包含一些与问题无关的信息也是可以的
相关性:
相关性值为 True 表示事实依据包含与问题相关的任何关键词或语义含义,因此是相关的。
相关性值为 False 表示事实依据与问题完全无关。
以逐步推理的方式解释你的理由,确保你的推理和结论正确。避免一开始就直接说出正确答案。`
const retrievalRelevanceLLM = new ChatOpenAI({
model: "gpt-4.1",
temperature: 0,
}).withStructuredOutput(
z
.object({
explanation: z
.string()
.describe("解释你给出该分数的理由"),
relevant: z
.boolean()
.describe("如果检索到的文档与问题相关则为 True,否则为 False")
})
.describe("检索到的文档相对于问题的检索相关性评分")
);
async function retrievalRelevance({
inputs,
outputs,
}: {
inputs: Record<string, any>;
outputs: Record<string, any>;
}): Promise<EvaluationResult> => {
const docString = outputs.documents.map((doc) => doc.pageContent).join("");
const answer = `事实依据:${docString}
问题:${inputs.question}`
// 运行评估器
const grade = retrievalRelevanceLLM.invoke([{role: "system", content: retrievalRelevanceInstructions}, {role: "user", content: answer}])
return grade.relevant;
};
const targetFunc = (inputs: Record<string, any>) => {
return ragBot(inputs.question)
};
const experimentResults = await evaluate(targetFunc, {
data: datasetName,
evaluators: [correctness, groundedness, relevance, retrievalRelevance],
experimentPrefix: "rag-doc-relevance",
metadata: {version: "LCEL context, gpt-4-0125-preview"},
});
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.